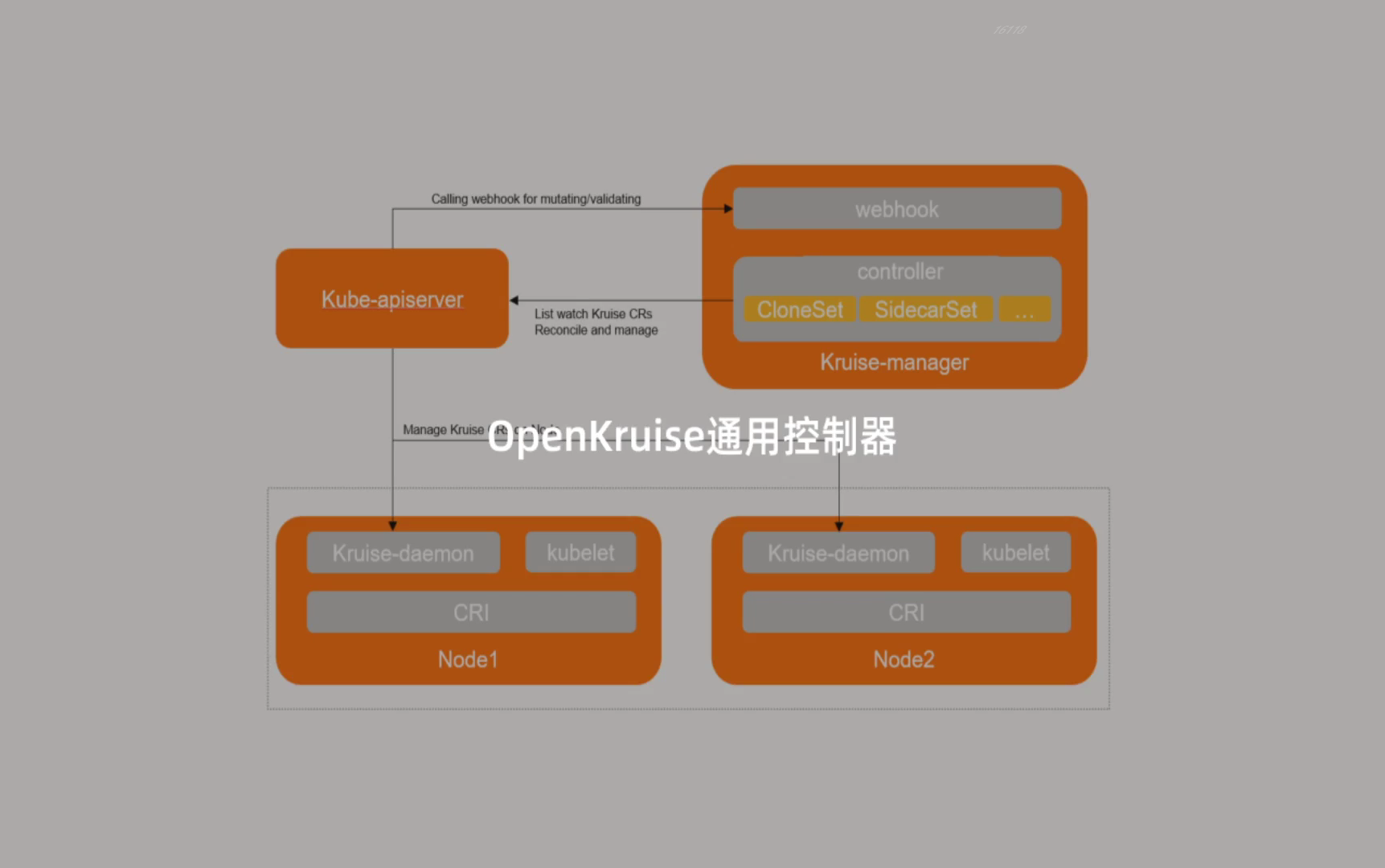
OpenKruise通用控制器
OpenKruise通用控制器
目录
[TOC]
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5
实验软件
链接:https://pan.baidu.com/s/1IH3renNk0kK7nErd_0YbaA?pwd=55wf
提取码:55wf
2022.3.11-50.OpenKruise通用控制器-实验软件
1、Advanced StatefulSet
该控制器在原生的 StatefulSet 基础上增强了发布能力,比如 maxUnavailable 并行发布、原地升级等,该对象的名称也是 StatefulSet,但是 apiVersion 是 apps.kruise.io/v1beta1,这个 CRD 的所有默认字段、默认行为与原生 StatefulSet 完全一致,除此之外还提供了一些 optional 字段来扩展增强的策略。因此,用户从原生 StatefulSet 迁移到 Advanced StatefulSet,只需要把 apiVersion 修改后提交即可:😂
- apiVersion: apps/v1
+ apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: sample
spec:
#...
1.最大不可用
💘 实验:最大不可用
Advanced StatefulSet 在滚动更新策略中新增了 maxUnavailable 来支持并行 Pod 发布,它会保证发布过程中最多有多少个 Pod 处于不可用状态。 注意,maxUnavailable 只能配合 podManagementPolicy 为 Parallel 来使用。
这个策略的效果和 Deployment 中的类似,但是可能会导致发布过程中的 order 顺序不能严格保证,如果不配置 maxUnavailable,它的默认值为 1,也就是和原生 StatefulSet 一样只能串行发布 Pod,即使把 podManagementPolicy 配置为 Parallel 也是这样。
- 比如现在我们创建一个如下所示的 Advanced StatefulSet:
#01-sts-RollingUpdate-Parallel.yaml
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: web
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 5
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 3
# partition: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx # @
spec:
containers:
- name: nginx
image: nginx
ports:
- name: web
containerPort: 80
- 直接创建该对象,由于对象名称也是 StatefulSet,所以不能直接用
get sts来获取了,要通过get asts获取:
$ kubectl apply -f 01-sts-RollingUpdate-Parallel.yaml
statefulset.apps.kruise.io/web created
[root@master1 ~]#kubectl get asts
NAME DESIRED CURRENT UPDATED READY AGE
web 5 5 5 5 24s
[root@master1 ~]#kubectl get po -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 33s
web-1 1/1 Running 0 33s
web-2 1/1 Running 0 32s
web-3 1/1 Running 0 32s
web-4 1/1 Running 0 32s
注意:查看advanced statsfulset的简写
[root@master1 ~]#kubectl get crd|grep kruise
advancedcronjobs.apps.kruise.io 2022-03-10T13:09:22Z
broadcastjobs.apps.kruise.io 2022-03-10T13:09:22Z
clonesets.apps.kruise.io 2022-03-10T13:09:22Z
containerrecreaterequests.apps.kruise.io 2022-03-10T13:09:22Z
daemonsets.apps.kruise.io 2022-03-10T13:09:22Z
imagepulljobs.apps.kruise.io 2022-03-10T13:09:22Z
nodeimages.apps.kruise.io 2022-03-10T13:09:22Z
podunavailablebudgets.policy.kruise.io 2022-03-10T13:09:22Z
resourcedistributions.apps.kruise.io 2022-03-10T13:09:22Z
sidecarsets.apps.kruise.io 2022-03-10T13:09:22Z
statefulsets.apps.kruise.io 2022-03-10T13:09:22Z
uniteddeployments.apps.kruise.io 2022-03-10T13:09:22Z
workloadspreads.apps.kruise.io 2022-03-10T13:09:22Z
[root@master1 ~]#kubectl get crd statefulsets.apps.kruise.io -oyaml|less

🍀 该应用下有五个 Pod,假设应用能容忍 3 个副本不可用,当我们把 StatefulSet 里的 Pod 升级版本的时候,可以通过以下步骤来做:
- 设置 maxUnavailable=3
- (可选) 如果需要灰度升级,设置 partition=4,Partition 默认的意思是 order 大于等于这个数值的 Pod 才会更新,在这里就只会更新 P4,即使我们设置了 maxUnavailable=3。
- 在 P4 升级完成后,把 partition 调整为 0,此时,控制器会同时升级 P1、P2、P3 三个 Pod。注意,如果是原生 StatefulSet,只能串行升级 P3、P2、P1。
- 一旦这三个 Pod 中有一个升级完成了,控制器会立即开始升级 P0。😥
🍀 比如这里我们把上面应用的镜像版本进行修改,更新后查看 Pod 状态,可以看到有3个 Pod 并行升级的:
修改镜像版本:
……
image: nginx:latest #修改为nginx:latest
……

#部署
$ kubectl apply -f 01-sts-RollingUpdate-Parallel.yaml
statefulset.apps.kruise.io/web configured
#查看
➜ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 2m41s
web-1 1/1 Running 0 2m41s
web-2 0/1 ContainerCreating 0 10s
web-3 0/1 ContainerCreating 0 10s
web-4 0/1 ContainerCreating 0 10s
[root@master1 ~]#kubectl get po -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 7m5s
web-1 1/1 Running 0 7m5s
web-2 0/1 ContainerCreating 0 4s
web-3 0/1 ContainerCreating 0 4s
web-4 0/1 ContainerCreating 0 4s
[root@master1 ~]#kubectl get po -l app=nginx
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 34s
web-1 1/1 Running 0 35s
web-2 1/1 Running 0 52s
web-3 1/1 Running 0 52s
web-4 1/1 Running 0 52s
[root@master1 ~]#kubectl describe po web-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 56s default-scheduler Successfully assigned default/web-0 to node2
Normal Pulling 55s kubelet Pulling image "nginx:latest"
Normal Pulled 26s kubelet Successfully pulled image "nginx:latest" in 29.501447739s
Normal Created 26s kubelet Created container nginx
Normal Started 25s kubelet Started container nginx
实验结束。😘
2.原地升级
💘 实验:原地升级
Advanced StatefulSet 增加了 podUpdatePolicy 来允许用户指定重建升级还是原地升级。此外还在原地升级中提供了 graceful period 选项,作为优雅原地升级的策略。用户如果配置了 gracePeriodSeconds 这个字段,控制器在原地升级的过程中会先把 Pod status 改为 not-ready,然后等一段时间(gracePeriodSeconds),最后再去修改 Pod spec 中的镜像版本。这样,就为 endpoints-controller 这些控制器留出了充足的时间来将 Pod 从 endpoints 端点列表中去除。
如果使用 InPlaceIfPossible 或 InPlaceOnly 策略,必须要增加一个 InPlaceUpdateReady readinessGate,用来在原地升级的时候控制器将 Pod 设置为 NotReady。
- 比如设置上面的应用为原地升级的方式:
#02-sts-RollingUpdate-InPlaceIfPossible.yaml
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
metadata:
name: web
namespace: default
spec:
serviceName: "nginx-headless"
podManagementPolicy: Parallel
replicas: 5
updateStrategy:
type: RollingUpdate
rollingUpdate:
podUpdatePolicy: InPlaceIfPossible # 尽可能执行原地升级
maxUnavailable: 3 # 允许并行更新,最大不可以实例数为3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
readinessGates:
- conditionType: InPlaceUpdateReady # 一个新的条件,可确保 Pod 在发生原地更新时保持在 NotReady 状态
containers:
- name: nginx
image: nginx:1.7.9 #这里把镜像修改为1.7.9
ports:
- name: web
containerPort: 80
这里我们设置 updateStrategy.rollingUpdate.podUpdatePolicy 为 InPlaceIfPossible 模式,表示尽可能使用原地升级的方式进行更新。此外在 Pod 模板中我们还添加了一个 readinessGates 属性,可以用来确保 Pod 在发生原地更新时保持在 NotReady 状态。
- 先来查看下当前pod信息(等会原地升级后,我们再核对下pod信息)
[root@master1 ~]#kubectl get po -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 56s 10.244.2.46 node2 <none> 2/2
web-1 1/1 Running 0 56s 10.244.1.162 node1 <none> 2/2
web-2 1/1 Running 0 56s 10.244.2.47 node2 <none> 2/2
web-3 1/1 Running 0 55s 10.244.1.163 node1 <none> 2/2
web-4 1/1 Running 0 55s 10.244.2.48 node2 <none> 2/2
- 比如我们现在使用上面资源清单更新应用,然后重新修改镜像的版本更新,则会进行原地升级:
$ kubectl apply -f 02-sts-RollingUpdate-InPlaceIfPossible.yaml
statefulset.apps.kruise.io/web configured
[root@master1 ~]#kubectl get po -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 106s 10.244.2.46 node2 <none> 1/2
web-1 1/1 Running 1 (17s ago) 106s 10.244.1.162 node1 <none> 2/2
web-2 1/1 Running 0 106s 10.244.2.47 node2 <none> 1/2
web-3 1/1 Running 1 (21s ago) 105s 10.244.1.163 node1 <none> 2/2
web-4 1/1 Running 1 (21s ago) 105s 10.244.2.48 node2 <none> 2/2
[root@master1 ~]#kubectl get po -l app=nginx -owide #可以看到采用原地升级后,pod ip和所在node节点信息都没发生改变
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 1 (50s ago) 2m34s 10.244.2.46 node2 <none> 2/2
web-1 1/1 Running 1 (65s ago) 2m34s 10.244.1.162 node1 <none> 2/2
web-2 1/1 Running 1 (69s ago) 2m34s 10.244.2.47 node2 <none> 2/2
web-3 1/1 Running 1 (69s ago) 2m33s 10.244.1.163 node1 <none> 2/2
web-4 1/1 Running 1 (69s ago) 2m33s 10.244.2.48 node2 <none> 2/2
[root@master1 ~]#kubectl describe asts web
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 3m32s statefulset-controller create Pod web-0 in StatefulSet web successful
Normal SuccessfulCreate 3m32s statefulset-controller create Pod web-1 in StatefulSet web successful
Normal SuccessfulCreate 3m32s statefulset-controller create Pod web-2 in StatefulSet web successful
Normal SuccessfulCreate 3m31s statefulset-controller create Pod web-3 in StatefulSet web successful
Normal SuccessfulCreate 3m31s statefulset-controller create Pod web-4 in StatefulSet web successful
Normal SuccessfulUpdatePodInPlace 2m7s statefulset-controller successfully update pod web-4 in-place(revision web-67975fc8c9)
Normal SuccessfulUpdatePodInPlace 2m7s statefulset-controller successfully update pod web-3 in-place(revision web-67975fc8c9)
Normal SuccessfulUpdatePodInPlace 2m7s statefulset-controller successfully update pod web-2 in-place(revision web-67975fc8c9)
Normal SuccessfulUpdatePodInPlace 2m3s statefulset-controller successfully update pod web-1 in-place(revision web-67975fc8c9)
Normal SuccessfulUpdatePodInPlace 108s statefulset-controller successfully update pod web-0 in-place(revision web-67975fc8c9)
-
同样的 Advanced StatefulSet 也支持原地升级自动预热。
-
也可以通过设置 paused 为 true 来暂停发布,不过控制器还是会做 replicas 数量管理:
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
spec:
# ...
updateStrategy:
rollingUpdate:
paused: true
- 另外 Advanced StatefulSet 还支持序号保留功能,通过在
reserveOrdinals字段中写入需要保留的序号,Advanced StatefulSet 会自动跳过创建这些序号的 Pod,如果 Pod 已经存在,则会被删除。
注意,
spec.replicas是期望运行的 Pod 数量,spec.reserveOrdinals是要跳过的序号。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
spec:
# ...
replicas: 4
reserveOrdinals:
- 1
比如上面的描述 replicas=4, reserveOrdinals=[1] 的 Advanced StatefulSet,表示实际运行的 Pod 序号为 [0,2,3,4]。
- 如果要把 Pod-3 做迁移并保留序号,则把 3 追加到 reserveOrdinals 列表中,控制器会把 Pod-3 删除并创建 Pod-5(此时运行中 Pod 为 [0,2,4,5])。
- 如果只想删除 Pod-3,则把 3 追加到 reserveOrdinals 列表并同时把 replicas 减一修改为 3。控制器会把 Pod-3 删除(此时运行中 Pod 为 [0,2,4])。
🍀 为了避免在一个新 Advanced StatefulSet 创建后有大量失败的 pod 被创建出来,从 Kruise v0.10.0 版本开始引入了在 scale strategy 中的 maxUnavailable 策略。
apiVersion: apps.kruise.io/v1beta1
kind: StatefulSet
spec:
# ...
replicas: 100
scaleStrategy:
maxUnavailable: 10% # percentage or absolute number
当这个字段被设置之后,Advanced StatefulSet 会保证创建 pod 之后不可用 pod 数量不超过这个限制值。比如说,上面这个 StatefulSet 一开始只会一次性创建 100*10%=10 个 pod,在此之后,每当一个 pod 变为 running、ready 状态后,才会再创建一个新 pod 出来。
注意,这个功能只允许在 podManagementPolicy 是
Parallel的 StatefulSet 中使用。
实验结束。😘
2、Advanced DaemonSet
这个控制器基于原生 DaemonSet 上增强了发布能力,比如灰度分批、按 Node label 选择、暂停、热升级等。同样的该对象的 Kind 名字也是 DaemonSet,只是 apiVersion 是 apps.kruise.io/v1alpha1,这个 CRD 的所有默认字段、默认行为与原生 DaemonSet 完全一致,除此之外还提供了一些 optional 字段来扩展增强的策略。
因此,用户从原生 DaemonSet 迁移到 Advanced DaemonSet,只需要把 apiVersion 修改后提交即可:
- apiVersion: apps/v1
+ apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: sample-ds
spec:
#...
1.升级
💘 实验:升级
Advanced DaemonSet 在 spec.updateStrategy.rollingUpdate 中有一个 rollingUpdateType 字段,标识了如何进行滚动升级:
Standard: 对于每个节点,控制器会先删除旧的 daemon Pod,再创建一个新 Pod,和原生 DaemonSet 行为一致。Surging: 对于每个 node,控制器会先创建一个新 Pod,等它 ready 之后再删除老 Pod。
🍀 创建如下所示的资源对象:
#03-daemonset-demo.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: nginx
namespace: default
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: Standard
selector:
matchLabels:
k8s-app: nginx
template:
metadata:
labels:
k8s-app: nginx
spec:
containers:
- image: nginx:1.7.9
name: nginx
ports:
- name: http
containerPort: 80
- 创建后需要通过
get daemon来获取该对象:
#部署
$ kubectl apply -f 03-daemonset-demo.yaml
daemonset.apps.kruise.io/nginx created
[root@master1 ~]#kubectl get daemon
NAME DESIREDNUMBER CURRENTNUMBER UPDATEDNUMBERSCHEDULED AGE
nginx 2 2 2 11s
[root@master1 ~]#kubectl get pods -l k8s-app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-gbz5h 1/1 Running 0 17s 10.244.2.49 node2 <none> 1/1
nginx-hgx4b 1/1 Running 0 17s 10.244.1.164 node1 <none> 1/1
我们这里只有两个 Work 节点,所以一共运行了2个 Pod,每个节点上一个,和默认的 DaemonSet 行为基本一致。
- 此外这个策略还支持用户通过配置 node 标签的 selector,来指定灰度升级某些特定类型 node 上的 Pod。比如现在我们只升级 node1 节点的应用,则可以使用
selector标签来标识:
注意:这个功能还是比较实用的,在恢复发布方面,可以把故障域缩小到一定区间。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
# ...
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: Standard
selector: #添加节点selector
matchLabels: #只会针对node1节点做做更新
kubernetes.io/hostname: node1
# ...
完整yaml代码如下:
#04-daemonset-demo2.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: nginx
namespace: default
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: Standard
selector: #修改点1:添加节点selector
matchLabels: #只会针对node1节点做做更新
kubernetes.io/hostname: node1
selector:
matchLabels:
k8s-app: nginx
template:
metadata:
labels:
k8s-app: nginx
spec:
containers:
- image: nginx #修改点2:修改nginx镜像
name: nginx
ports:
- name: http
containerPort: 80
- 更新应用后可以看到只会更新 node1 节点上的 Pod:
#部署
$ kubectl apply -f 04-daemonset-demo2.yaml
daemonset.apps.kruise.io/nginx configured
[root@master1 ~]#kubectl get pods -l k8s-app=nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-d67ms 1/1 Running 0 17s 10.244.1.165 node1 <none> 1/1
nginx-gbz5h 1/1 Running 0 6m24s 10.244.2.49 node2 <none> 1/1
[root@master1 ~]#kubectl describe daemon nginx
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 7m22s daemonset-controller Created pod: nginx-hgx4b
Normal SuccessfulCreate 7m22s daemonset-controller Created pod: nginx-gbz5h
Normal SuccessfulDelete 76s daemonset-controller Deleted pod: nginx-hgx4b
Normal SuccessfulCreate 75s daemonset-controller Created pod: nginx-d67ms
- 和前面两个控制器一样,Advanced DaemonSet 也支持分批灰度升级,使用 Partition 进行配置,Partition 的语义是保留旧版本 Pod 的数量,默认为 0,如果在发布过程中设置了 partition,则控制器只会将
(status.DesiredNumberScheduled - partition)数量的 Pod 更新到最新版本。
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
# ...
updateStrategy:
type: RollingUpdate
rollingUpdate:
partition: 10 #如果大于期望运行的pod数量,则不会更新。
paused: true # 暂停发布
- 同样 Advanced DaemonSet 也是支持原地升级的,只需要设置
rollingUpdateType为支持原地升级的类型即可,比如这里我们将上面的应用升级方式设置为InPlaceIfPossible即可:
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
spec:
# ...
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: InPlaceIfPossible #设置为尽可能地原地升级。
完整yam代码如下:
#05-daemonset-demo3.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: DaemonSet
metadata:
name: nginx
namespace: default
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
rollingUpdateType: InPlaceIfPossible #修改点1
selector:
matchLabels:
k8s-app: nginx
template:
metadata:
labels:
k8s-app: nginx
spec:
containers:
- image: nginx:1.7.9 #修改点2:修改nginx镜像,只修改镜像的版本会当成原地升级的场景
name: nginx
ports:
- name: http
containerPort: 80
- 在测试之前,我们准备下当前环境:
#清空下当前环境,然后重新部署下05-daemonset-demo3.yaml,并查看下当前pod信息
[root@master1 ~]#kubectl delete daemon nginx
daemonset.apps.kruise.io "nginx" deleted
$ kubectl apply -f 05-daemonset-demo3.yaml
daemonset.apps.kruise.io/nginx created
[root@master1 ~]#kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7h2nw 1/1 Running 0 4s 10.244.1.168 node1 <none> 2/2
nginx-bmzcq 1/1 Running 0 4s 10.244.2.52 node2 <none> 2/2
#然后把05-daemonset-demo3.yaml里面的镜像改下,再部署下,观察下效果
……
- image: nginx
……
- 更新后可以通过查看控制器的事件来验证是否是通过原地升级方式更新应用:
$ kubectl apply -f 05-daemonset-demo3.yaml
daemonset.apps.kruise.io/nginx configured
[root@master1 ~]#kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-7h2nw 1/1 Running 1 (10s ago) 2m13s 10.244.1.168 node1 <none> 2/2
nginx-bmzcq 1/1 Running 1 (13s ago) 2m13s 10.244.2.52 node2 <none> 2/2
[root@master1 ~]#kubectl describe daemon nginx
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 2m29s daemonset-controller Created pod: nginx-bmzcq
Normal SuccessfulCreate 2m29s daemonset-controller Created pod: nginx-7h2nw
Normal SuccessfulUpdatePodInPlace 29s daemonset-controller successfully update pod nginx-bmzcq in-place
Warning numUnavailable >= maxUnavailable 27s (x7 over 29s) daemonset-controller default/nginx number of unavailable DaemonSet pods: 1, is equal to or exceeds allowed maximum: 1
Normal SuccessfulUpdatePodInPlace 26s daemonset-controller successfully update pod nginx-7h2nw in-place
- 注意:这里使用
daemon就好。
[root@master1 ~]#kubectl get crd|grep kruise
advancedcronjobs.apps.kruise.io 2022-03-10T13:09:22Z
broadcastjobs.apps.kruise.io 2022-03-10T13:09:22Z
clonesets.apps.kruise.io 2022-03-10T13:09:22Z
containerrecreaterequests.apps.kruise.io 2022-03-10T13:09:22Z
daemonsets.apps.kruise.io 2022-03-10T13:09:22Z
imagepulljobs.apps.kruise.io 2022-03-10T13:09:22Z
nodeimages.apps.kruise.io 2022-03-10T13:09:22Z
podunavailablebudgets.policy.kruise.io 2022-03-10T13:09:22Z
resourcedistributions.apps.kruise.io 2022-03-10T13:09:22Z
sidecarsets.apps.kruise.io 2022-03-10T13:09:22Z
statefulsets.apps.kruise.io 2022-03-10T13:09:22Z
uniteddeployments.apps.kruise.io 2022-03-10T13:09:22Z
workloadspreads.apps.kruise.io 2022-03-10T13:09:22Z
[root@master1 ~]#kubectl get crd daemonsets.apps.kruise.io -oyaml
……
spec:
conversion:
strategy: None
group: apps.kruise.io
names:
kind: DaemonSet
listKind: DaemonSetList
plural: daemonsets
shortNames:
- daemon
singular: daemonset
……
实验结束。😘
3、BroadcastJob
这个控制器将 Pod 分发到集群中每个节点上,类似于 DaemonSet,但是 BroadcastJob 管理的 Pod 并不是长期运行的 daemon 服务,而是类似于 Job 的任务类型 Pod,在每个节点上的 Pod 都执行完成退出后,BroadcastJob 和这些 Pod 并不会占用集群资源。 这个控制器非常有利于做升级基础软件、巡检等过一段时间需要在整个集群中跑一次的工作。
💘 实验:BroadcastJob
- 比如我们声明一个如下所示的 BroadcastJob 对象:
#06-BroadcastJob.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
metadata:
name: bcj-demo
namespace: default
spec:
template:
spec:
restartPolicy: Never
containers: # 一定不是一个常驻前台的进程,一定是一个任务,执行完成后需要退出的
- name: counter
image: busybox
command:
- "/bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
- 直接创建上面的资源对象,
$ kubectl apply -f 06-BroadcastJob.yaml
broadcastjob.apps.kruise.io/bcj-demo created
[root@master1 ~]#kubectl get bcj
NAME DESIRED ACTIVE SUCCEEDED FAILED AGE
bcj-demo 2 0 2 0 87s
[root@master1 ~]#kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
bcj-demo-48b8q 0/1 Completed 0 90s 10.244.1.169 node1 <none> 1/1
bcj-demo-w9m79 0/1 Completed 0 90s 10.244.2.53 node2 <none> 1/1
我们可以看到创建了一个 BroadcastJob 对象后,同时启动了两个 Pod 任务,每个节点上一个,这和原生的 Job 是不太一样的。
创建的 BroadcastJob 一共有以下几种状态:
- Desired : 期望的 Pod 数量(等同于当前集群中匹配的节点数量)
- Active: 运行中的 Pod 数量
- SUCCEEDED: 执行成功的 Pod 数量
- FAILED: 执行失败的 Pod 数量
🍀 此外在 BroadcastJob 对象中还可以配置任务完成后的一些策略,比如配置 completionPolicy.ttlSecondsAfterFinished: 30,表示这个 job 会在执行结束后 30s 被删除。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
spec:
completionPolicy:
type: Always
ttlSecondsAfterFinished: 30
# ......
🍀 配置 completionPolicy.activeDeadlineSeconds 为 10,表示这个 job 会在运行超过 10s 之后被标记为失败,并把下面还在运行的 Pod 删除掉。
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
spec:
completionPolicy:
type: Always
activeDeadlineSeconds: 10
# ......
🍀 completionPolicy 类型除了 Always 之外还可以设置为 Never,表示这个 job 会持续运行即使当前所有节点上的 Pod 都执行完成了。这里老师当时说,好像没看到具体效果……
apiVersion: apps.kruise.io/v1alpha1
kind: BroadcastJob
spec:
completionPolicy:
type: Never
# ......
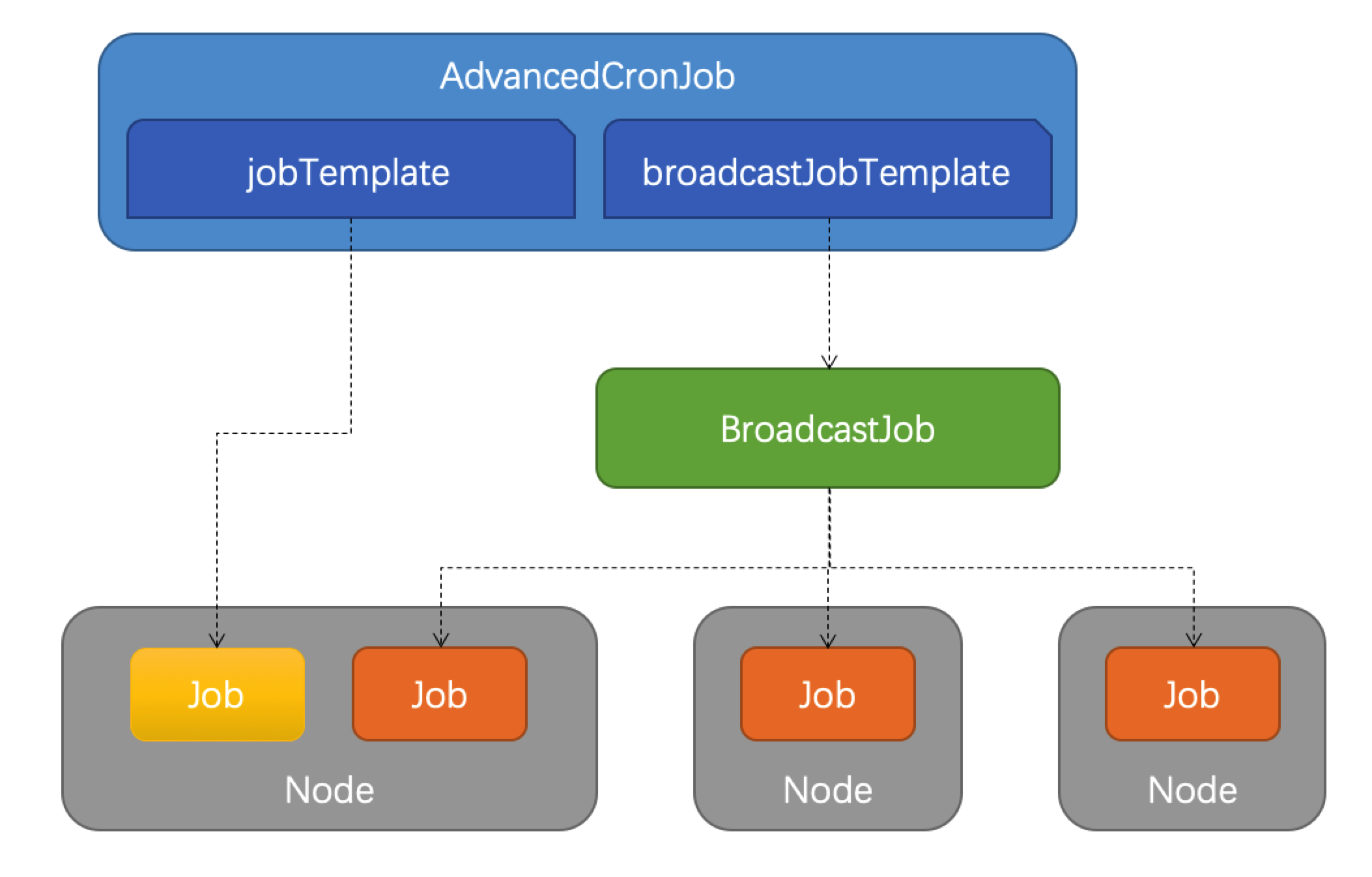
4、AdvancedCronJob
💘 实验:AdvancedCronJob
AdvancedCronJob 是对于原生 CronJob 的扩展版本,根据用户设��置的 schedule 规则,周期性创建 Job 执行任务,而 AdvancedCronJob 的 template 支持多种不同的 job 资源:
apiVersion: apps.kruise.io/v1alpha1
kind: AdvancedCronJob
spec:
template:
# Option 1: use jobTemplate, which is equivalent to original CronJob
jobTemplate:
# ...
# Option 2: use broadcastJobTemplate, which will create a BroadcastJob object when cron schedule triggers
broadcastJobTemplate:
# ...
jobTemplate:与原生 CronJob 一样创建 Job 执行任务broadcastJobTemplate:周期性创建 BroadcastJob 执行任务
- 写一个yaml
#07-acj-demo1.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: AdvancedCronJob
metadata:
name: acj-test
spec:
schedule: "*/1 * * * *"
template:
broadcastJobTemplate:
spec:
completionPolicy:
type: Always
ttlSecondsAfterFinished: 30
template:
spec:
restartPolicy: Never
containers: # 一定不是一个常驻前台的进程,一定是一个任务,执行完成后需要退出的
- name: counter
image: busybox
command:
- "/bin/sh"
- "-c"
- "for i in 9 8 7 6 5 4 3 2 1; do echo $i; done"
上述 YAML 定义了一个 AdvancedCronJob,每分钟创建一个 BroadcastJob 对象,这个 BroadcastJob 会在所有节点上运行一个 job 任务。
- 部署并查看
$ kubectl apply -f 07-acj-demo1.yaml
advancedcronjob.apps.kruise.io/acj-test created
[root@master1 ~]#kubectl get acj
NAME SCHEDULE TYPE LASTSCHEDULETIME AGE
acj-test */1 * * * * BroadcastJob 25s
[root@master1 ~]#kubectl get bcj
NAME DESIRED ACTIVE SUCCEEDED FAILED AGE
acj-test-1647045420 2 0 2 0 18s
acj-test-1647045480 2 1 1 0 5s
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
acj-test-1647045420-56x7j 0/1 Completed 0 33s
acj-test-1647045420-nkrx4 0/1 Completed 0 33s
实验结束。😘
关于我
我的博客主旨:我希望每一个人拿着我的博客都可以做出实验现象,先把实验做出来,然后再结合理论知识更深层次去理解技术点,这样学习起来才有乐趣和动力。并且,我的博客内容步骤是很完整的,也分享源码和实验用到的软件,希望能和大家一起共同进步!
各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人免费帮您解决问题:
- 个人微信二维码:x2675263825 (舍得), qq:2675263825。

- 个人微信公众号:云原生架构师实战

- 个人博客地址:www.onlyonexl.cn
- 个人csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
最后
好了,关于OpenKruise通用控制器实验就到这里了,感谢大家阅读,最后贴上我女神的photo,祝大家生活快乐,每天都过的有意义哦,我们下期见!

1