6、HPA与VPA
HPA与VPA

目录
[toc]
1、HPA
在前面的学习中我们使用了一个 kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个是完全手动操作的,要应对线上的各种复杂情况,我们需要能够做到自动化去感知业务,来自动进行扩缩容。为此,Kubernetes 也为我们提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称 HPA,HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理。在 Kubernetes控制平面内运行的 HPA控制器会定期调整其目标(例如:Deployment)的所需规模,以匹配观察到的指标,例如,平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标。
1.工作原理
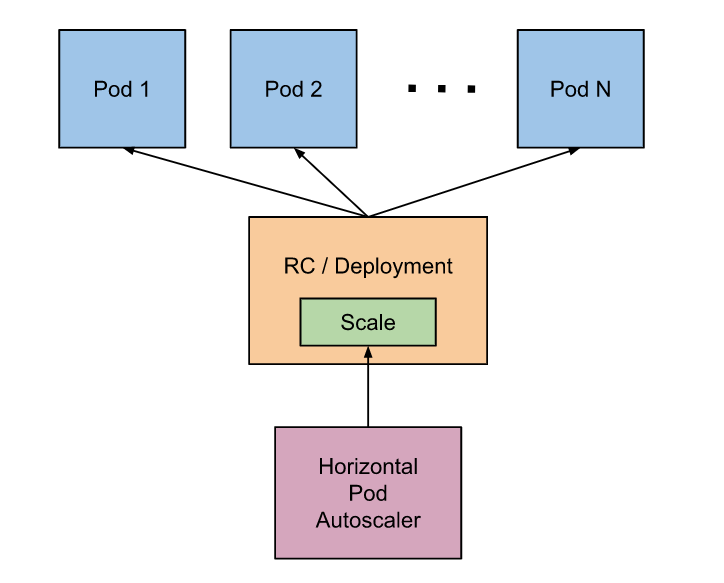
对于按 Pod 统计的资源指标(如 CPU),控制器从资源指标 API 中获取每一个 HorizontalPodAutoscaler 指定的Pod 的 metrics 值,如��果设置了目标使用率,控制器获取每个 Pod 中的容器资源使用情况,并计算资源使用率。如果设置了 **target 值,**将直接使用原始数据(不再计算百分比)。接下来,控制器根据平均的资源使用率或原始值计算出扩缩的比例,进而计算出目标副本数。
需要注意的是,如果 Pod 某些容器不支持资源采集,那么控制器将不会使用该 Pod 的 CPU 使用率。
如果 Pod 使用自定义指示,控制器机制与资源指标类似,区别在于自定义指标只使用原始值,而不是使用率。如果 Pod 使用对象指标和外部指标(每个指标描述一个对象信息)。 这个指标将直接根据目标设定值相比较,并生成一个上面提到的扩缩比例。 在 autoscaling/v2beta2 版本 API 中,这个指标也可以根据 Pod 数量平分后再计算。
对 Metrics API 的支持解释了这些不同 API 的稳定性保证和支持状态。
HorizontalPodAutoscaler 控制器访问支持扩缩的相应工作负载资源(例如:Deployment 和 StatefulSet)。这些资源每个都有一个名为 scale 的子资源,该接口允许你动态设置副本的数量并检查它们的每个当前状态。
2.Metrics Server
见单独md。
https://onedayxyy.cn/docs/metrics-server

3.CPU
💘 实战:hpa cpu测试-2022.12.24(成功测试)
- 实验环境
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点
k8s version:v1.20
CONTAINER-RUNTIME:containerd:v1.6.10
-
实验软件(无)
-
现在我们用 Deployment 来创建一个 Nginx Pod,然后利用
HPA来进行自动扩缩容。资源清单如下所示:
# hpa-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
- 然后直接创建 Deployment,注意一定先把之前创建的具有
app=nginx的 Pod 先清除掉:
[root@master1 ~]#kubectl apply -f hpa-demo.yaml
deployment.apps/hpa-demo created
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
hpa-demo-ff6774dc6-lbt2b 1/1 Running 0 105s
- 现在我们来创建一个
HPA资源对象,可以使用kubectl autoscale命令来创建:(我们也可以先用kubectl explains hpa.spec来查看下hpa资源的可用字段:)
[root@master1 ~]#kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
horizontalpodautoscaler.autoscaling/hpa-demo autoscaled
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo <unknown>/10% 1 10 1 33s
#注意:这里的`unkown`字段是异常的;
此命令创建了一个关联资源 hpa-demo 的 HPA,最小的 Pod 副本数为1,最大为10。HPA 会根据设定的 **cpu 使用率(10%)**动态的增加或者减少 Pod 数量。
当然我们依然还是可以通过创建 YAML 文件的形式来创建 HPA 资源对象。如果我们不知道怎么编写的话,可以查看上面命令行创建的HPA的YAML文件:
[root@master1 ~]#kubectl get hpa -oyaml
apiVersion: v1
items:
- apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: "2022-12-24T06:55:30Z"
name: hpa-demo
namespace: default
resourceVersion: "800687"
uid: c6e18224-a5df-43df-90af-2ed7806e788a
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 10 #注意这里,是pod的平均使用率。
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-demo
status:
conditions:
- lastTransitionTime: "2022-12-24T06:55:45Z"
message: the HPA controller was able to get the target's current scale
reason: SucceededGetScale
status: "True"
type: AbleToScale
- lastTransitionTime: "2022-12-24T06:55:45Z"
message: 'the HPA was unable to compute the replica count: failed to get cpu
utilization: missing request for cpu'
reason: FailedGetResourceMetric
status: "False"
type: ScalingActive
currentMetrics: null
currentReplicas: 1
desiredReplicas: 0
kind: List
metadata:
resourceVersion: ""
- 然后我们可以根据上面的 YAML 文件就可以自己来创建一个基于 YAML 的 HPA 描述文件了。但是我们发现上面信息里面出�现了一些 Fail 信息,我们来查看下这个 HPA 对象的信息:
[root@master1 ~]#kubectl describe hpa hpa-demo
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: hpa-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat, 24 Dec 2022 14:55:30 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): <unknown> / 10%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 0 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True SucceededGetScale the HPA controller was able to get the target's current scale
ScalingActive False FailedGetResourceMetric the HPA was unable to compute the replica count: failed to get cpu utilization: missing request for cpu
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedGetResourceMetric 5s (x11 over 2m35s) horizontal-pod-autoscaler failed to get cpu utilization: missing request for cpu
Warning FailedComputeMetricsReplicas 5s (x11 over 2m35s) horizontal-pod-autoscaler invalid metrics (1 invalid out of 1), first error is: failed to get cpu resource metric value: failed to get cpu utilization: missing request for cpu
我们可以看到上面的事件信息里面出现了 failed to get cpu utilization: missing request for cpu 这样的错误信息。这是因为我们上面创建的 Pod 对象没有添加 request 资源声明,这样导致 HPA 读取不到 CPU 指标信息,所以如果要想让 HPA 生效,对应的 Pod 资源必须添加 requests 资源声明,来更新我们的资源清单文件。
- 更新我们的资源清单文件,添加
requests资源
# hpa-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
然后重新更新 Deployment,重新创建 HPA 对象:
[root@master1 ~]#kubectl apply -f hpa-demo.yaml
deployment.apps/hpa-demo configured
[root@master1 ~]#kubectl get po -l app=nginx -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hpa-demo-f5597c99-wl6ql 1/1 Running 0 21s 10.244.1.40 node1 <none> <none>
[root@master1 ~]#kubectl delete hpa hpa-demo
horizontalpodautoscaler.autoscaling "hpa-demo" deleted
[root@master1 ~]#kubectl autoscale deployment hpa-demo --cpu-percent=10 --min=1 --max=10
horizontalpodautoscaler.autoscaling/hpa-demo autoscaled
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE ##当然现在这个pod的资源使用率不可能是0%
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 17s
[root@master1 ~]#kubectl describe hpa hpa-demo
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: hpa-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat, 24 Dec 2022 15:02:51 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 0% (0) / 10%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica count
Events: <none>
现在可以看到 HPA 资源对象已经正常了。
- 现在,我们来增大负载进行测试,我们来创建一个 busybox 的 Pod,并且循环访问上面创建的 Pod:
我们新打开一个终端:
root@master1 ~]#kubectl run -it --image busybox test-hpa --restart=Never --rm /bin/sh
If you don't see a command prompt, try pressing enter.
/ # while true; do wget -q -O- http://10.244.1.40; done
注意:在压力测试之前监控下pod。
然后观察 Pod 列表,可以看到,HPA 已经开始工作:
[root@master1 ~]#kubectl get hpa --watch
[root@master1 ~]#kubectl get po -l app=nginx --watch
[root@master1 ~]#kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 5m22s
hpa-demo Deployment/hpa-demo 136%/10% 1 10 1 6m40s
hpa-demo Deployment/hpa-demo 240%/10% 1 10 4 6m55s
hpa-demo Deployment/hpa-demo 236%/10% 1 10 8 7m10s
hpa-demo Deployment/hpa-demo 78%/10% 1 10 10 7m25s
hpa-demo Deployment/hpa-demo 46%/10% 1 10 10 7m40s
hpa-demo Deployment/hpa-demo 31%/10% 1 10 10 7m55s
hpa-demo Deployment/hpa-demo 27%/10% 1 10 10 8m10s
hpa-demo Deployment/hpa-demo 28%/10% 1 10 10 8m25s
hpa-demo Deployment/hpa-demo 21%/10% 1 10 10 8m40s
hpa-demo Deployment/hpa-demo 23%/10% 1 10 10 8m55s
hpa-demo Deployment/hpa-demo 24%/10% 1 10 10 9m10s
hpa-demo Deployment/hpa-demo 25%/10% 1 10 10 9m25s
hpa-demo Deployment/hpa-demo 23%/10% 1 10 10 9m40s
hpa-demo Deployment/hpa-demo 24%/10% 1 10 10 9m55s
[root@master1 ~]#kubectl get po -l app=nginx --watch
NAME READY STATUS RESTARTS AGE
hpa-demo-f5597c99-wl6ql 1/1 Running 0 6m32s
hpa-demo-f5597c99-vgvsx 0/1 Pending 0 0s
hpa-demo-f5597c99-spmww 0/1 Pending 0 0s
hpa-demo-f5597c99-vgvsx 0/1 Pending 0 0s
hpa-demo-f5597c99-kn2nl 0/1 Pending 0 0s
hpa-demo-f5597c99-vgvsx 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-spmww 0/1 Pending 0 0s
hpa-demo-f5597c99-kn2nl 0/1 Pending 0 0s
hpa-demo-f5597c99-kn2nl 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-spmww 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-7fqq7 0/1 Pending 0 0s
hpa-demo-f5597c99-7fqq7 0/1 Pending 0 0s
hpa-demo-f5597c99-7t9tg 0/1 Pending 0 0s
hpa-demo-f5597c99-574js 0/1 Pending 0 0s
hpa-demo-f5597c99-kn27l 0/1 Pending 0 0s
hpa-demo-f5597c99-7fqq7 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-574js 0/1 Pending 0 0s
hpa-demo-f5597c99-7t9tg 0/1 Pending 0 0s
hpa-demo-f5597c99-kn27l 0/1 Pending 0 0s
hpa-demo-f5597c99-7t9tg 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-574js 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-kn27l 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-spmww 1/1 Running 0 16s
hpa-demo-f5597c99-vgvsx 1/1 Running 0 17s
hpa-demo-f5597c99-zjr9t 0/1 Pending 0 0s
hpa-demo-f5597c99-78zjn 0/1 Pending 0 0s
hpa-demo-f5597c99-zjr9t 0/1 Pending 0 0s
hpa-demo-f5597c99-78zjn 0/1 Pending 0 0s
hpa-demo-f5597c99-78zjn 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-zjr9t 0/1 ContainerCreating 0 0s
hpa-demo-f5597c99-kn2nl 1/1 Running 0 32s
hpa-demo-f5597c99-574js 1/1 Running 0 17s
hpa-demo-f5597c99-7fqq7 1/1 Running 0 17s
hpa-demo-f5597c99-7t9tg 1/1 Running 0 32s
hpa-demo-f5597c99-zjr9t 1/1 Running 0 17s
hpa-demo-f5597c99-kn27l 1/1 Running 0 47s
hpa-demo-f5597c99-78zjn 1/1 Running 0 47s
- 我们可以看到已经自动拉起了很多新的 Pod,最后会定格在了我们上面设置的 10 个 Pod,同时查看资源 hpa-demo 的副本数量,副本数量已经从原来的1变成了10个:
[root@master1 ~]#kubectl get po -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-demo-f5597c99-574js 1/1 Running 0 113s
hpa-demo-f5597c99-78zjn 1/1 Running 0 98s
hpa-demo-f5597c99-7fqq7 1/1 Running 0 113s
hpa-demo-f5597c99-7t9tg 1/1 Running 0 113s
hpa-demo-f5597c99-kn27l 1/1 Running 0 113s
hpa-demo-f5597c99-kn2nl 1/1 Running 0 2m8s
hpa-demo-f5597c99-spmww 1/1 Running 0 2m8s
hpa-demo-f5597c99-vgvsx 1/1 Running 0 2m8s
hpa-demo-f5597c99-wl6ql 1/1 Running 0 9m42s
hpa-demo-f5597c99-zjr9t 1/1 Running 0 98s
[root@master1 ~]#kubectl get deploy hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 10/10 10 10 18m
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 23%/10% 1 10 10 9m1s
- 查看 HPA 资源的对象了解工作过程:
[root@master1 ~]#kubectl describe hpa hpa-demo
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: hpa-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat, 24 Dec 2022 15:02:51 +0800
Reference: Deployment/hpa-demo
Metrics: ( current / target )
resource cpu on pods (as a percentage of request): 25% (12m) / 10%
Min replicas: 1
Max replicas: 10
Deployment pods: 10 current / 10 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale recommended size matches current size
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from cpu resource utilization (percentage of request)
ScalingLimited True TooManyReplicas the desired replica count is more than the maximum replica count
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 2m46s horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 2m31s horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 2m16s horizontal-pod-autoscaler New size: 10; reason: cpu resource utilization (percentage of request) above target
- 同样的这个时候我们来关掉 busybox 来减少负载,然后等待一段时间观察下 HPA 和 Deployment 对象:
[root@master1 ~]#kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 16%/10% 1 10 10 21m
hpa-demo Deployment/hpa-demo 12%/10% 1 10 10 21m
hpa-demo Deployment/hpa-demo 0%/10% 1 10 10 21m
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
hpa-demo-6b4467b546-4x7j2 1/1 Running 0 5m25s
hpa-demo-6b4467b546-54zws 1/1 Running 0 5m25s
hpa-demo-6b4467b546-6mv5h 1/1 Running 0 5m56s
hpa-demo-6b4467b546-88rtv 1/1 Running 0 26m
hpa-demo-6b4467b546-9hlhz 1/1 Running 0 5m56s
hpa-demo-6b4467b546-9x7wk 1/1 Running 0 5m56s
hpa-demo-6b4467b546-bs2qk 1/1 Running 0 5m41s
hpa-demo-6b4467b546-djsvv 1/1 Running 0 5m40s
hpa-demo-6b4467b546-j59pz 1/1 Running 0 5m40s
hpa-demo-6b4467b546-tcwkt 1/1 Running 0 5m40s
[root@master1 ~]#kubectl get deployments.apps hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 10/10 10 10 51m
[root@master1 ~]#
缩放间隙:
从 Kubernetes v1.12 版本开始我们可以通过设置 kube-controller-manager 组件的--horizontal-pod-autoscaler-downscale-stabilization 参数来设置一个持续时间,用于指定在当前操作完成后,HPA 必须等待多长时间才能执行另一次缩放操作。默认为5分钟,也就是默认需要等待5分钟后才会开始自动缩放。
可以看到5分钟后,副本数量已经由 10 变为 1,当前我们只是演示了 CPU 使用率这一个指标,在后面的课程中我们还会学习到根据自定义的监控指标来自动对 Pod 进行扩缩容。
[root@master1 ~]#kubectl get hpa --watch
……
hpa-demo Deployment/hpa-demo 0%/10% 1 10 10 16m
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 16m
[root@master1 ~]#kubectl get po -l app=nginx --watch
……
hpa-demo-f5597c99-7t9tg 1/1 Terminating 0 9m31s
hpa-demo-f5597c99-7fqq7 1/1 Terminating 0 9m31s
hpa-demo-f5597c99-574js 1/1 Terminating 0 9m31s
hpa-demo-f5597c99-zjr9t 1/1 Terminating 0 9m16s
hpa-demo-f5597c99-spmww 1/1 Terminating 0 9m46s
hpa-demo-f5597c99-kn27l 1/1 Terminating 0 9m31s
hpa-demo-f5597c99-78zjn 1/1 Terminating 0 9m16s
hpa-demo-f5597c99-vgvsx 1/1 Terminating 0 9m46s
hpa-demo-f5597c99-kn2nl 1/1 Terminating 0 9m46s
hpa-demo-f5597c99-574js 0/1 Terminating 0 9m31s
hpa-demo-f5597c99-zjr9t 0/1 Terminating 0 9m16s
hpa-demo-f5597c99-spmww 0/1 Terminating 0 9m47s
hpa-demo-f5597c99-7fqq7 0/1 Terminating 0 9m32s
hpa-demo-f5597c99-574js 0/1 Terminating 0 9m32s
hpa-demo-f5597c99-574js 0/1 Terminating 0 9m32s
hpa-demo-f5597c99-zjr9t 0/1 Terminating 0 9m17s
hpa-demo-f5597c99-zjr9t 0/1 Terminating 0 9m17s
hpa-demo-f5597c99-7t9tg 0/1 Terminating 0 9m32s
hpa-demo-f5597c99-7t9tg 0/1 Terminating 0 9m32s
hpa-demo-f5597c99-7t9tg 0/1 Terminating 0 9m32s
hpa-demo-f5597c99-78zjn 0/1 Terminating 0 9m17s
hpa-demo-f5597c99-78zjn 0/1 Terminating 0 9m17s
hpa-demo-f5597c99-78zjn 0/1 Terminating 0 9m17s
hpa-demo-f5597c99-kn27l 0/1 Terminating 0 9m32s
hpa-demo-f5597c99-kn27l 0/1 Terminating 0 9m33s
hpa-demo-f5597c99-kn27l 0/1 Terminating 0 9m33s
hpa-demo-f5597c99-7fqq7 0/1 Terminating 0 9m33s
hpa-demo-f5597c99-7fqq7 0/1 Terminating 0 9m33s
hpa-demo-f5597c99-vgvsx 0/1 Terminating 0 9m48s
hpa-demo-f5597c99-spmww 0/1 Terminating 0 9m48s
hpa-demo-f5597c99-spmww 0/1 Terminating 0 9m48s
hpa-demo-f5597c99-vgvsx 0/1 Terminating 0 9m48s
hpa-demo-f5597c99-vgvsx 0/1 Terminating 0 9m48s
hpa-demo-f5597c99-kn2nl 0/1 Terminating 0 9m48s
hpa-demo-f5597c99-kn2nl 0/1 Terminating 0 9m49s
hpa-demo-f5597c99-kn2nl 0/1 Terminating 0 9m49s
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
hpa-demo-f5597c99-wl6ql 1/1 Running 0 19m
[root@master1 ~]#kubectl get deployments.apps hpa-demo
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-demo 1/1 1 1 27m
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-demo Deployment/hpa-demo 0%/10% 1 10 1 18m
测试结束。😘
4.内存
💘 实战:hpa 内存测试-2022.12.24(成功测试)
- 实验环境
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点
k8s version:v1.20
CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件(无)
注意:在做本次实验前,把上一个实验的all资源全部卸载掉,以方便精确测试实验。
kubectl delete hpa hpa-demo
kubectl delete deployments.apps hpa-demo
- 要使用基于内存或者自定义指标进行扩缩容(现在的版本都必须依赖 metrics-server 这个项目)。现在我们再用 Deployment 来创建一个 Nginx Pod,然后利用 HPA 来进行自动扩缩容。资源清单如下所示:
# hpa-mem-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-mem-demo
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
volumes:
- name: increase-mem-script
configMap:
name: increase-mem-config
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: increase-mem-script
mountPath: /etc/script
resources:
requests:
memory: 50Mi
cpu: 50m
securityContext:
privileged: true
这里和前面普通的应用有一些区别,我们将一个名为 increase-mem-config 的 ConfigMap 资源对象挂载到了容器中,该配置文件是用于后面增加容器内存占用的脚本,配置文件如下所示:
# increase-mem-cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: increase-mem-config
data:
increase-mem.sh: |
#!/bin/bash
mkdir /tmp/memory
mount -t tmpfs -o size=40M tmpfs /tmp/memory
dd if=/dev/zero of=/tmp/memory/block
sleep 60
rm /tmp/memory/block
umount /tmp/memory
rmdir /tmp/memory
由于这里增加内存的脚本需要使用到 mount 命令,这需要声明为特权模式,所以我们添加了 securityContext.privileged=true 这个配置。
- 现在我们直接创建上面的资源对象即可:
[root@master1 ~]#kubectl apply -f hpa-mem-demo.yaml
deployment.apps/hpa-mem-demo created
[root@master1 ~]#kubectl apply -f increase-mem-cm.yaml
configmap/increase-mem-config created
[root@master1 ~]#kubectl get po -l app=nginx
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-6f6455888b-h4nxk 1/1 Running 0 118s
- 然后需要创建一个基于内存的 HPA 资源对象:
# hpa-mem.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-mem-demo
namespace: default
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-mem-demo
metrics: # 指定内存的一个配置
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 30
要注意这里使用的 apiVersion 是 autoscaling/v2,然后 metrics 属性里面指定的是内存的配置。
注意:扩容目标引用(scaleTargetRef ):
扩容目标引用(scaleTargetRef ):后面可以是一个deployment或者是replicaset。
一个hpa和一个例如deployment是一一对应的。
- 直接创建上面的资源对象即可
[root@master1 ~]#kubectl apply -f hpa-mem.yaml
horizontalpodautoscaler.autoscaling/hpa-mem-demo created
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-mem-demo Deployment/hpa-mem-demo 3%/30% 1 5 1 24s
到这里证明 HPA 资源对象已经部署成功了。
- 接下来我们对应用进行压测,将内存压上去,直接执行上面我们挂载到容器中的
increase-mem.sh脚本即可:
[root@master1 ~]#kubectl exec -it hpa-mem-demo-6f6455888b-h4nxk -- bash
root@hpa-mem-demo-6f6455888b-h4nxk:/# ls /etc/script/
increase-mem.sh
root@hpa-mem-demo-6f6455888b-h4nxk:/# source /etc/script/increase-mem.sh
dd: writing to '/tmp/memory/block': No space left on device
81921+0 records in
81920+0 records out
41943040 bytes (42 MB, 40 MiB) copied, 0.0677346 s, 619 MB/s
- 然后打开另外一个终端观察 HPA 资源对象的变化情况:
- 可以看到内存使用已经超过了我们设定的 30% 这个阈值了,HPA 资源对象也已经触发了自动扩容,变成了4个副本了:
[root@master1 ~]#kubectl get hpa --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-mem-demo Deployment/hpa-mem-demo 3%/30% 1 5 1 2m39s
hpa-mem-demo Deployment/hpa-mem-demo 4%/30% 1 5 1 4m1s
hpa-mem-demo Deployment/hpa-mem-demo 85%/30% 1 5 1 4m16s
hpa-mem-demo Deployment/hpa-mem-demo 85%/30% 1 5 3 4m31s
hpa-mem-demo Deployment/hpa-mem-demo 31%/30% 1 5 3 5m1s
hpa-mem-demo Deployment/hpa-mem-demo 4%/30% 1 5 3 5m16s
[root@master1 ~]#kubectl get po -l app=nginx --watch
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-6f6455888b-h4nxk 1/1 Running 0 7m19s
hpa-mem-demo-6f6455888b-8cv79 0/1 Pending 0 0s
hpa-mem-demo-6f6455888b-nj5h2 0/1 Pending 0 0s
hpa-mem-demo-6f6455888b-8cv79 0/1 Pending 0 0s
hpa-mem-demo-6f6455888b-nj5h2 0/1 Pending 0 0s
hpa-mem-demo-6f6455888b-8cv79 0/1 ContainerCreating 0 0s
hpa-mem-demo-6f6455888b-nj5h2 0/1 ContainerCreating 0 0s
hpa-mem-demo-6f6455888b-nj5h2 1/1 Running 0 16s
hpa-mem-demo-6f6455888b-8cv79 1/1 Running 0 17s
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-6f6455888b-8cv79 1/1 Running 0 3m18s
hpa-mem-demo-6f6455888b-h4nxk 1/1 Running 0 12m
hpa-mem-demo-6f6455888b-nj5h2 1/1 Running 0 3m18s
[root@master1 ~]#kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
hpa-mem-demo 3/3 3 3 12m
[root@master1 ~]#kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa-mem-demo Deployment/hpa-mem-demo 4%/30% 1 5 3 7m50s
[root@master1 ~]#kubectl describe hpa hpa-mem-demo
Warning: autoscaling/v2beta2 HorizontalPodAutoscaler is deprecated in v1.23+, unavailable in v1.26+; use autoscaling/v2 HorizontalPodAutoscaler
Name: hpa-mem-demo
Namespace: default
Labels: <none>
Annotations: <none>
CreationTimestamp: Sat, 24 Dec 2022 15:30:06 +0800
Reference: Deployment/hpa-mem-demo
Metrics: ( current / target )
resource memory on pods (as a percentage of request): 4% (2437120) / 30%
Min replicas: 1
Max replicas: 5
Deployment pods: 3 current / 3 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from memory resource utilization (percentage of request)
ScalingLimited False DesiredWithinRange the desired count is within the acceptable range
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 3m40s horizontal-pod-autoscaler New size: 3; reason: memory resource utilization (percentage of request) above target
[root@master1 ~]#
- 当内存释放掉后,controller-manager 默认5分钟过后会进行缩放,到这里就完成了基于内存的 HPA 操作。
#这里通过按下ctrl c终止掉压测内存的程序即可
#查看效果
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
hpa-mem-demo-6f6455888b-8cv79 1/1 Running 0 6m28s
[root@master1 ~]#kubectl get po,deploy,hpa
NAME READY STATUS RESTARTS AGE
pod/hpa-mem-demo-6f6455888b-8cv79 1/1 Running 0 6m34s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/hpa-mem-demo 1/1 1 1 15m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/hpa-mem-demo Deployment/hpa-mem-demo 3%/30% 1 5 1 10m
注意:这里过了60s之后,就会自动终止这个压测程序了……



测试结束😘。
5.扩缩容行为
如果使用 v2 版本的 HPA API,我们还可以使用 behavior 字段来配置单独的放大和缩小行为,可以通过在behavior 字段下设置 scaleUp 和/或 scaleDown 来指定这些行为。
你可以指定一个稳定窗口,以防止扩缩目标的副本计数发生波动,扩缩策略还允许你在扩缩时控制副本的变化率。
(1)扩缩策略
可以在 behavior 部分中指定一个或多个扩缩策略,当指定多个策略时,允许最大更改量的策略是默认选择的策略,如下示例显示了缩小时的这种行为:
behavior:
scaleDown:
policies:
- type: Pods
value: 4
periodSeconds: 60
- type: Percent
value: 10
periodSeconds: 60
periodSeconds 表示在过去的多长时间内要求策略值为真,第一个策略(Pods)表示允许在一分钟内最多缩容 4 个副本,第二个策略(Percent)表示允许在一分钟内最多缩容当前副本个数的百分之十。
由于默认情况下会选择容许更大程度作出变更的策略,只有 Pod 副本数大于 40 时,第二个策略才会被采用。如果副本数为 40 或者更少,则应用第一��个策略。
例如,如果有 80 个副本,并且目标必须缩小到 10 个副本,那么在第一步中将减少 8 个副本。在下一轮迭代中,当副本的数量为 72 时,10% 的 Pod 数为 7.2,但是这个数字向上取整为 8。在autoscaler 控制器的每个循环中,将根据当前副本的数量重新计算要更改的 Pod 数量,当副本数量低于 40 时,应用第一个策略(Pods),一次减少 4 个副本。
(2)稳定窗口
当用于扩缩的指标不断波动时,稳定窗口用于限制副本计数的波动。自动扩缩算法使用此窗口来推断先前的期望状态并避免对工作负载规模进行不必要的更改。例如,在以下示例中,为 scaleDown 指定了稳定窗口。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
当指标显示目标应该缩容时,自动扩缩算法查看之前计算的期望状态,并使用指定时间间隔内的最大值。在上面的例子中,过去 5 分钟的所有期望状态都会被考虑。
这近似于滚动最大值,并避免了扩缩算法频繁删除 Pod 而又触发重新创建等效 Pod。
(3)默认行为
要使用自定义扩缩,也不需要指定所有字段,只有需要自定义的字段才需要指定。这些自定义值与默认值合并。默认值与HPA 算法中的现有行为匹配。
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
- type: Pods
value: 4
periodSeconds: 15
selectPolicy: Max # Min 意味着会选择影响 Pod 数量最小的策略,Disabled 会关闭对指定方向的缩容
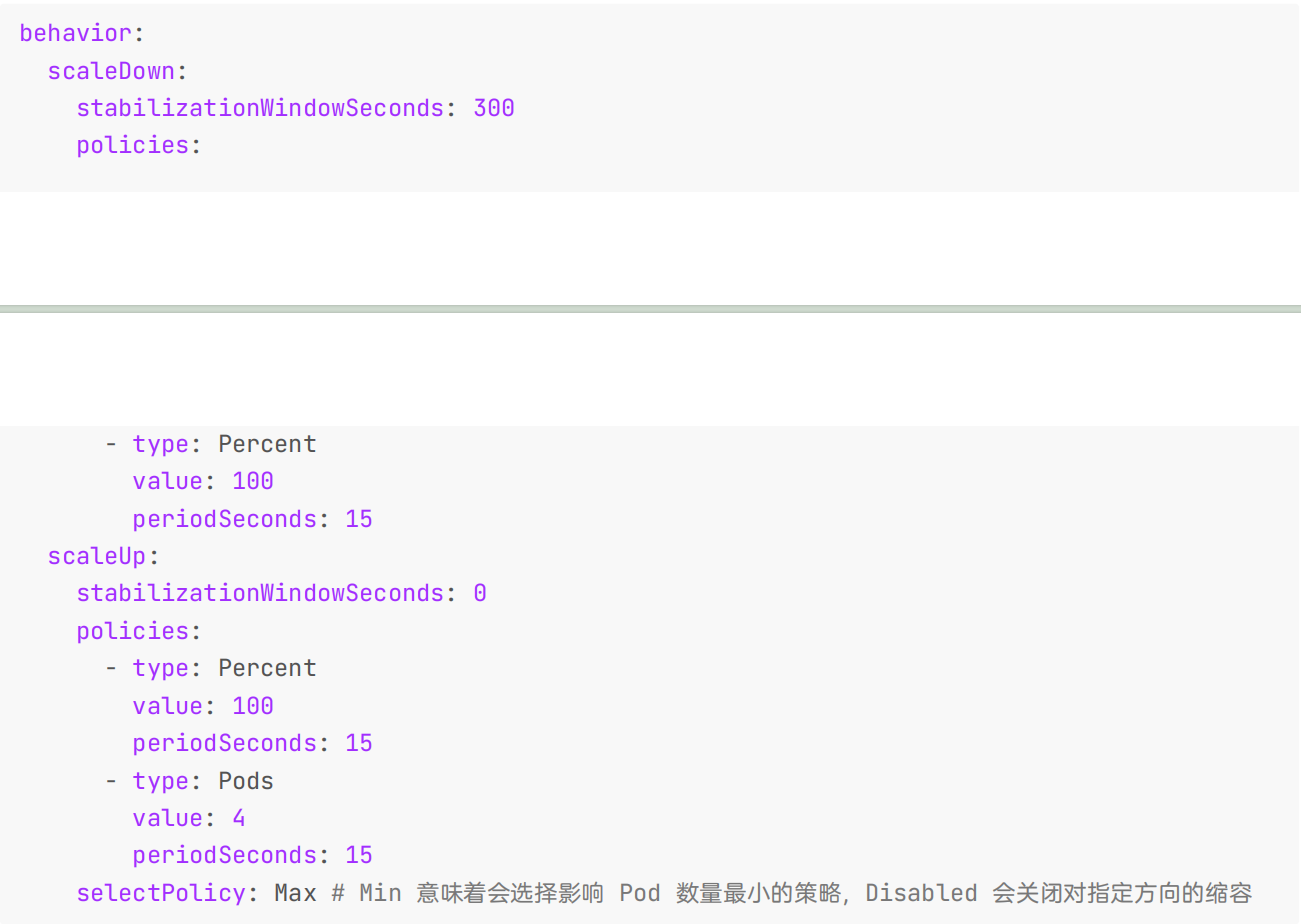
用于缩小稳定窗口的时间为 300 秒(或是 --horizontal-pod-autoscaler-downscale-stabilization 参数设定值)。只有一种缩容的策略,允许 100% 删除当前运行的副本,这意味着扩缩目标可以缩小到允许的最小副本数。对于扩容,没有稳定窗口,当指标显示目标应该扩容时,目标会立即扩容。这里有两种策略,每 15 秒添加 4 个 Pod 或 100%当前运行的副本数,直到 HPA 达到稳定状态。
2、VPA
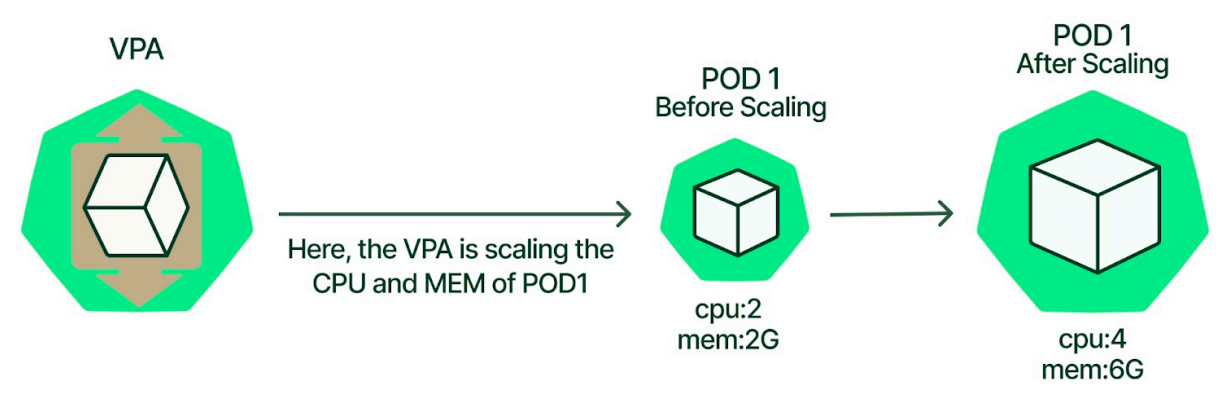
VPA 全称 VerticalPodAutoscaler,即 Pod 的纵向扩缩容,和 HPA 是相对应的,其根据容器资源使用率自动设置CPU 和内存的 requests 及 limit,从而允许在节点上进行适当的调��度,以便为每个 Pod 提供适当的资源。它既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量。我们可以通过 VPA 来自动资源配置提升管理效率、提高集群资源利用率。
vpa:垂直自动扩缩容,我始终在一个pod里面,假设我的memory limits是100Mi,但是现在已经用到了98Mi,如果再大的话就oom了,此时vpa会在垂直方向上提升你的memory limits的大小。这种vpa比较适合一些资源消耗比较大的应用,例如es,你给大了资源浪费,给小了,又不够。所以vpa就派上用场了。当然,vpa不像hpa默认集成在k8s里面的,需要你自己去配置的。
VPA 主要由三个组件组成,分别为 recommender、updater 、admission-controller 。
-
recommender :引入 VerticalPodAutoscaler 对象,其由 Pod 的标签选择器、资源策略(控制 VPA 如何计算资源)、更新策略(控制如何将更改应用于 Pod)和推荐的 Pod 资源组成,其根据 metric-server 获取到的容器指标并观测 OOM事件,计算推荐指标,最终更新 VerticalPodAutoscaler 对象
-
updater:其是负责 Pod 更新的组件。如果 Pod 在 Auto 模式下使用 VPA,则 Updater 可以决定使用推荐器资源对其进行更新。这只是通过驱逐 Pod 以便使用新资源重新创建它来实现的。简单来说,其是根据 pod 的request 中设置的指标和 recommend 计算的推荐指标,在一定条件下驱逐 pod,
-
admission-controller:这是一个 webhook 组件,所有 Pod 创建请求都通过 VPA AdmissionController,如果 Pod 与 VerticalPodAutoscaler 对象匹配,把 recommend 计算出的指标应用到 pod 的request 和 limit,如果 Recommender 不可用,它会回退到 VPA 对象中缓存的推荐。

使用 VPA 主要会用到两个资源: VerticalPodAutoscaler 、VerticalPodAutoscalerCheckpoint。
- VerticalPodAutoscaler:该资源由用户创建,用于设置纵向扩容的目标对象和存储 recommend 组件计算出的推荐指标。
- VerticalPodAutoscalerCheckpoint:该资源由 recommend 组件创建和维护,用于存储指标相关信息,一个vpa 对应的多个容器,每个容器创建一个该资源。
💘 实战:vpa测试-2022.12.25(成功测试)
- 实验环境
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,2个master节点,1个node节点
k8s version:v1.25.4
CONTAINER-RUNTIME:containerd:v1.6.10
- 实验软件
🍓 部署VPA
-
VPA 也需要依赖 metrics-server ,所以也需要提前安装。(这里前面实验已经安装好metrics-server了)
-
然后我们可以通过下面命令来安装 VPA 相关组件。
下载安装包:
git clone https://github.com/kubernetes/autoscaler.git
- 执行安装脚本
cd autoscaler/vertical-pod-autoscaler
./hack/vpa-up.sh

- 修改刚下载的里面镜像地址
默认 VPA 使用的是 k8s.gcr.io 的镜像,如果不能正常拉取镜像,可以重新修改下镜像地址。
[root@master1 hack]#kubectl get po -nkube-system
NAME READY STATUS RESTARTS AGE
…… #可以看到如下3个pod未能正常运行
vpa-admission-controller-64cb9cfb4b-pj8pc 0/1 ContainerCreating 0 81s
vpa-recommender-6fdd69df6c-jbh8z 0/1 ImagePullBackOff 0 81s
vpa-updater-8567bff646-jnmqq 0/1 ErrImagePull 0 81s
#我们来重新修改下镜像地址
☸ ➜ kubectl edit deploy vpa-admission-controller -n kube-system
# ......
# image: k8s.gcr.io/autoscaling/vpa-admission-controller:0.12.0
image: cnych/vpa-admission-controller:0.12.0
# ......
☸ ➜ kubectl edit deploy vpa-recommender -n kube-system
# ......
# image: k8s.gcr.io/autoscaling/vpa-recommender:0.12.0
image: cnych/vpa-recommender:0.12.0
# ......
☸ ➜ kubectl edit deploy vpa-updater -n kube-system
# ......
# image: k8s.gcr.io/autoscaling/vpa-updater:0.12.0
image: cnych/vpa-updater:0.12.0
- 出现了个报错……
这里的vpa-admission-controller pod一直起不来……

记得当时在执行完安装脚本后报错:……


但是,老师当时都没错呀……
但是,这里是配置过这个tls证书的呀……
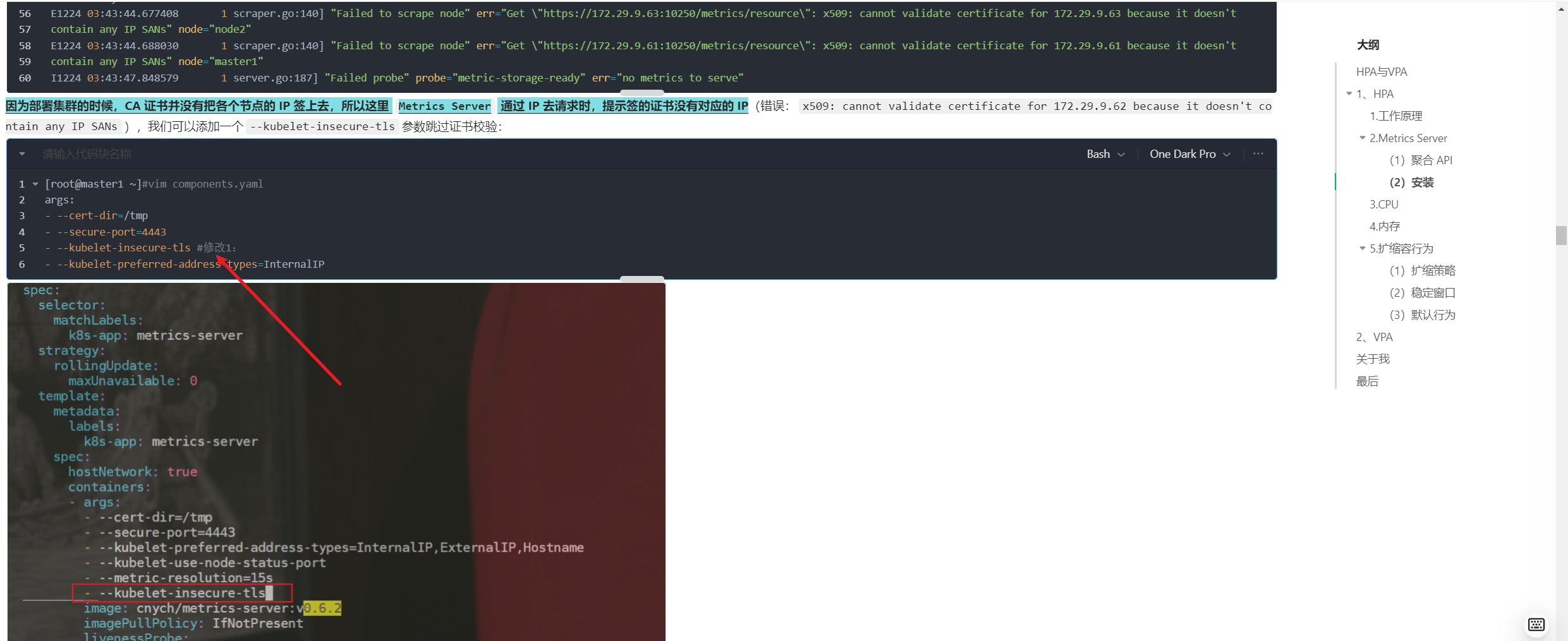
这里再次执行vpa-up.sh脚本时,依然报一样的错误:

这里开始升级下openssl版本:
当前openssl版本:
[root@master1 hack]#ssh -V
OpenSSH_7.4p1, OpenSSL 1.0.2k-fips 26 Jan 2017
对当前3台虚机做快照,本次直接升级ssh版本;
通过如下脚本来升级ssh;

升级后ssh�版本如下:
[root@master1 ~]#ssh -V
OpenSSH_8.6p1, OpenSSL 1.1.1g 21 Apr 2020
3台升级完ssh后,我们再次来执行下安装脚本:

可以看到,此时没报错了哦😘
- 部署完成后会在 kube-system 命名空间下面启动 3 个 Pod:
[root@master1 ~]#kubectl get po -nkube-system
NAME READY STATUS RESTARTS AGE
……
vpa-admission-controller-8599bb878d-q25wx 1/1 Running 0 2d5h
vpa-recommender-6bf6dd6795-wchjc 1/1 Running 0 2d5h
vpa-updater-697666f758-6vl75 1/1 Running 0 2d5h
🍓 使用VPA
接下来我们就可以来了解下如何使用 VPA。
- 首先创建一个如下所示的普通的应用:
# vpa-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: vpa-demo
spec:
replicas: 1
selector:
matchLabels:
app: vpa
template:
metadata:
labels:
app: vpa
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
cpu: 20m
memory: 25Mi
- 直接应用该资源即可:
[root@master1 ~]# kubectl apply -f vpa-demo.yaml
deployment.apps/vpa-demo created
[root@master1 ~]#kubectl get po -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vpa-demo-669997c575-lb8lf 1/1 Running 0 36s 10.244.1.57 node1 <none> <none>
- 接下来我们就可以创建一个 VPA 对象,我们这里使用 updateMode: "Off" 模式,其仅计算资源的推荐而不应用 Pod:
#nginx-vpa-test.yaml
apiVersion: autoscaling.k8s.io/v1beta2
kind: VerticalPodAutoscaler
metadata:
name: nginx-vpa-test
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: vpa-demo
updatePolicy:
updateMode: "Off" # 必须带双引号
resourcePolicy:
containerPolicies:
- containerName: nginx
minAllowed:
cpu: 250m
memory: 100Mi
maxAllowed:
cpu: 2000m
memory: 2048Mi
- 同样直接应用该资源对象即可:
[root@master1 ~]#kubectl apply -f nginx-vpa-test.yaml
Warning: autoscaling.k8s.io/v1beta2 API is deprecated
verticalpodautoscaler.autoscaling.k8s.io/nginx-vpa-test created
[root@master1 ~]#
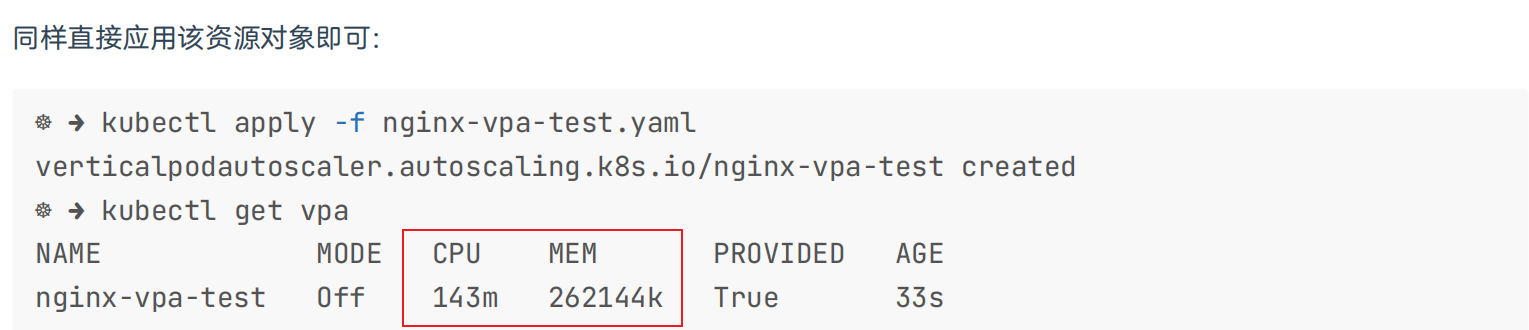
[root@master1 ~]#kubectl get vpa #这里稍等一会儿就有数值了……
NAME MODE CPU MEM PROVIDED AGE
nginx-vpa-test Off 8s
[root@master1 hack]#kubectl get vpa
NAME MODE CPU MEM PROVIDED AGE
nginx-vpa-test Off 250m 262144k True 3m34s
[root@master1 hack]#kubectl describe vpa nginx-vpa-test
……
Status:
Conditions:
Last Transition Time: 2022-12-27T13:33:54Z
Status: True
Type: RecommendationProvided
Recommendation:
Container Recommendations:
Container Name: nginx
Lower Bound:
Cpu: 250m
Memory: 262144k
Target: #推荐值
Cpu: 250m
Memory: 262144k
Uncapped Target:
Cpu: 25m
Memory: 262144k
Upper Bound:
Cpu: 2
Memory: 2Gi
Events: <none>
[root@master1 hack]#
我们可以看到推荐由四部分组成,其中 lower 为下限值,target 为推荐值,而 upper 为上限值,其中 uncap 为实际值。
- 同样我们可以来对应用进行压测,创建一个 busybox 的 Pod,循环访问上面创建的 Pod:
[root@master1 ~]#kubectl run -it --image busybox test-vpa --restart=Never --rm /bin/sh
while true; do wget -q -O- http://10.244.1.57; done
- 此时我们可以观察 VPA 给出的推荐值:
[root@master1 hack]#kubectl get vpa
NAME MODE CPU MEM PROVIDED AGE
nginx-vpa-test Off 250m 262144k True 11m
[root@master1 hack]#kubectl describe vpa nginx-vpa-test
……
Last Transition Time: 2022-12-27T13:33:54Z
Status: True
Type: RecommendationProvided
Recommendation:
Container Recommendations:
Container Name: nginx
Lower Bound:
Cpu: 250m
Memory: 262144k
Target:
Cpu: 250m
Memory: 262144k
Uncapped Target:
Cpu: 163m
Memory: 262144k
Upper Bound:
Cpu: 2
Memory: 1169541958
Events: <none>
从上面可以看到给出的 Target 为 143m ,因为设置 updateMode:"Off",所以不会应用到 Pod。
VPA 中的 UpdateMode 有多个有效的选项。他们是:
- Off:VPA 只会提供建议,并且不会自动更改资源要求。
- Initial:VPA 只在 Pod 创建时分配资源请求,以后不会改变。
- Recreate :VPA 在 Pod 创建时分配资源请求,并通过驱逐和重新创建现有 Pod 来更新它们。
- Auto :它根据建议重新创建 Pod。
⚠️ 注意:
我这里的实验现象有些问题,没达到预期……
这里的推荐值怎么一直和Lower一致呢,即使最后压测之后,也是这样的现象……
按理说,正常的现象应该如下:

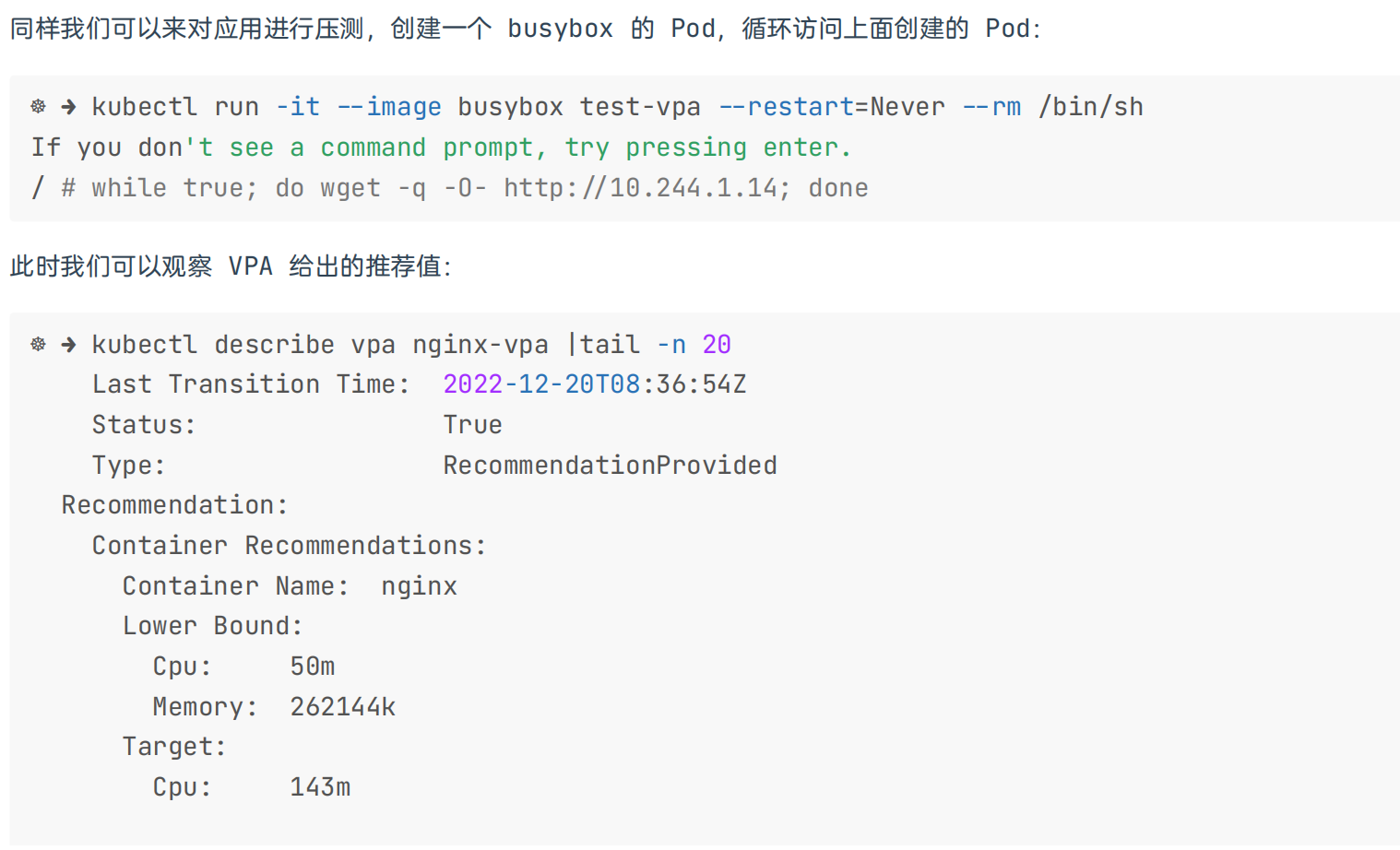

当然 VPA 也并不是万能的,具有一些局限性,在使用的时候以下注意事项值得我们关注:
-
不要将 VPA 与 HPA 一起使用,后者基于相同的资源指标(例如 CPU 和 MEMORY 使用率)进行缩放。这是因为当指标(CPU/MEMORY)达到其定义的阈值时,VPA 和 HPA 将同时发生缩放事件,这可能会产生未知的副作用并可能导致问题。
-
VPA 可能会推荐比集群中可用的资源更多的资源,从而导致 Pod 未分配给节点(由于资源不足),因此永远不会运行。
-
VPA 不会驱逐不在控制器下运行的 pod,驱逐可以单独处理
为了能够自动资源配置提升管理效率、提高集群资源利用率,除了 VPA 之外,我们后续还会学习其他更智能更适合生产环境使用的工具,不过 VPA 的实现思路值得我们学习。
FAQ
HPA与VPA区别

如何应对突发流量
大佬说:
AutoScale如果是突发高流量,那没办法,可能还没等到扩容,你就死掉了。可能这种情况,你还要预判。
这种大到一下就打死了,可能还是很难搞……因为很难预测(例如娱乐圈的吃瓜哈哈)。
它是基于metric来决定的,希望将来加一些预测功能,比如说突然出现了某一个趋势,它能预测到接下来再不扩容,就死掉了。但至少目前,它是基于现有的Metric.
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 语雀
https://www.yuque.com/xyy-onlyone
https://www.yuque.com/xyy-onlyone/exkgza?# 《语雀博客》
🍀 博客


🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421

🍀 知乎
https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!

1