Terraform排错
Terraform排错
TS:terraform.lock.hcl锁文件故障-2024.6.19(已解决)
1、报错现象
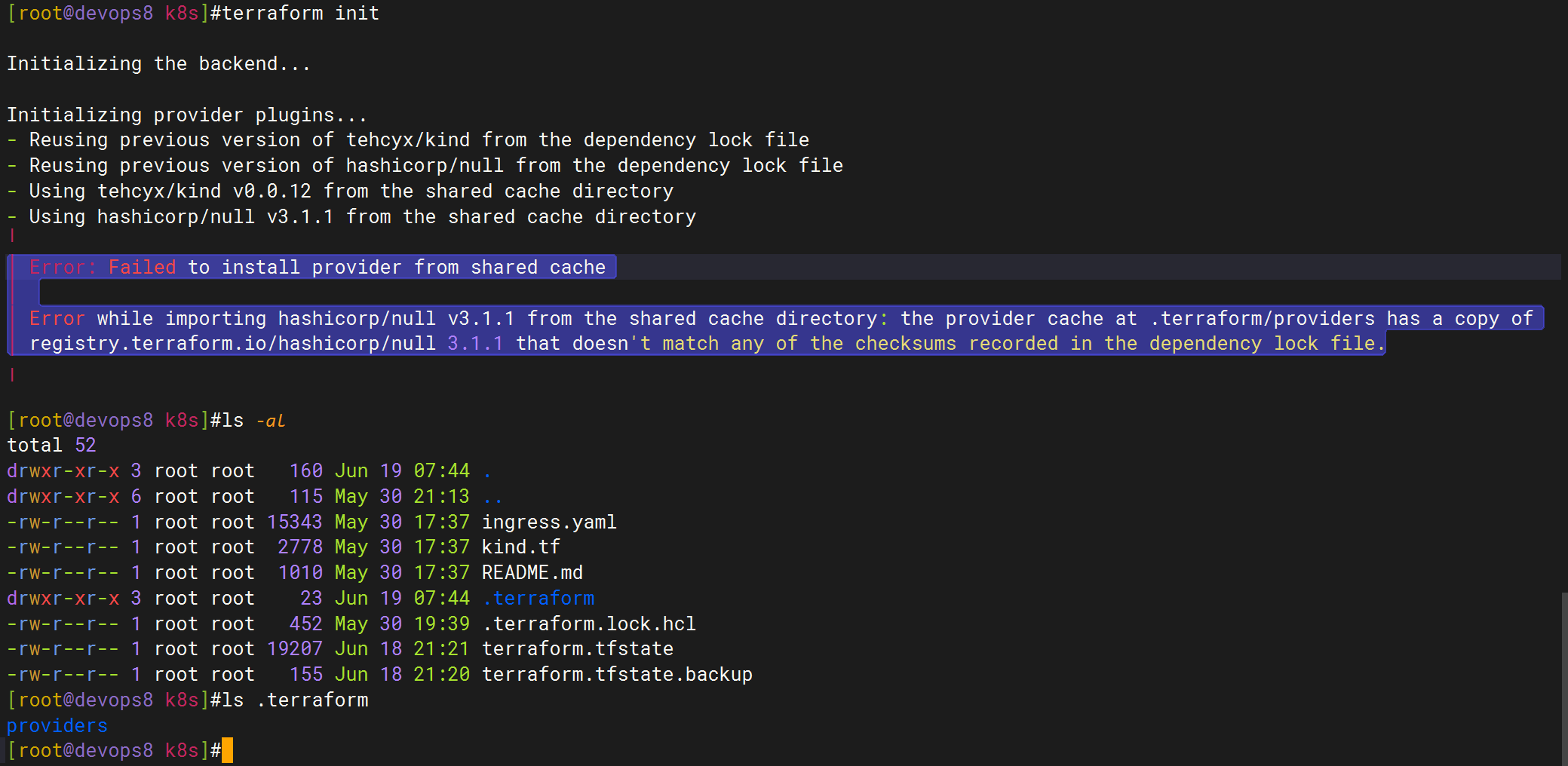
╷
│ Error: Failed to install provider from shared cache
│
│ Error while importing hashicorp/null v3.1.1 from the shared cache directory: the provider cache at .terraform/providers has a copy of
│ registry.terraform.io/hashicorp/null 3.1.1 that doesn't match any of the checksums recorded in the dependency lock file.
╵
2、gpt
这个错误表明在尝试从共享缓存目录安装 hashicorp/null 提供程序版本 3.1.1 时出现了问题。具体来说,.terraform/providers 目录中的提供程序缓存的校验和不匹配 terraform.lock.hcl 文件中记录的任何校验和。
为了解决这个问题,你可以尝试以下步骤:
-
检查锁文件:打开
terraform.lock.hcl文件,并验证hashicorp/null版本3.1.1的校验和是否与预期相符。如果锁文件中的校验和与缓存中的不匹配,你需要更新缓存或锁文件。 -
清理缓存:你可以尝试删除
.terraform/providers目录中的hashicorp/null提供程序缓存。然后,当你再次运行terraform init时,Terraform 将重新下载并验证提供程序。rm -rf .terraform/providers/registry.terraform.io/hashicorp/null/3.1.1/* -
重新初始化:删除缓存后,运行
terraform init命令来重新初始化你的工作目录。这将导致 Terraform 重新下载提供程序并确保其校验和与锁文件匹配。terraform init -
检查网络连接:确保你的计算机可以访问互联网,并且没有任何防火墙或代理设置阻止 Terraform 下载提供程序。
-
检查版本:确保你的
terraform.lock.hcl文件中指定的hashicorp/null版本3.1.1是正确的,并且该版本在 Terraform 注册表中仍然可用。
如果上述步骤仍然无法解决问题,你可以考虑更新 terraform.lock.hcl 文件中的提供程序版本,或者检查是否有关于 hashicorp/null 提供程序的已知问题或更新。在某些情况下,提供程序的维护者可能已经发布了修复问题的更新版本。
3、测试
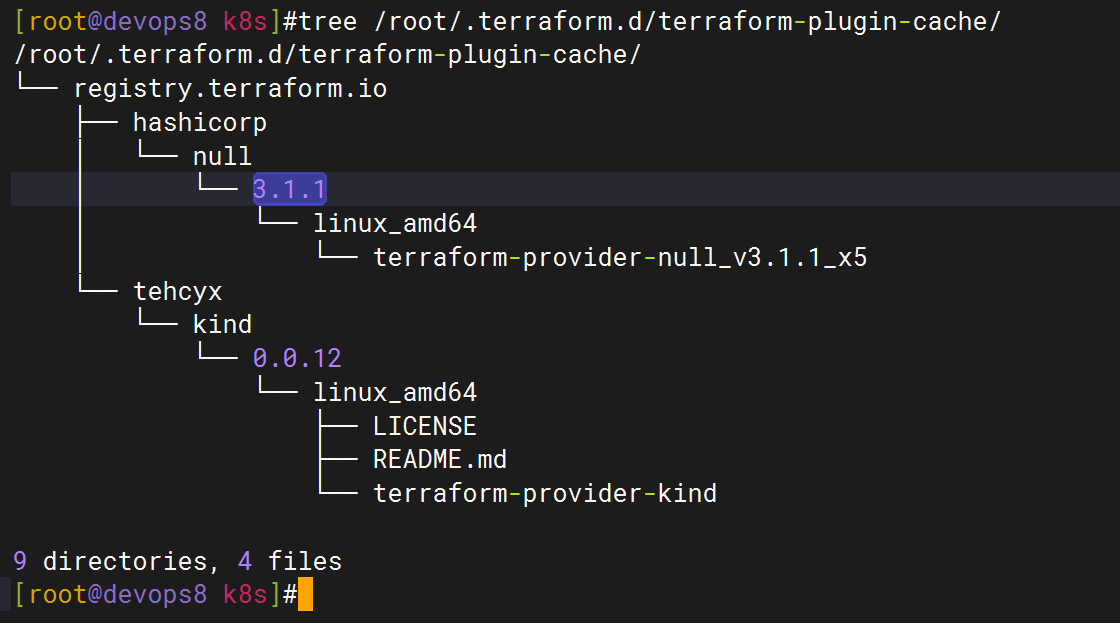
[root@devops8 k8s]#ls -al
total 52
drwxr-xr-x 3 root root 160 Jun 19 07:44 .
drwxr-xr-x 6 root root 115 May 30 21:13 ..
-rw-r--r-- 1 root root 15343 May 30 17:37 ingress.yaml
-rw-r--r-- 1 root root 2778 May 30 17:37 kind.tf
-rw-r--r-- 1 root root 1010 May 30 17:37 README.md
drwxr-xr-x 3 root root 23 Jun 19 07:44 .terraform
-rw-r--r-- 1 root root 452 May 30 19:39 .terraform.lock.hcl
-rw-r--r-- 1 root root 19207 Jun 18 21:21 terraform.tfstate
-rw-r--r-- 1 root root 155 Jun 18 21:20 terraform.tfstate.backup
[root@devops8 k8s]#cat .terraform.lock.hcl
# This file is maintained automatically by "terraform init".
# Manual edits may be lost in future updates.
provider "registry.terraform.io/hashicorp/null" {
version = "3.1.1"
constraints = "3.1.1"
hashes = [
"h1:fcb4bK9o7kOVwvyFzhqUH/yHxDMbP0N3Z5/Jrz+XraM=",
]
}
provider "registry.terraform.io/tehcyx/kind" {
version = "0.0.12"
constraints = "0.0.12"
hashes = [
"h1:rmC++QY2+7N4DXL8CPYz8RLzTUzpZFMZjQviApOjPSE=",
]
}
清理缓存(失败)
-
清理缓存:你可以尝试删除
.terraform/providers目录中的hashicorp/null提供程序缓存。然后,当你再次运行terraform init时,Terraform 将重新下载并验证提供程序。rm -rf .terraform/providers/registry.terraform.io/hashicorp/null/3.1.1/*
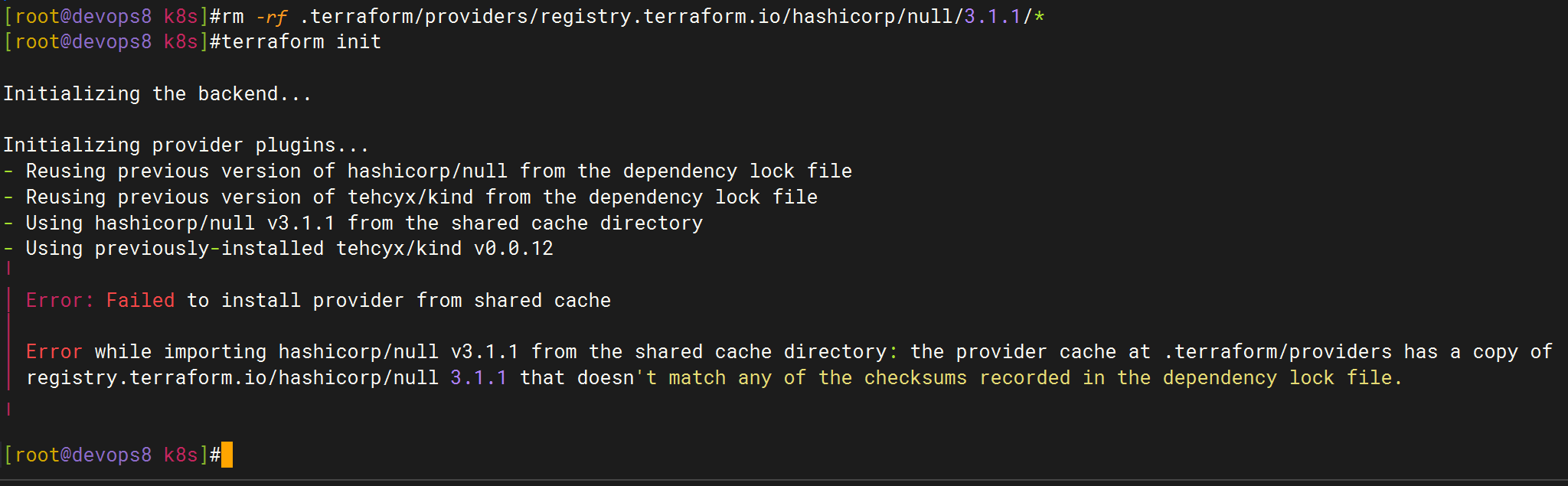
直接删除锁文件(已解决)
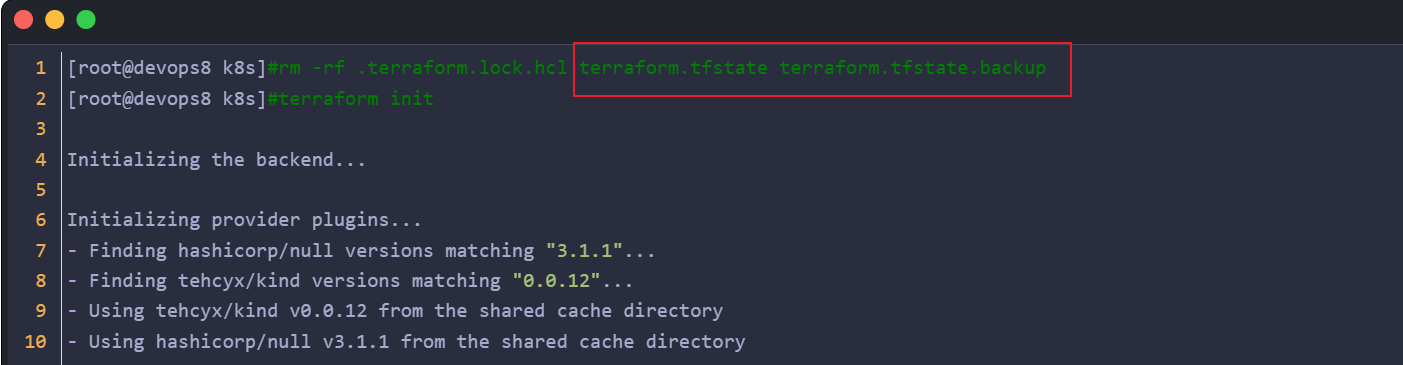
[root@devops8 k8s]#rm -rf .terraform.lock.hcl terraform.tfstate terraform.tfstate.backup
[root@devops8 k8s]#terraform init
Initializing the backend...
Initializing provider plugins...
- Finding hashicorp/null versions matching "3.1.1"...
- Finding tehcyx/kind versions matching "0.0.12"...
- Using tehcyx/kind v0.0.12 from the shared cache directory
- Using hashicorp/null v3.1.1 from the shared cache directory
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
[root@devops8 k8s]#
TS:误删Terraform 状态文件terraform.tfstate-2024.6.19(已解决)
1、报错现象
[root@devops8 k8s]#terraform destroy --auto-approve
Changes to Outputs:
You can apply this plan to save these new output values to the Terraform state, without changing any real infrastructure.
Destroy complete! Resources: 0 destroyed.
[root@devops8 k8s]#

2、gpt
从你提供的命令和输出信息来看,你执行了 terraform destroy --auto-approve 命令来尝试销毁通过 Terraform 创建的基础设施资源。然而,输出显示 "Destroy complete! Resources: 0 destroyed.",这意味着没有资源被销毁,可能是因为当前 Terraform 状态中没有需要销毁的资源。
以下是一些可能的原因和建议的后续步骤:
-
状态为空:如果当前的 Terraform 状态文件(通常是
terraform.tfstate)为空或者不包含任何资源,那么terraform destroy命令将不会销毁任何东西。你可以通过运行terraform state list来检查当前状态中是否存在资源。terraform state list
-
状态文件丢失或损坏:如果状态文件丢失或损坏,Terraform 可能无法识别需要销毁的资源。在这种情况下,你需要恢复状态文件或重新应用配置。
淦:刚才自己把这些文件给删除了……
-
配置更改:如果你最近更改了 Terraform 配置文件,并且这些更改导致了资源的删除或重新定义,那么可能需要重新应用配置以更新状态文件。
-
状态后端同步问题:如果你使用远程状态后端(如 AWS S3、Google Cloud Storage 等),请确保状态文件已正确同步,并且你正在使用正确的状态文件。
-
权限问题:确保你有足够的权限来销毁资源。如果资源位于云服务提供商(如 AWS、Azure、GCP 等),请检查你的凭据和权限设置。
-
重新初始化:在某些情况下,重新运行
terraform init命令可以帮助解决状态相关的问题。terraform init
如果上述步骤都无法解决问题,你可能需要更详细地检查你的 Terraform 配置和状态文件,以确定为什么没有资源被销毁。如果需要进一步的帮助,请提供更多的上下文信息,例如你的 Terraform 配置文件和状态文件的内容。
3、解决办法
额,直接删除集群重新测试吧
kind delete cluster --name devopscluster
重建成功。
4、总结
terraform生成的一些文件千万(terraform.tfstate)不能删除哦,否则会影响terraform正常使用的。
[root@devops8 ~]#cd myiac-gitee/k8s/
[root@devops8 k8s]#ls
ingress.yaml kind.tf README.md terraform.tfstate terraform.tfstate.backup
[root@devops8 k8s]#ls -al
total 52
drwxr-xr-x 3 root root 160 Jun 19 08:04 .
drwxr-xr-x 6 root root 115 May 30 21:13 ..
-rw-r--r-- 1 root root 15343 May 30 17:37 ingress.yaml
-rw-r--r-- 1 root root 2778 May 30 17:37 kind.tf
-rw-r--r-- 1 root root 1010 May 30 17:37 README.md
drwxr-xr-x 3 root root 23 Jun 19 07:44 .terraform
-rw-r--r-- 1 root root 452 Jun 19 07:53 .terraform.lock.hcl
-rw-r--r-- 1 root root 19207 Jun 19 08:04 terraform.tfstate
-rw-r--r-- 1 root root 155 Jun 19 08:04 terraform.tfstate.backup