正则表达式
正则表达式

目录
[toc]
1、基��本正则表达式
REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能,类似于增强版的通配符功能,但与通配符不同,通配符功能是用来处理文件名,而正则表达式是处理文本内容中字符。
正则表达式被很多程序和开发语言所广泛支持:vim, less,grep,sed,awk, nginx,mysql 等。
正则表达式分两类:
(1)基本正则表达式:BRE (2)扩展正则表达式:ERE
正则表达式引擎:采用不同算法,检查处理正则表达式的软件模块,如:PCRE(Perl Compatible RegularExpressions)
正则表达式的元字符分类:字符匹配、匹配次数、位置锚定、分组
帮助:man 7 regex
注意:经常看到老师这里使用正则表达式会用单括号' '给括起来的,这个请注意。
1.字符匹配
. 匹配任意单个字符,可以是一个汉字(注意)
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z] #[]中括号括起来代表任意的一个字符;
[^] 匹配指定范围外的任意单个字符,示例:[^wang] #注意,脱字符^看放在哪里,放在[]外面,就代表行首;放在里面,就代表排除的意思;
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
范例:元字符. 和 []
[root@test ~]# ls /etc/rc
rc0.d/ rc1.d/ rc2.d/ rc3.d/ rc4.d/ rc5.d/ rc6.d/ rc.d/ rc.local
[root@test ~]# ls /etc/ |grep 'rc[.0-6]'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@test ~]# ls /etc/ |grep 'rc[.0-6].'
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
rc.d
rc.local
[root@test ~]# ls /etc/ |grep 'rc[.0-6]\.' #注意最后的一个元字符.,代表匹配任意单个字符,输出满足条件,自然就正常输出了。
rc0.d
rc1.d
rc2.d
rc3.d
rc4.d
rc5.d
rc6.d
[root@test ~]#
2.匹配次数
用在要指定次数的字符后面,用于指定前面的字符要出现的次数。
* 匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次,即:可有可无
\+ 匹配其前面的字符至少1次,即:肯定有,>=1
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次,<=n
\{n,\} 匹配前面的字符至少n次
特别注意:单词的区分:字母,数字,下划线连起来的算一个单词,除此之外,都是单词的分界线:';' '-'等。
范例:? 匹配其前面的字符0或1次,即:可有可无
[root@test ~]# echo /etc/ |grep "/etc/\?"
/etc/
[root@test ~]# echo /etc |grep "/etc/\?"
/etc
[root@test ~]#
3.位置锚定
位置锚定可以用于定位出现的位置。
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定,用于单词模式的右侧
\<PATTERN\> 匹配整个单词
4.分组其它
1.分组
分组:() 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名
方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符。
示例:
\(string1\(string2\)\)
\1 :string1\(string2\)
\2 :string2
注意: 后向引用 引用前面的分组括号中的模式所匹配字符,而非模式本身。
范例:分组引用的搜索替代用的最多了。
测试1:
#vim新建一个新文件:
[root@localhost ~]# vim fa.txt
root root root
rabt rabt rxyt
#现��在想在vim编辑界面如何将root替换为rooter?
:%s/root/root/g #扩展命令行模式下
#替换后效果如下:
rooter rooter rooter
rabt rabt rxyt
测试2:
#vim新建一个新文件:
[root@localhost ~]# vim fa.txt
root root root
rabt rabt rxyt
#现在想在vim编辑界面如何将r..t替换为admin(r..t)er?
:%s#\(r..t\)#admin\1er#g #扩展命令行模式下
#替换后效果如下:
adminrooter adminrooter adminrooter
adminrabter adminrabter adminrxyter
2.或者
或者:\|
示例:
a\|b #a或b
C\|cat #C或cat
\(C\|c\)at #Cat或cat
范例:排除空行和#开头的行
[root@localhost ~]# cat /etc/profile|wc -l
76
[root@localhost ~]# grep '^#' /etc/profile|wc -l
12
[root@localhost ~]# grep '^$' /etc/profile|wc -l
11
[root@localhost ~]# 因此,/etc/profile文件总共有效配置行数为:76-12-11=53行
方法1:多次使用grep
[root@localhost ~]# grep -v '^#' /etc/profile|grep -v '^$'|wc -l
方法2:使用或'\|'
[root@localhost ~]# grep -v '^#\|^$' /etc/profile|wc -l
方法3:使用分组()和或'\|'
[root@localhost ~]# grep -v '^\(#\|$\)' /etc/profile|wc -l
方法4:使用[]和^
[root@localhost ~]# grep ^[^#] /etc/profile|wc -l #[]中括号括起来代表任意的一个字符,空行是一个字符都没有直接过滤掉了;
方法5:扩展正则表达式
[root@localhost ~]# grep -Ev '^(#|$)' /etc/profile|wc -l
[root@localhost ~]# egrep -v '^(#|$)' /etc/profile|wc -l
范例:vim中扩展命令行模式+正则表达式
[root@localhost ~]# vim fstab #测试文件如下
UUID=ce3584e6-bbbb-4a68-9203-c0857ad53d84 /boot xfs defaults 0 0
UUID="b4484a71-144b-4426-86be-48f05a401b58" /data11 xfs defaults 0 0
UUID="b4484a71-144b-4426-86be-48f05a401b58" /data11 xfs defaults 0 0
UUID="b4484a71-144b-4426-86be-48f05a401b58" /data11 xfs defaults 0 0
UUID="b4484a71-144b-4426-86be-48f05a401b58" /data11 xfs defaults 0 0
#添加注释:
方法1:
:%s/^UUID/#UUID/g
方法2:
:%s/^\(UUID\)/#\1/g
#去除注释:
方法1:
:%s/^#//g
方法2:
:%s/^#\(.*\)/\1/g
范例:
-o, --only-matching show only the part of a line matching PATTERN
[root@localhost ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 919540 0 919540 0% /dev
tmpfs 931552 0 931552 0% /dev/shm
tmpfs 931552 9800 921752 2% /run
tmpfs 931552 0 931552 0% /sys/fs/cgroup
/dev/mapper/centos-root 49250820 1815228 47435592 4% /
/dev/sdl1 2086912 32992 2053920 2% /data11
/dev/sda1 1038336 152744 885592 15% /boot
tmpfs 186312 0 186312 0% /run/user/0
[root@localhost ~]# df|grep '^/dev/sd'|grep -o '[0-9]\{1,3\}%'
2%
15%
正则表达式练习
1、显示/proc/meminfo文件中以大小s开头的行(要求:使用两种方法) 2、显示/etc/passwd文件中不以/bin/bash结尾的行
3、显示用户rpc默认的shell程序
4、找出/etc/passwd中的两位或三位数
5、显示CentOS7的/etc/grub2.cfg文件中,至少以一个空白字符开头的且后面有非空白字符的行
6、找出“netstat -tan”命令结果中以LISTEN后跟任意多个空白字符结尾的行
7、显示CentOS7上所有UID小于1000以内的用户名和UID
8、添加用户bash、testbash、basher、sh、nologin(其shell为/sbin/nologin),找出/etc/passwd用户
名和shell同名的行
9、利用df和grep,取出磁盘各分区利用率,并从大到小排序
2、扩展正则表达式
1.字符匹配
. 任意单个字符
[wang] 指定范围的字符
[^wang] 不在指定范围的字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
2.匹配次数
* 匹配前面字符任意次
? 0或1次
+ 1次或多次
{n} 匹配n次
{m,n} 至少m,至多n次
3.位置锚定
^ 行首
$ 行尾
\<, \b 语首 #这里注意,还是有\的,和基本正则唯一不同的地方。
\>, \b 语尾
4.分组其它
() 分组
后向引用:\1, \2, ...
| 或者
a|b #a或b
C|cat #C或cat
(C|c)at #Cat或cat
扩展正则表达式练习
1、显示三个用户root、mage、wang的UID和默认shell
2、找出/etc/rc.d/init.d/functions文件中行首为某单词(包括下划线)后面跟一个小括号的行
3、使用egrep取出/etc/rc.d/init.d/functions中其基名
4、使用egrep取出上面路径的目录名
5、统计last命令中以root登录的每个主机IP地址登录次数
6、利用扩展正则表达式分别表示0-9、10-99、100-199、200-249、250-255
7、显示ifconfifig命令结果中所有IPv4地址
8、将此字符串:welcome to magedu linux 中的每个字符去重并排序,重复次数多的排到前面
案例
案例:nginx强制跳转https
示例语句分析
rewrite ^(.*)$ https://$server_name$1 permanent;
^(.*)$
-
^: 表示匹配字符串的开头。 -
(.*):.表示匹配任意一个字符(除换行符外)。*表示匹配前面的字符任意次(包括0次)。- 括号
()是一个捕获组,用于捕获匹配到的内容。
-
$: 表示匹配字符串的结尾。
因此,^(.*)$ 表示匹配整个字符串,并将其捕获到第一个捕获组中。
https://$server_name$1
https://: 表示重定向后的协议是HTTPS。$server_name: Nginx变量,表示当前请求的服务器名称(即配置中的server_name)。$1: 捕获组引用,引用前面正则表达式中第一个捕获组的内容(即整个URI)。
这部分合在一起表示,重定向到的URL为 https:// 加上服务器名称以及请求的URI。
permanent
permanent: 表示HTTP 301永久重定向。这告诉浏览器和搜索引擎,这个重定向是永久性的,应更新其记录。
完整语句的含义
rewrite ^(.*)$ https://$server_name$1 permanent;
这条语句的作用是将所有匹配 ^(.*)$ 正则表达式的请求(即所有请求)重定向到 HTTPS 协议,并保持请求的URI不变,同时返回 HTTP 301(永久重定向)状态码。
案例:排除掉空行和#开头的行**(常用)**
[root@linux ~]# cat test.txt
123
456
789
# 10 11 12
13 14 15
# love you
[root@linux ~]#
##方法1
[root@linux ~]# grep ^[^#] test.txt ##注意:^[^#]这个也把空行给排除了,奇怪呀……
123
456
789
13 14 15
##方法2
[root@linux ~]# grep -v '^$' test.txt|grep -v '^#'
123
456
789
13 14 15
[root@linux ~]#
##参数说明:
^$ 空行
[^] 匹配指定范围外的任意单个字符,示例:[^wang] #注意,脱字符^看放在哪里,放在[]外面,就代表行首;放在里面,就代表排除的意思;
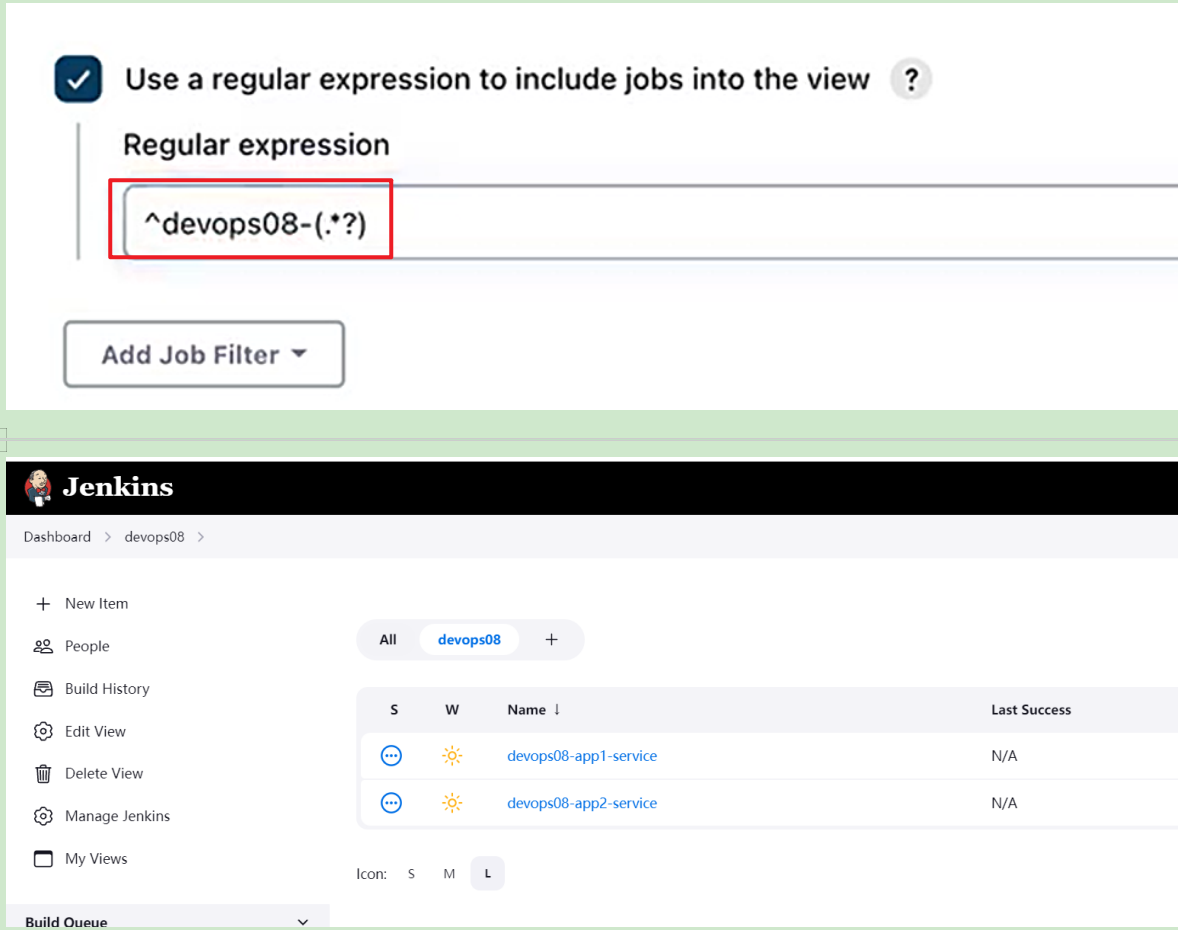
范例:jenins里视图使用
^devops08-(.*?)
#说明
. 匹配任意单个字符,可以是一个汉字(注意)
* 匹配前面字符任意次数
? 0或1次
FAQ
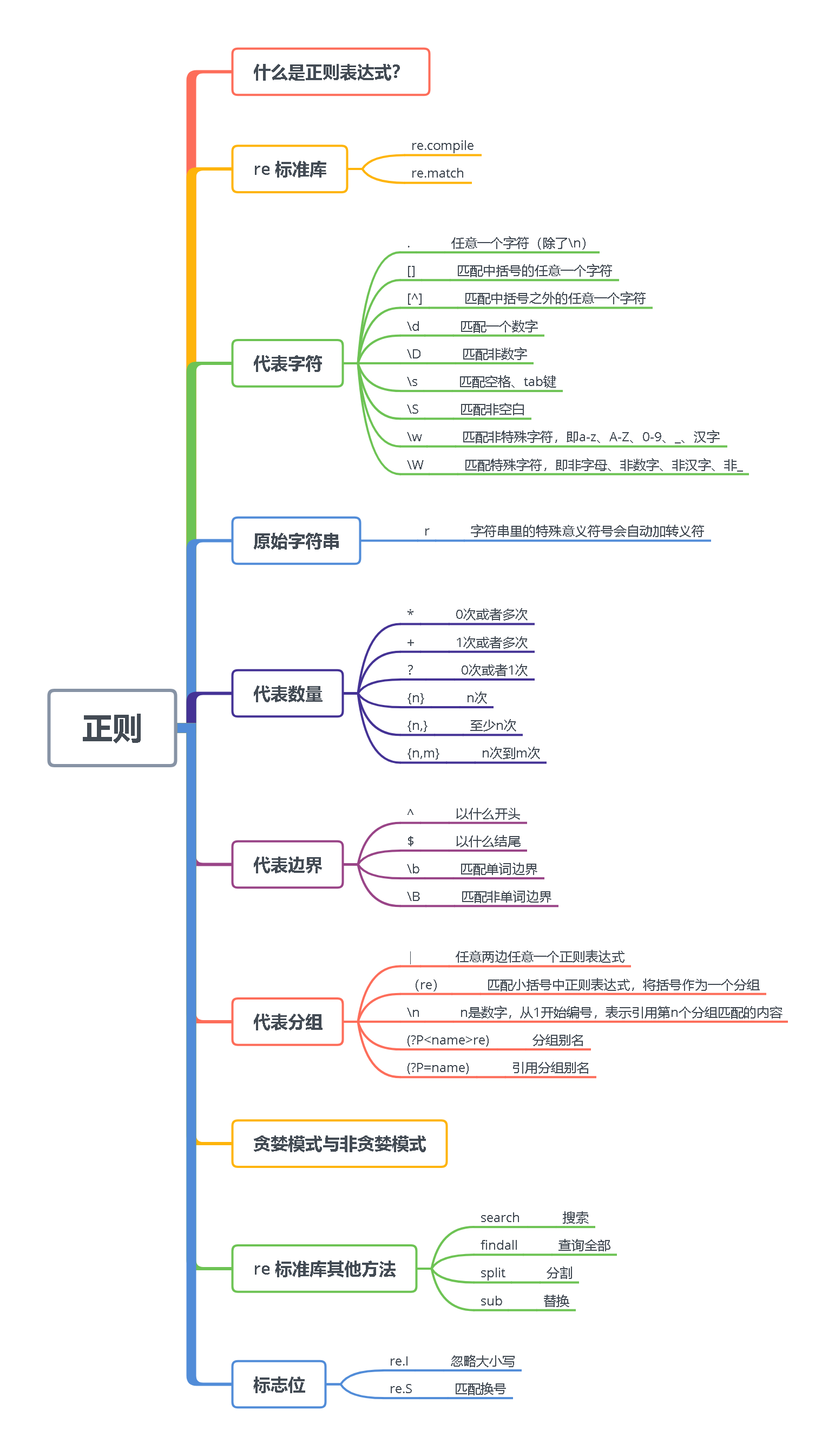
正则表达式 思维导图
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 个人主页:
🍀 知识库:
https://onedayxyy.cn/docusaurus/
🍀 博客:
🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
🍀 知乎
https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!