Linux基础面试题
Linux基础面试题

华为虚拟化(FusiercCompute)
案例

案例
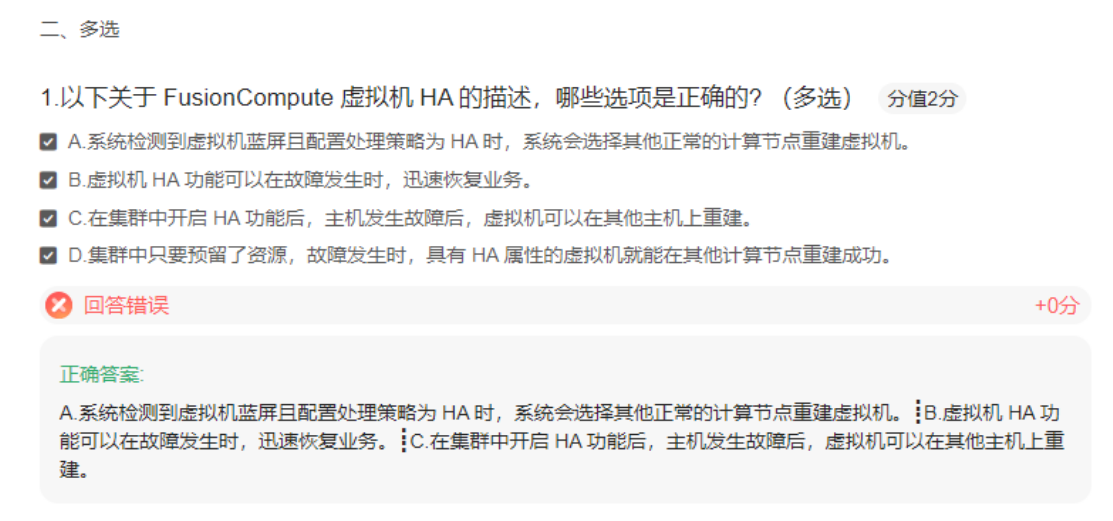
案例
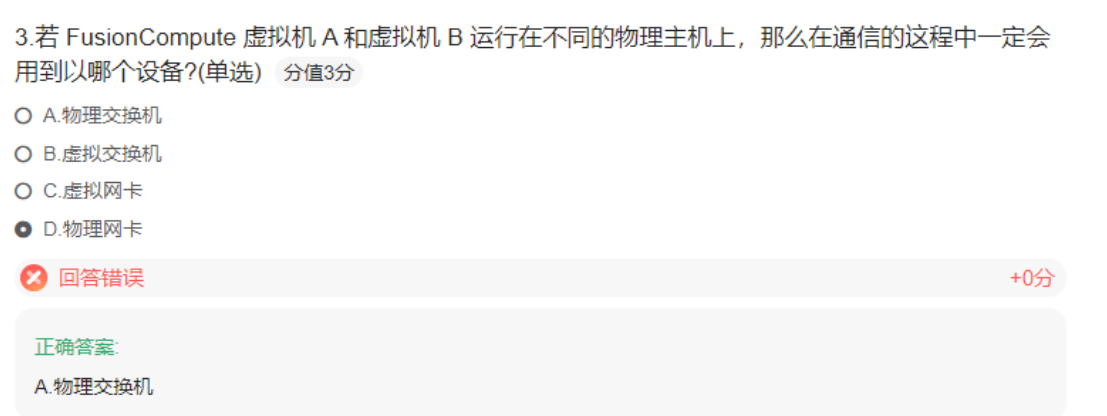
案例:聚合网口
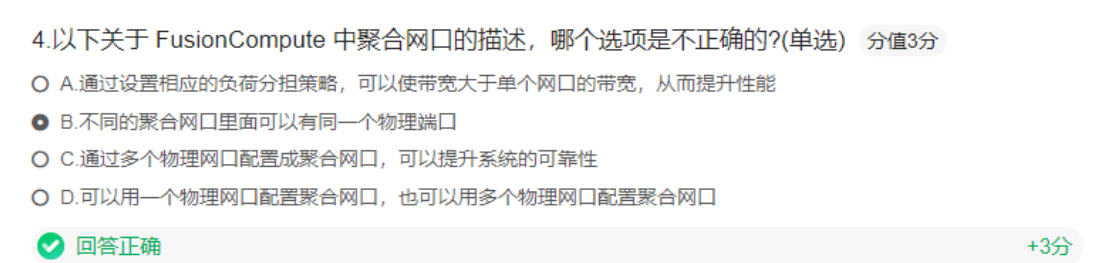
案例
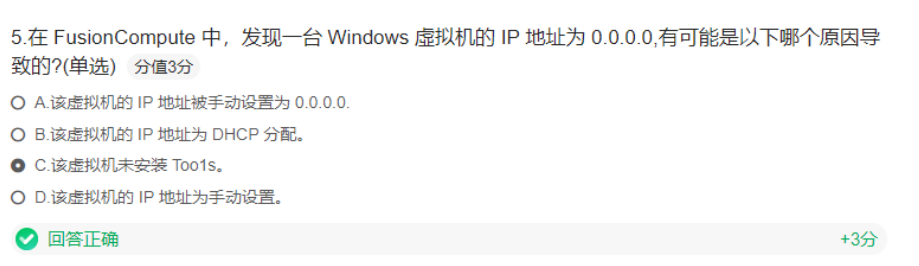
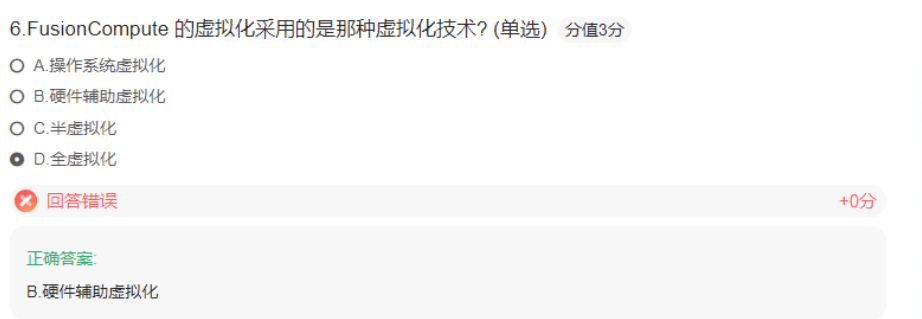
案例:硬件辅助虚拟化
案例
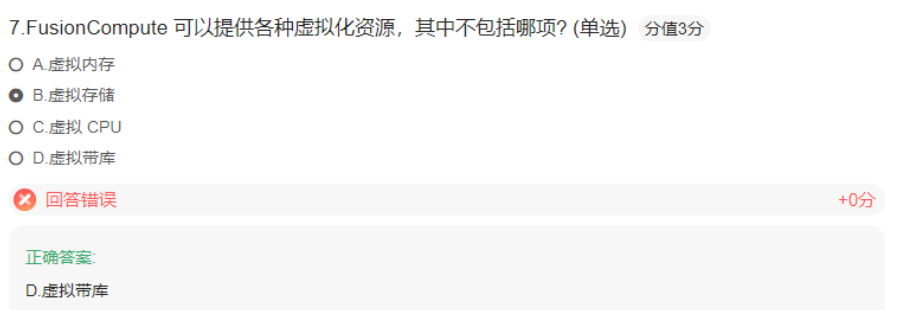
存储类
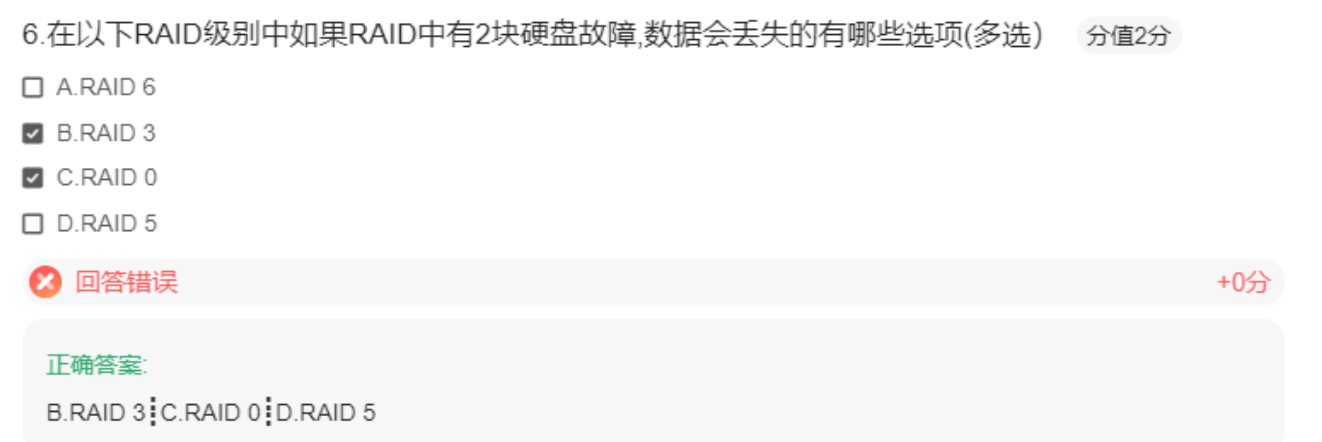
raid
案例

案例
案例
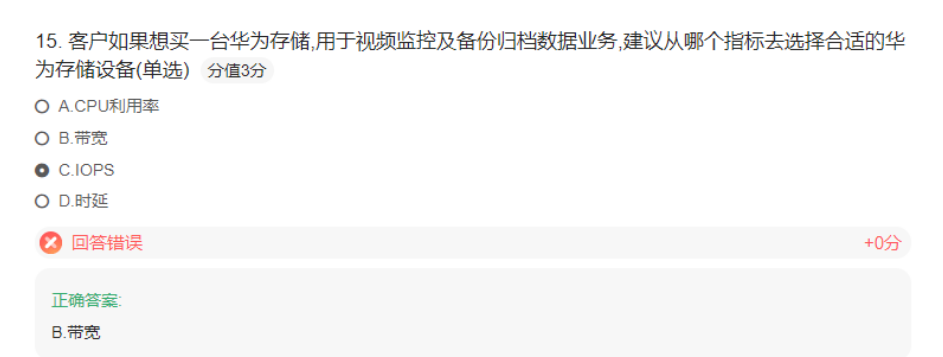
zone
案例
容灾和备份
案例
 **
**
ceph
案例
NAS
案例
网络
dhcp
案例
osi
案例
🍀 gpt
中继器、集线器、网桥、交换机工作在osi七层模型的哪一层?
中继器、集线器、网桥和交换机是网络设备,它们在OSI七层模型的不同层次上工作:
- 中继器(Repeater):
- 工作在物理层(第一层)。
- 主要功能是放大信号,延长网络的传输距离,但不理解数据帧。
- 集线器(Hub):
- 也工作在物理层(第一层)。
- 类似于中继器,它是一种共享媒体设备,通过广播方式将数据传输到网络上的所有设备。
- 网桥(Bridge):
- 工作在数据链路层(第二层)。
- 能够理解数据帧,根据MAC地址进行过滤和转发,连接两个相邻的网络。
- 交换机(Switch):
- 通常工作在数据链路层(第二层),但部分智能交换机也能在网络层(第三层)工作。
- 类似于网桥,但通常更先进,可以根据MAC地址进行端口间的直接通信,提高网络性能。
总体而言,中继器和集线器主要在物理层操作,而网桥和交换机则在更高的数据链路层进行操作。这些设备的演进反映了网络技术的不断发展和对更高性能、更智能网络的需求。
堆叠
案例

案例
防火墙
案例
案例
案例
VRRP
案例

案例

BGP
案例:tcp,179端口
VxLAN
SDN
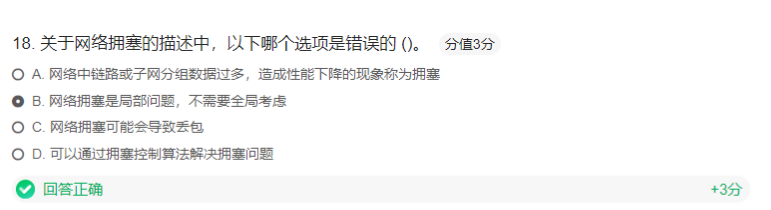
网络拥塞
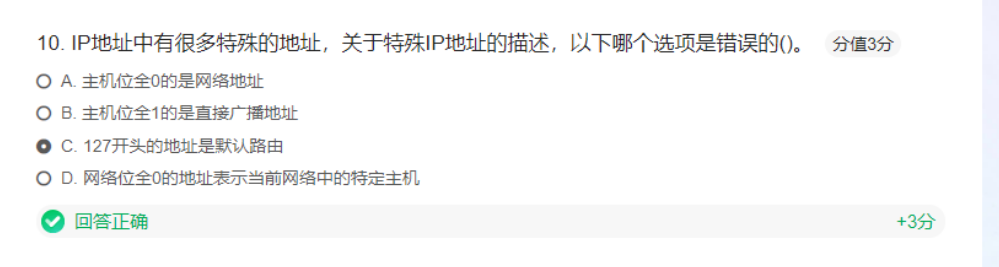
ip地址
ipv6

链路聚合技术

ospf

虚拟化
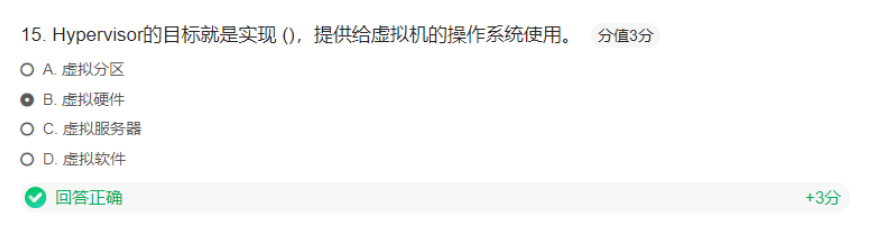
案例:Hypervisor
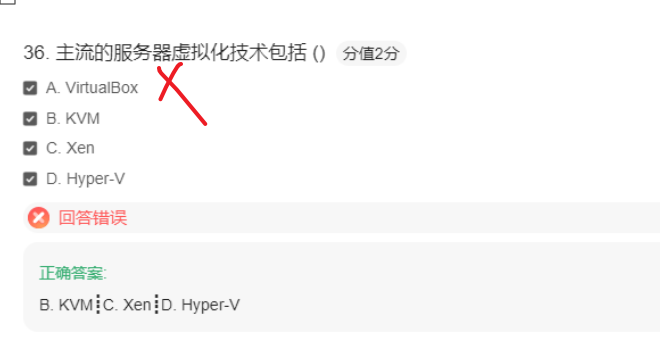
案例:虚拟化技术
OpenStack
案例:调度组件
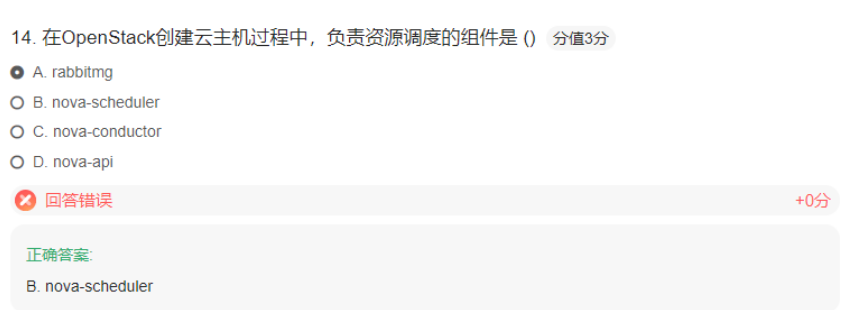
案例:Openstack Cinder

其他
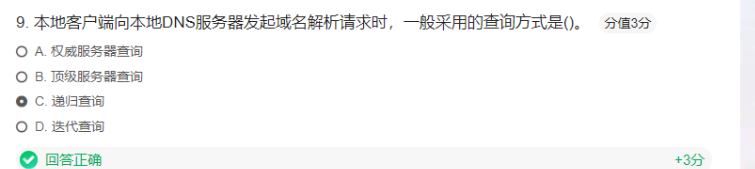
dns
案例:递归查询
运维指标
MTBF 平均无故障时间
MTBF是“Mean Time Between Failures”的缩写,意为平均无故障时间。它是衡量产品、系统或设备可靠性的一个指标,通常用于预测产品或系统的操作时间长度,在故障之间平均能够正常运行多久。
具体来说,MTBF是在一定的时间内发生的故障次数的总运行时间除以总故障次数。它的计算公式为:
\[ MTBF = \frac{总运行时间}{故障次数} \]
这个指标常用于工业产品或系统,尤其是在硬件维护和制造业中。MTBF高的产品或系统预示着更长的平均正常运行时间和更好的可靠性。然而,值得注意的是,MTBF只适用于可修复的系统,因为它假设系统在发生故障后都能被修复并恢复到正常工作状态。
在实际应用中,MTBF也可以用来计划维护时间间隔、预计备件需求、以及评估产品的长期性能表现。不过,MTBF并不是表示每个�单独单位都会在MTBF指定的时间后才会发生故障,而是在很长的时间内,整个系统或产品群体的平均表现。因此,个别设备可能早于或晚于MTBF指定的时间发生故障。

RTO=0 RPO=0 ?

在业务连续性和灾难恢复领域,RTO(Recovery Time Objective,恢复时间目标)和RPO(Recovery Point Objective,恢复点目标)是两个关键的术语。
- RTO (恢复时间目标) 是指从服务中断开始到业务过程必须恢复到最小可接受水平的时间内。简而言之,它衡量的是你可以承受的业务停机时间。
- RPO (恢复点目标) 指的是在灾难发生时,你能容忍丢失多少数据量,通常以时间来衡量。换句话说,它是自上次有效备份以来可能丢失数据的最大时间窗口。
当说RTO=0和RPO=0时:
- RTO=0 意味着在任何故障的情况下,需要立即恢复业务操作,没有容忍的停机时间。
- RPO=0 表明不能丢失任何数据,这通常意味着需要实时数据复制或那种能确保数据不会丢失的连续数据保护机制。
实现RTO=0和RPO=0是非常具挑战性的,通常需要高度复杂和成本较高的技术解决方案,例如在多地点进行实时数据同步,以及具有即时故障转移能力的高可用性系统设计。这通常只适用于对停机时间和数据丢失非常敏感的关键业务应用。
阿里云
案例:一个大型网站准备上线,时间非常紧急,需要在 2 天内完成 2000 台 ECS 的开通的环境部署,以下哪个功能可以帮客户解决困难?(C)
A、SSD
B、快照+OpenAPI
C、自定义镜像+OpenAPI
D、共享快照
网站运维
简单题
案例
请给出将“sleep 1500“命令放在后台执行的命令,并给出查询该后台命令Pid,然后 kill 掉该命令的方法和命令。
nohup sleep 1500 &
kill -9 `ps -ef|grep 1500|grep -v 'grep'|awk '{print $2}'`
grep -v 'grep' 排除掉grep进程本身