4、Grafana
Grafana
目录
[toc]
1、什么是Grafna
前面我们使用 Prometheus 采集了 Kubernetes 集群中的一些监控数据指标,我们也尝试使用 promQL 语句查询出了一些数据,并且在 Prometheus 的 Dashboard 中进行了展示,但是明显可以感觉到 Prometheus 的图表功能相对较弱。所以一般情况下我们会用一个第三方的工具来展示这些数据,今天我们要和大家使用到的就是 Grafana。
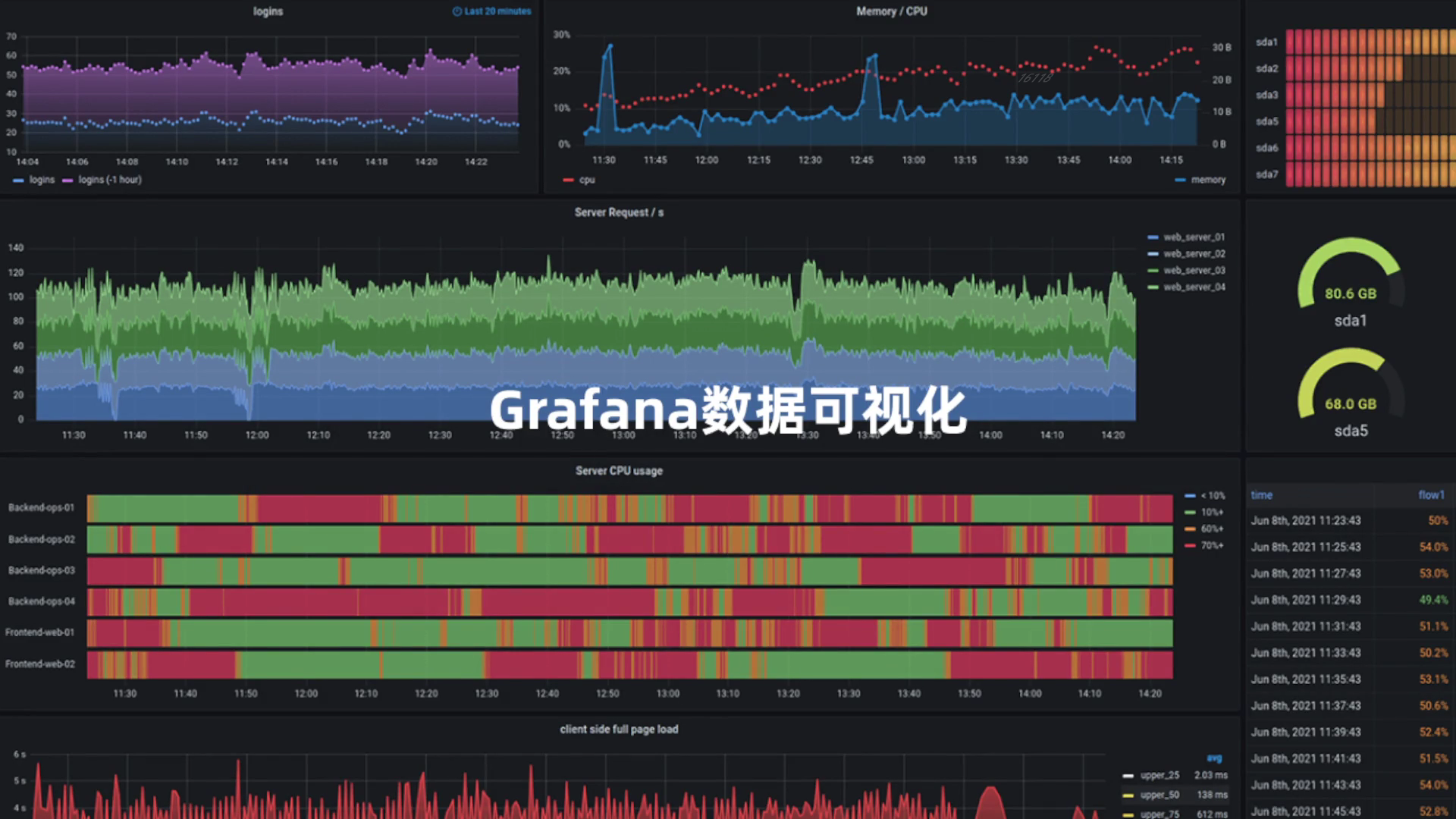
Grafana 是一个可视化面板,有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持 Graphite、zabbix、InfluxDB、Prometheus、OpenTSDB、Elasticsearch 等作为数据源,比 Prometheus 自带的图表展示功能强大太多,更加灵活,有丰富的插件,功能更加强大。
2、Grafana安装
💘 实战1:k8s里部署Grafna(成功测试)-2022.7.23(yaml方式)
实验环境
k8s:v1.22.2(1 master,2 node)
containerd: v1.5.5
prometneus: docker.io/prom/prometheus:v2.34.0
grafana/grafana:8.4.6
实验软件
链接:https://pan.baidu.com/s/1Gdvi4Xu1yQqVG6jeuprrRg?pwd=9cgh
提取码:9cgh
2020.5.4-grafana-code
前置条件
- 具有k8s环境;
- 已经把prometheus应用部署到k8s环境里,且prometheus数据源可以提供k8s集群啦一些数据了。(关于如何采集数据,请看我的其他系列文章)
https://blog.csdn.net/weixin_39246554/article/details/124545640?spm=1001.2014.3001.5501
1.查看grafna镜像介绍
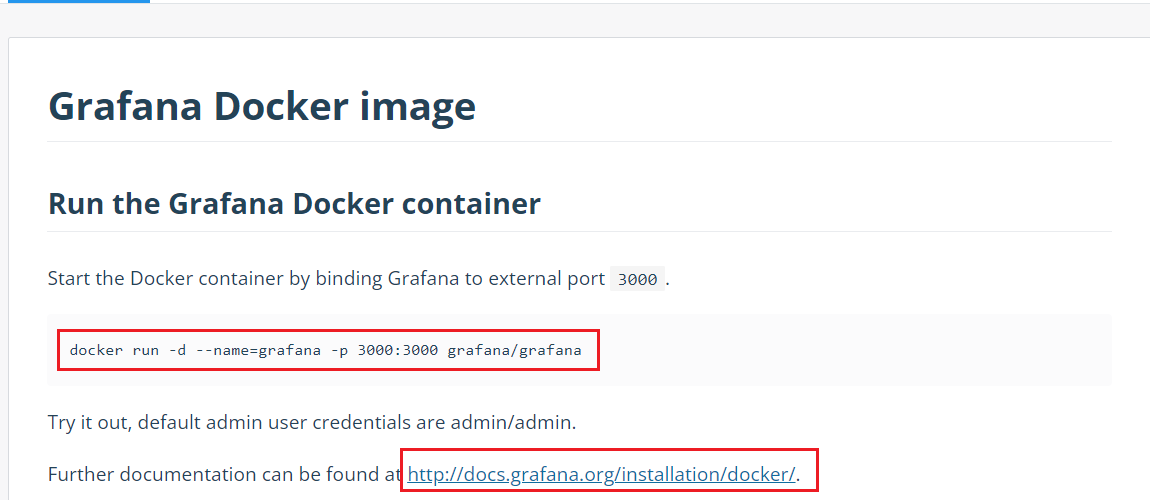
同样的我们将 grafana 安装到 Kubernetes 集群中,第一步去查看 grafana 的 docker 镜像的介绍,我们可以在 dockerhub 上去搜索,也可以在官网去查看相关资料,镜像地址如下:https://hub.docker.com/r/grafana/grafana/,我们可以看到介绍中运行 grafana 容器的命令非常简单:
$ docker run -d --name=grafana -p 3000:3000 grafana/grafana
但是还有一个需要注意的是 Changelog 中v5.1.0版本的更新介绍:
Major restructuring of the container
Usage of chown removed
File permissions incompatibility with previous versions
user id changed from 104 to 472
group id changed from 107 to 472
Runs as the grafana user by default (instead of root)
All default volumes removed
特别需要注意第3条,userid 和 groupid 都有所变化,所以我们在运行的容器的时候需要注意这个变化。
2.将grafna容器部署到k8s
- 现在我们将这个容器转化成 Kubernetes 中的 Pod:
本次测试目录如下:
[root@master1 ~]#mkdir grafana
[root@master1 ~]#cd grafana/
- 提前在node1上配置grafana数据目录(后续Grafana数据持久化需要用!)
[root@master1 grafana]#ssh node1
Last login: Sat Apr 30 12:56:43 2022 from master1
[root@node1 ~]#mkdir -p /data/k8s/grafana
- 创建grafna的Deployment及Service资源:
[root@master1 grafana]#vim grafana-deployment.yaml
# grafana-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitor
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana-pvc
securityContext: #注意:这里以root身份运行!
runAsUser: 0
containers:
- name: grafana
image: grafana/grafana:8.4.6
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD #这里最好用secret引用过来!
value: admin321
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 150m
memory: 512Mi
requests:
cpu: 150m
memory: 512Mi
volumeMounts:
- mountPath: /var/lib/grafana #grafana的数据目录:数据库及插件等!
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitor
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
- 创建grafana的pvc资源:
[root@master1 grafana]#vim grafana-pvc.yaml
#grafana-pvc.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-local
labels:
app: grafana
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 2Gi
storageClassName: local-storage
local:
path: /data/k8s/grafana #一定要先在宿主机node1上提前创建这个目录!!!
nodeAffinity: #pv也是可以配置节点亲和性的哦!!!
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1 #这里是自己的node1节点
persistentVolumeReclaimPolicy: Retain
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-pvc
namespace: monitor
spec:
selector:
matchLabels:
app: grafana
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
storageClassName: local-storage
我们使用了最新的镜像 grafana/grafana:8.4.6,然后添加了健康检查、资源声明。
另外两个比较重要的环境变量GF_SECURITY_ADMIN_USER 和 GF_SECURITY_ADMIN_PASSWORD,用来配置 grafana 的管理员用户和密码的。由于 grafana 将 dashboard、插件这些数据保存在 /var/lib/grafana 这个目录下面的,所以我们这里如果需要做数据持久化的话,就需要针对这个目录进行 volume 挂载声明。
由于上面我们刚刚提到的 Changelog 中 grafana 的 userid 和 groupid 有所变化,所以我们这里增加一个 securityContext 的声明来进行声明使用 root 用户运行。
最后,我们需要对外暴露 grafana 这个服务,所以我们需要一个对应的 Service 对象,当然用 NodePort 或者再建立一个 ingress 对象都是可行的。
- 现在我们直接创建上面的这些资源对象:
(1)先创建grafana-pvc.yaml
[root@master1 grafana]#kubectl apply -f grafana-pvc.yaml
persistentvolume/grafana-local created
persistentvolumeclaim/grafana-pvc created
[root@master1 grafana]#kubectl get pv grafana-local
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
grafana-local 2Gi RWO Retain Bound monitor/grafana-pvc local-storage 16s
[root@master1 grafana]#kubectl get pvc -nmonitor grafana-pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
grafana-pvc Bound grafana-local 2Gi RWO local-storage 40s
(2)再创建grafana-deployment.yaml
[root@master1 grafana]#kubectl apply -f grafana-deployment.yaml
deployment.apps/grafana created
service/grafana created
#创建完成后,我们可以查看 grafana 对应的 Pod 是否正常:
[root@master1 grafana]#kubectl get po -l app=grafana -nmonitor -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
grafana-86d545fc5-42jhd 1/1 Running 0 99s 10.244.1.90 node1 <none> <none>

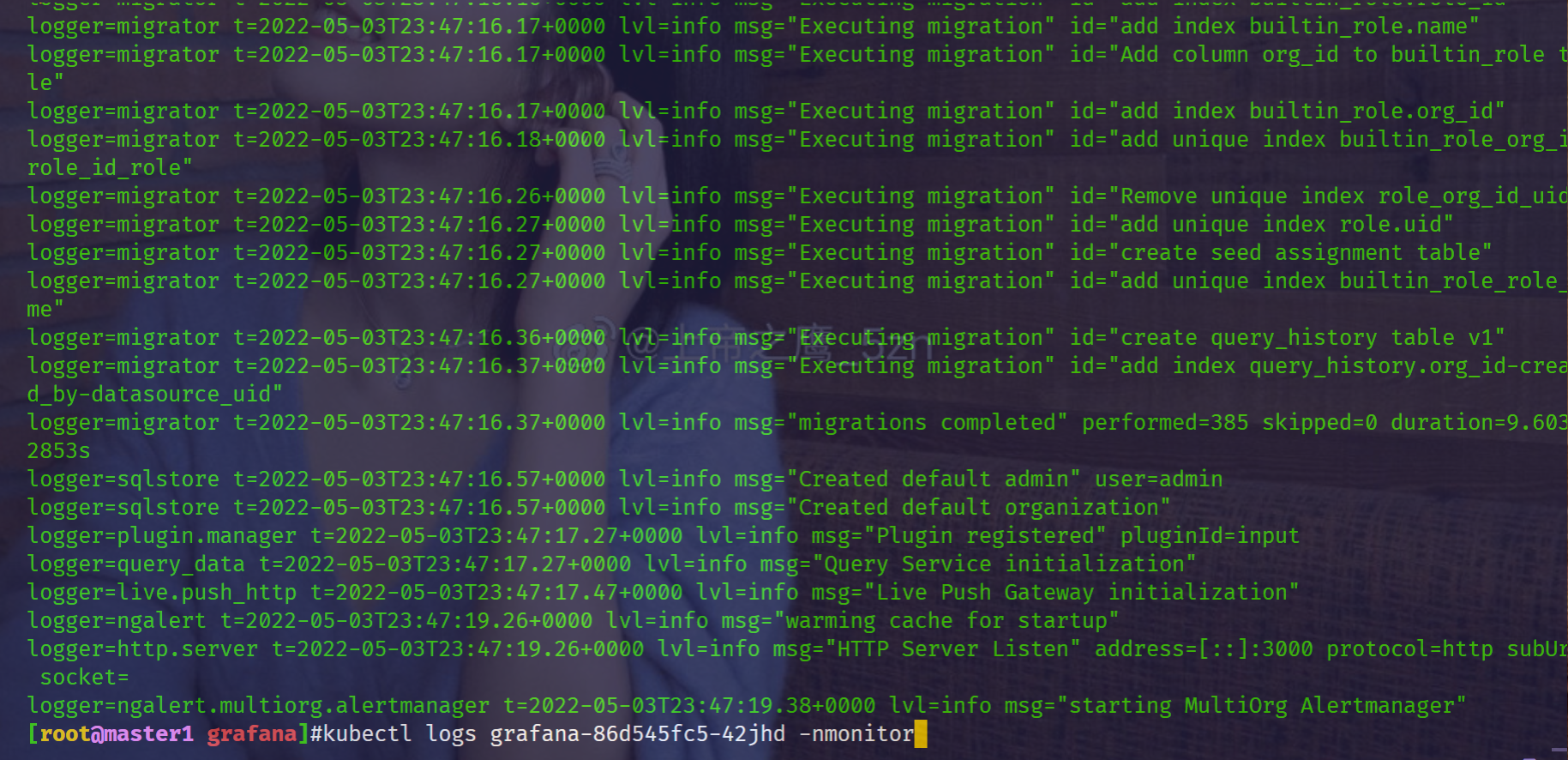
看到上面的日志信息就证明我们的 grafana 的 Pod 已经正常启动起来了。
这个时候我们可以查看 Service 对象:
[root@master1 grafana]#kubectl get svc -nmonitor
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.100.237.2 <none> 3000:30338/TCP 3m22s
prometheus NodePort 10.101.131.61 <none> 9090:32700/TCP 4d9h
redis ClusterIP 10.103.59.18 <none> 6379/TCP,9121/TCP 24h
- 验证
现在我们就可以在浏览器中使用 http://<任意节点IP:30338> 来访问 grafana 这个服务了:
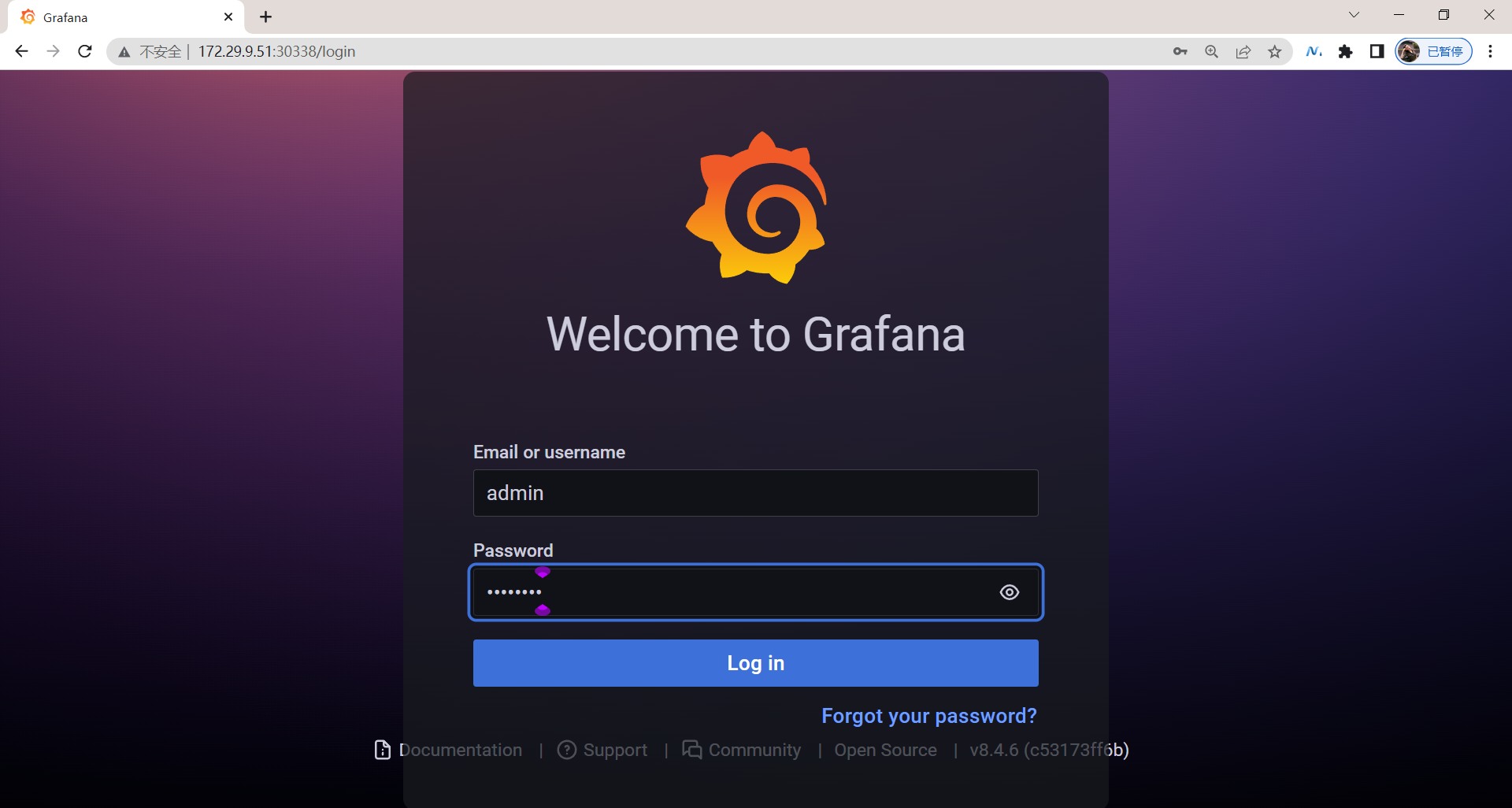
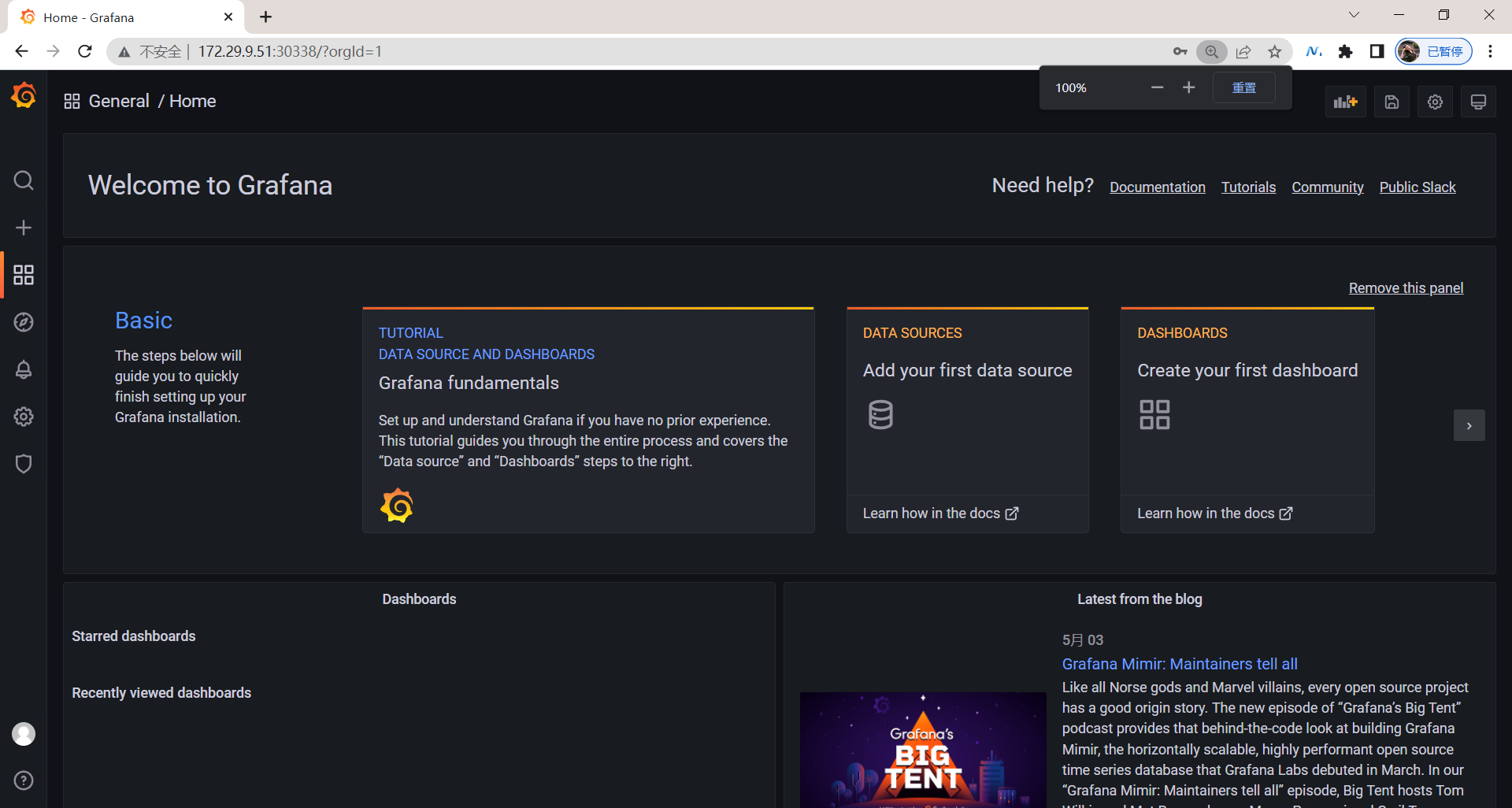
由于上面我们配置了管理员的,所以第一次打开的时候会跳转到登录界面,然后就可以用上面我们配置的两个环境变量的值来进行登录了,登录完成后就可以进入到下面 Grafana 的首页。
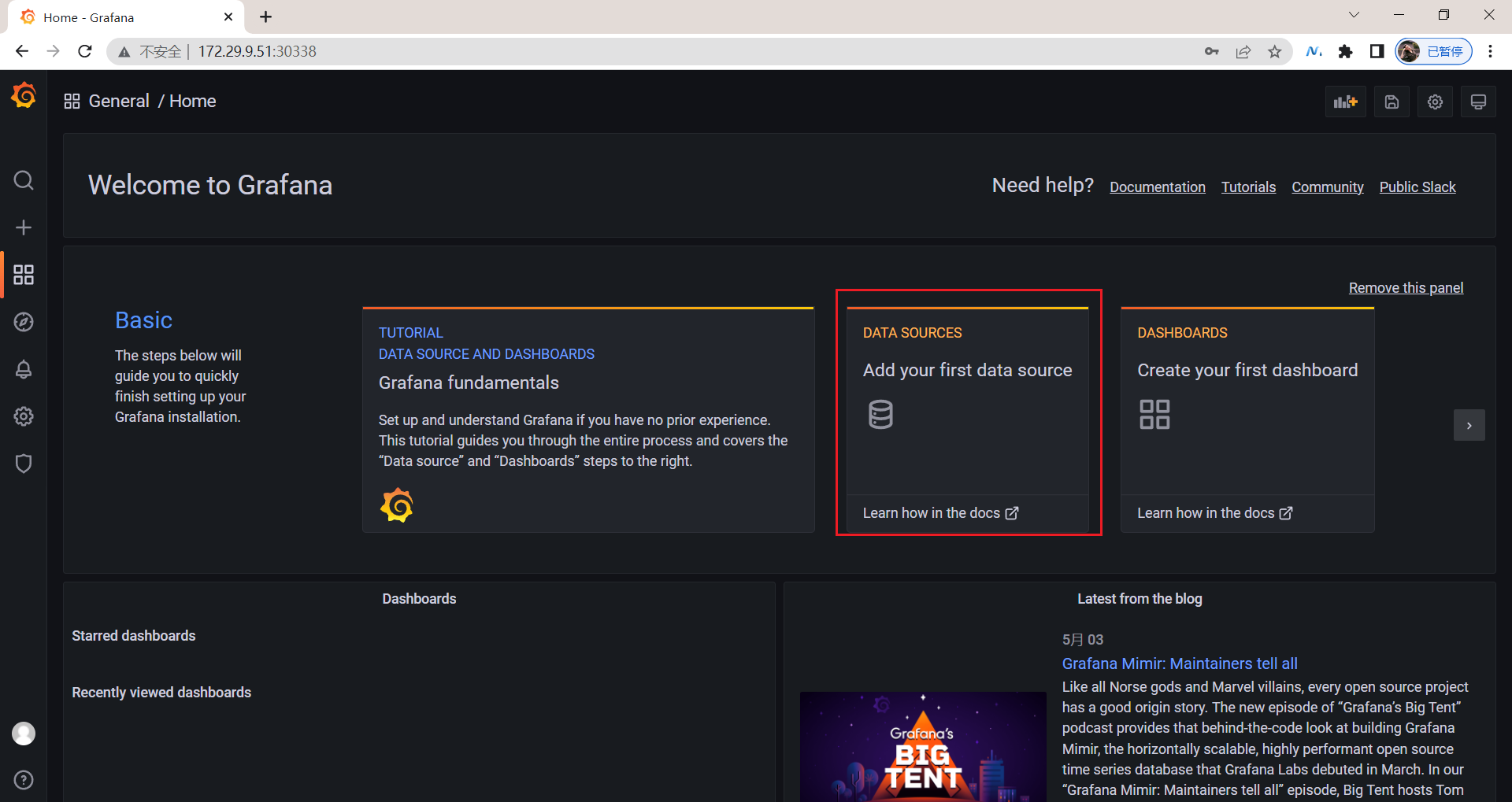
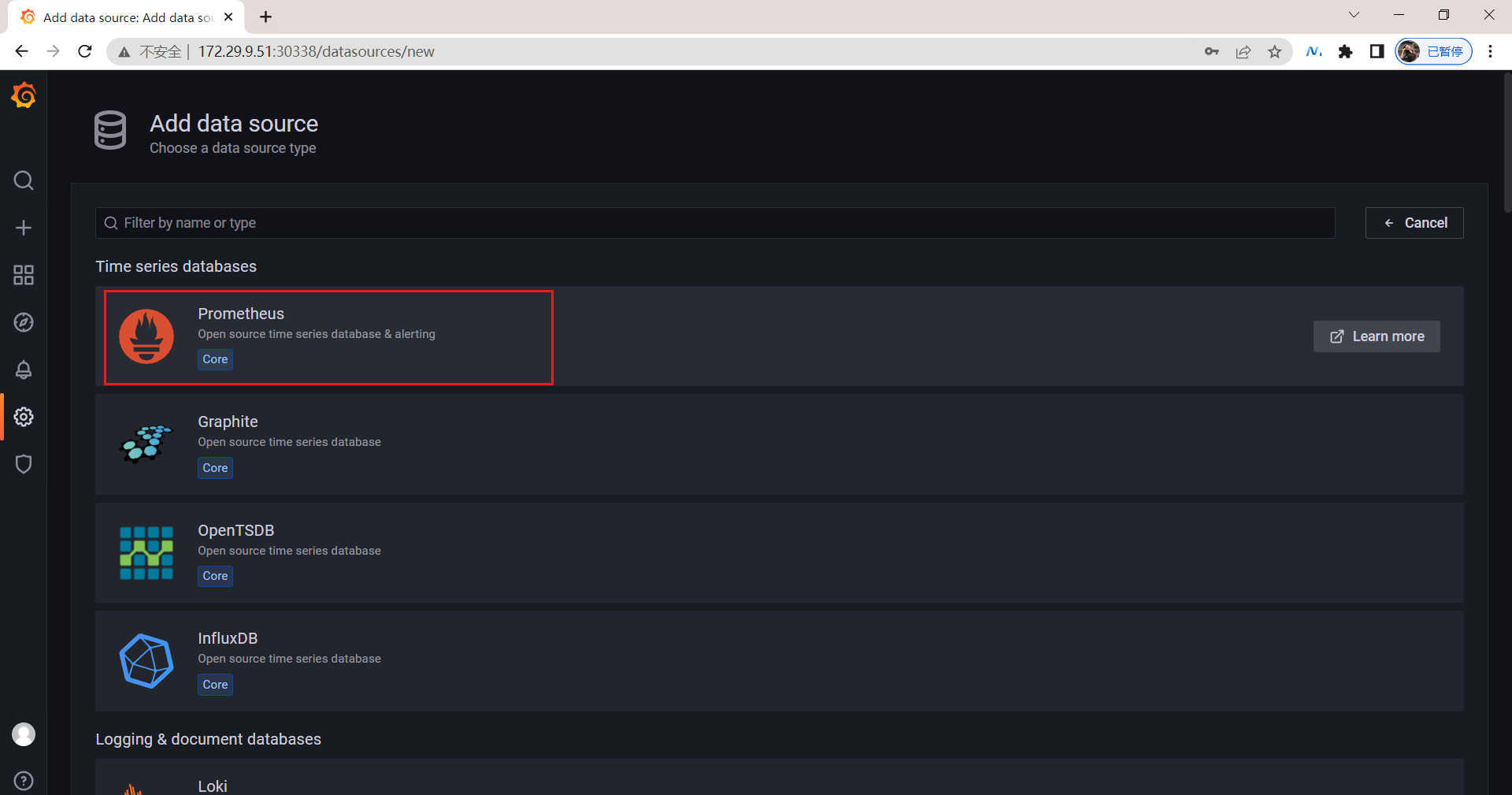
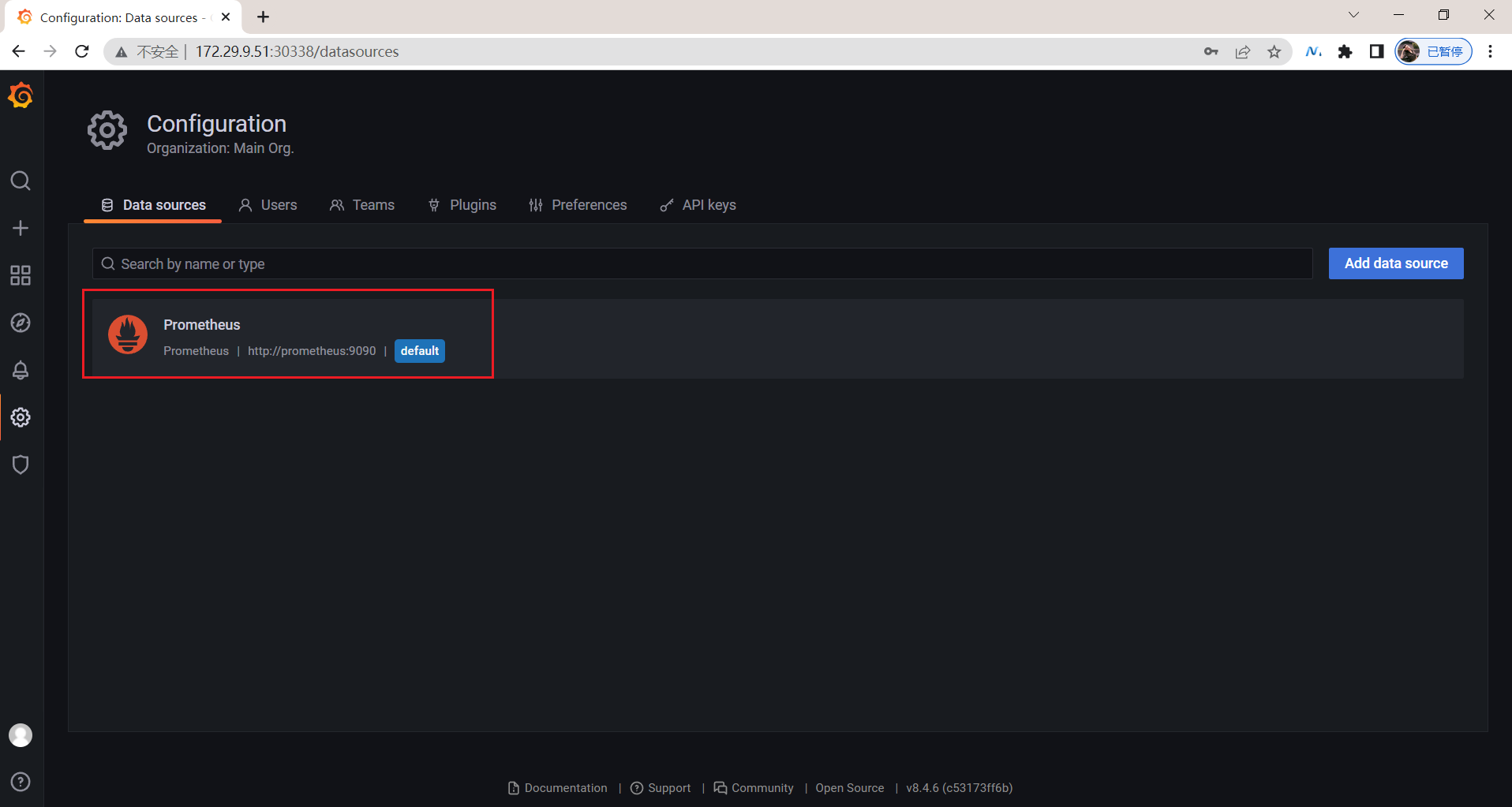
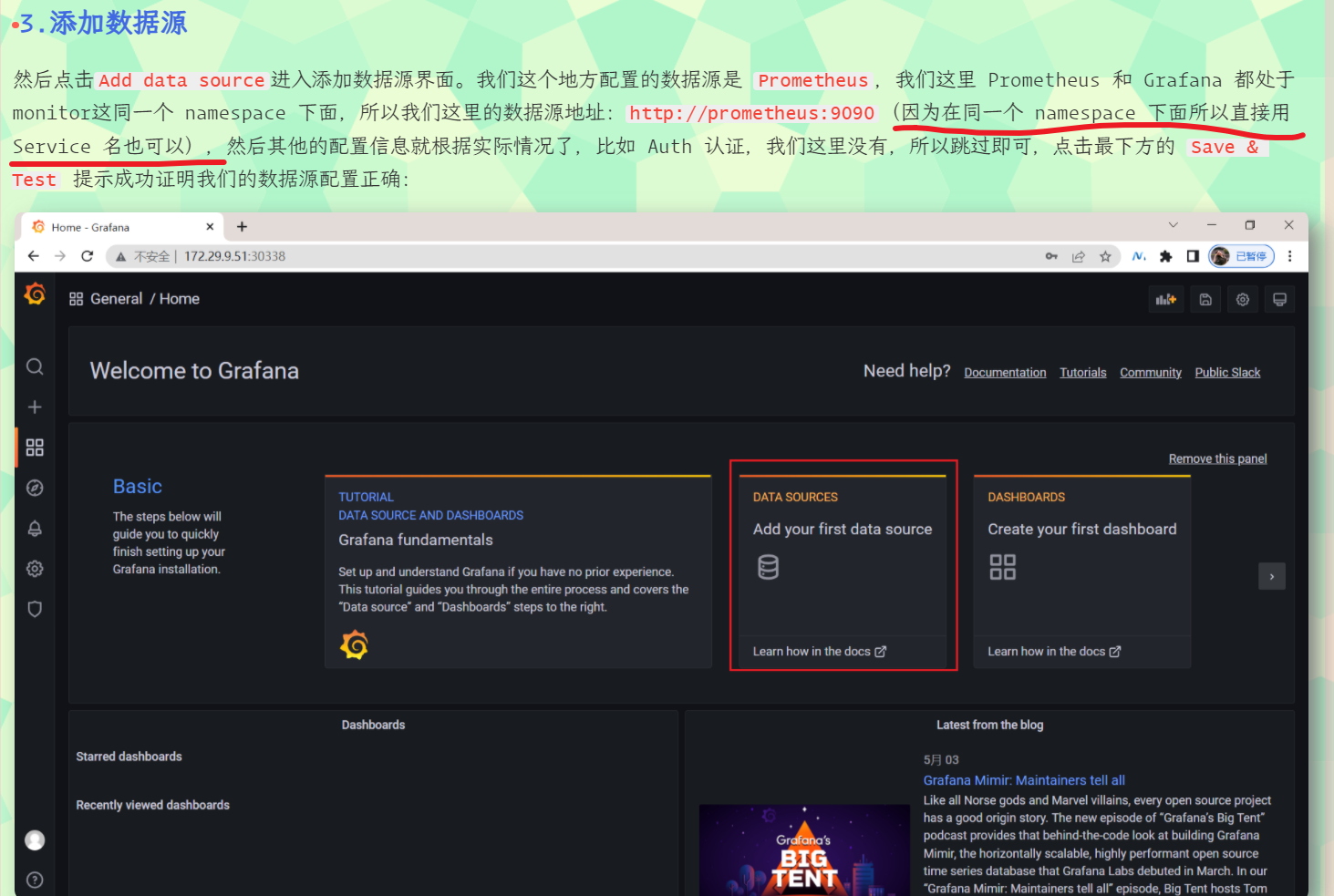
3.添加数据源
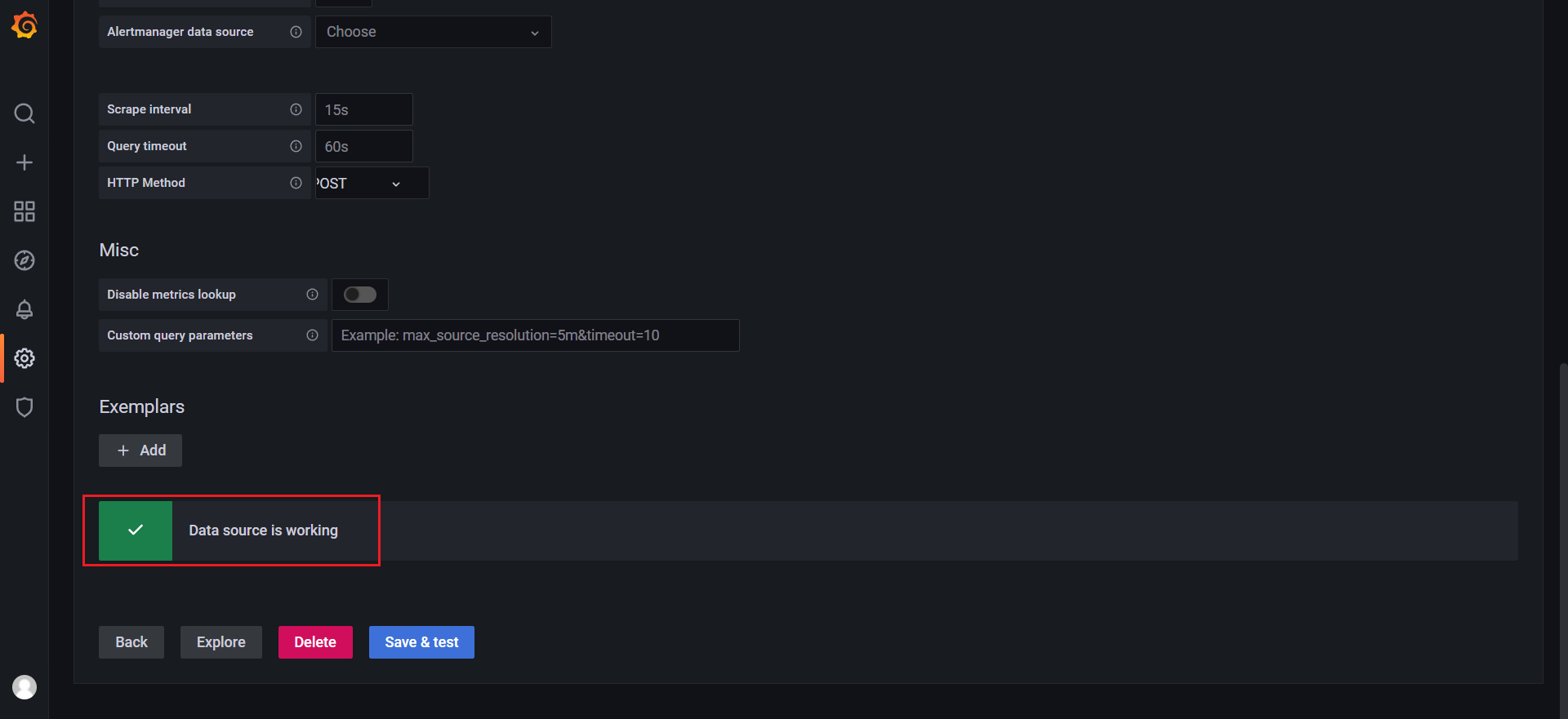
然后点击Add data source进入添加数据源界面。我们这个地方配置的数据源是 Prometheus,我们这里 Prometheus 和 Grafana 都处于 monitor这同一个 namespace 下面,所以我们这里的数据源地址:http://prometheus:9090(因为在同一个 namespace 下面所以直接用 Service 名也可以),然后其他的配置信息就根据实际情况了,比如 Auth 认证,我们这里没有,所以跳过即可,点击最下方的 Save & Test 提示成功证明我们的数据源配置正确:
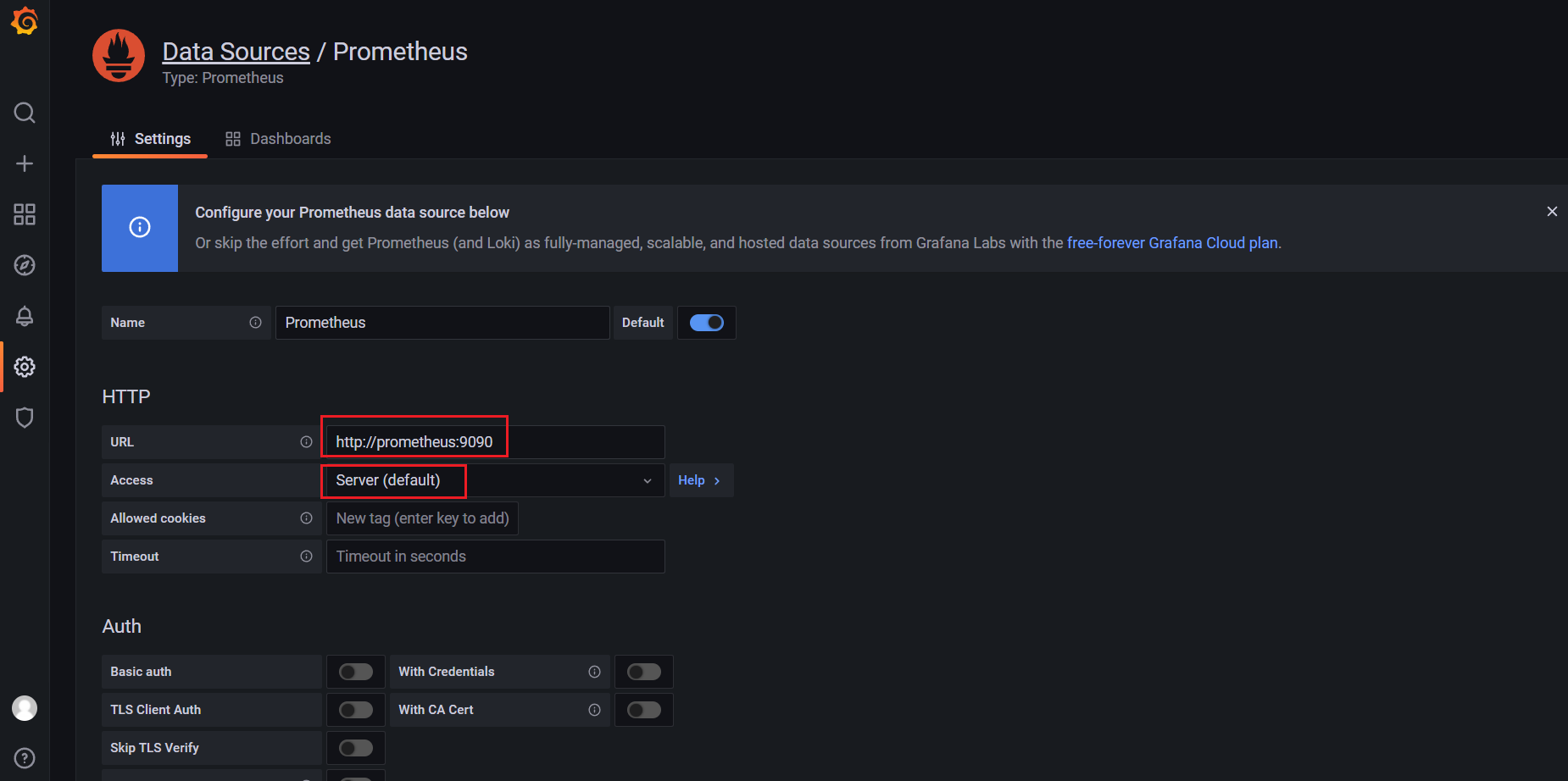
注意:Browser这种方式将被废弃!(如果是Browser的话,URL就需要添加:http://nodeIp:nortPOrt形式了)
Server:服务端,Browser:客户端;
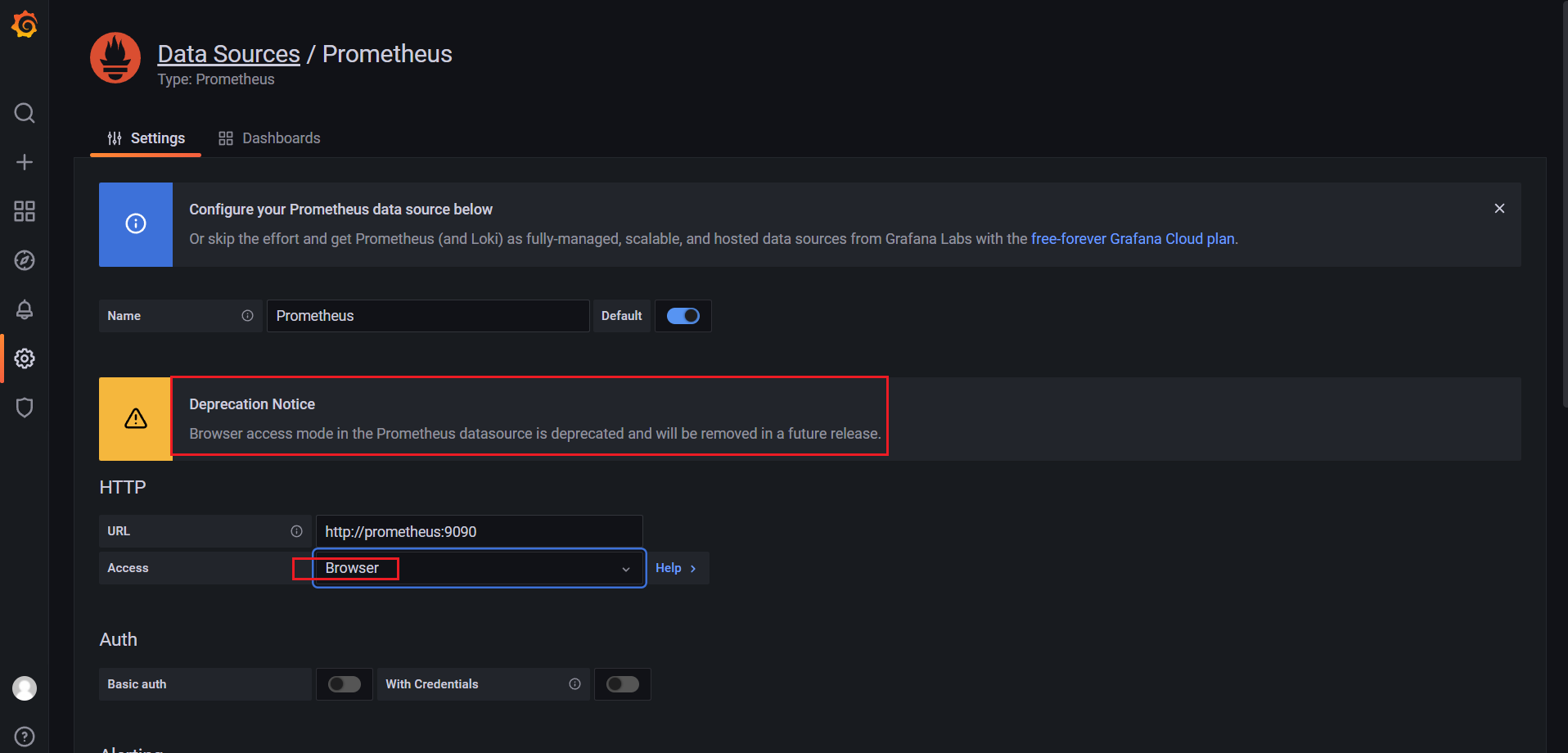
点击Save&test:
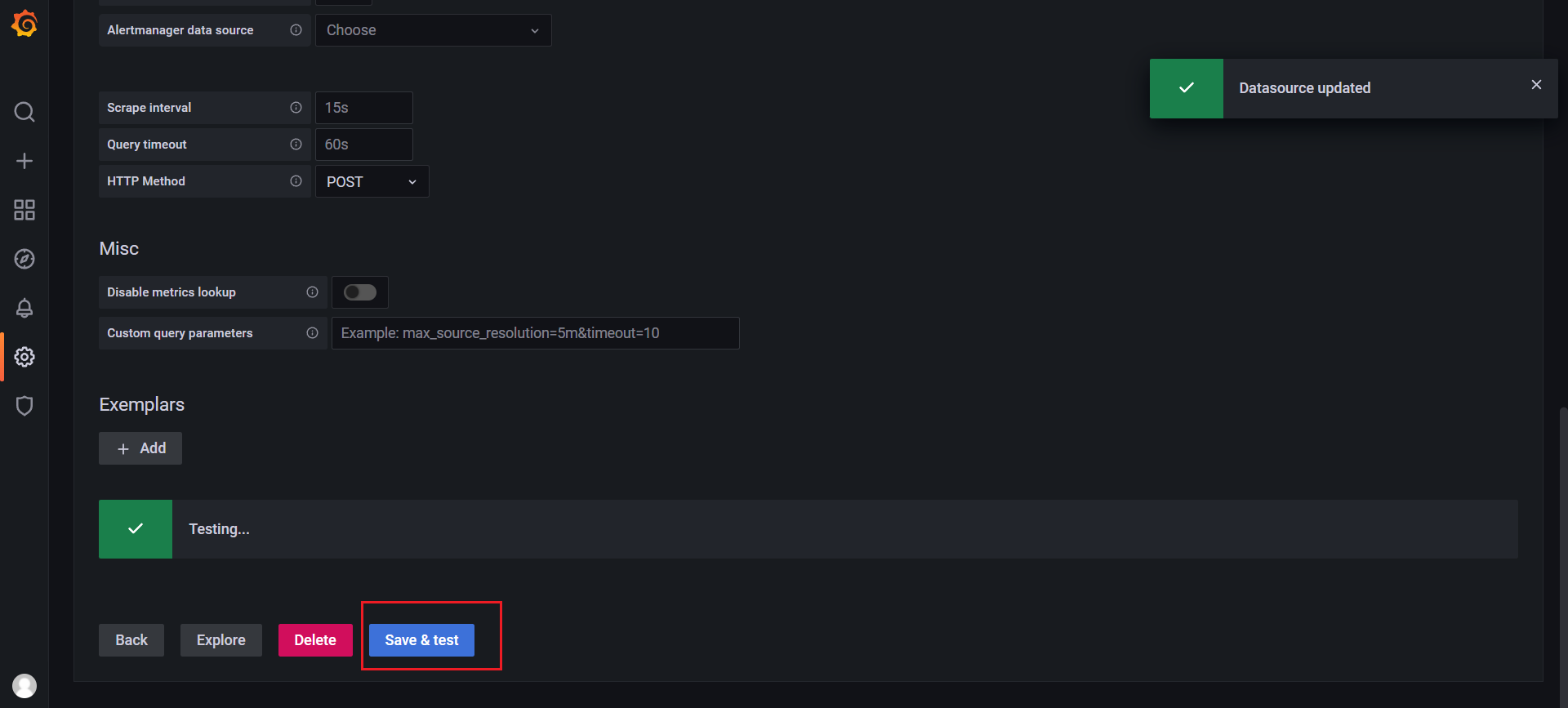
查看:
4.导入 Dashboard
为了能够快速对系统进行监控,我们可以直接复用别人的 Grafana Dashboard。在 Grafana 的官方网站上就有很多非常优秀的第三方 Dashboard,我们完全可以直接导入进来即可。比如我们想要对所有的集群节点进行监控,也就是 node-exporter 采集的数据进行展示,这里我们就可以导入 https://grafana.com/grafana/dashboards/8919 这个 Dashboard。
- 在侧边栏点击 "+",选择
Import,在 Grafana Dashboard 的文本框中输入 8919 即可导入:
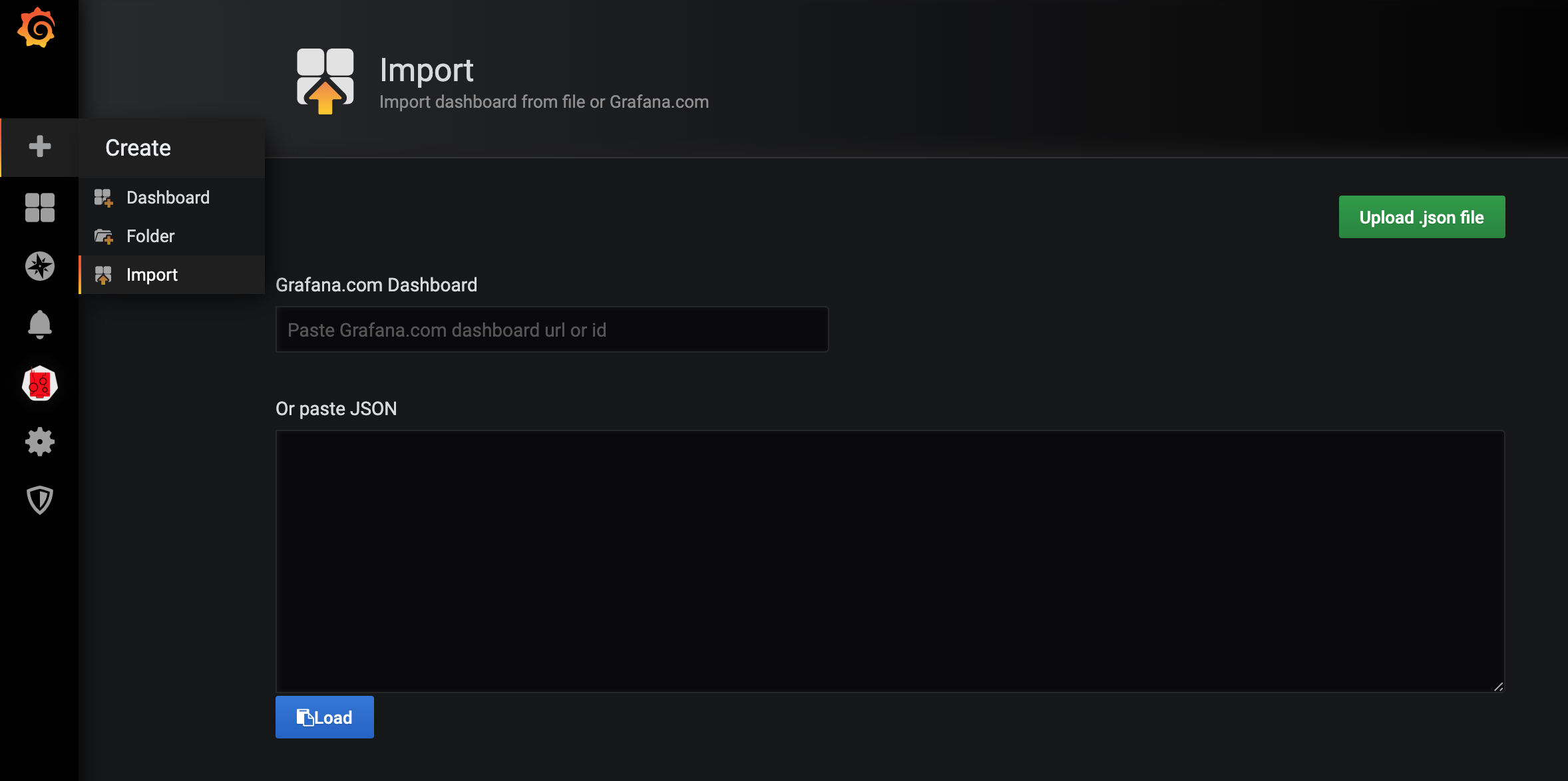
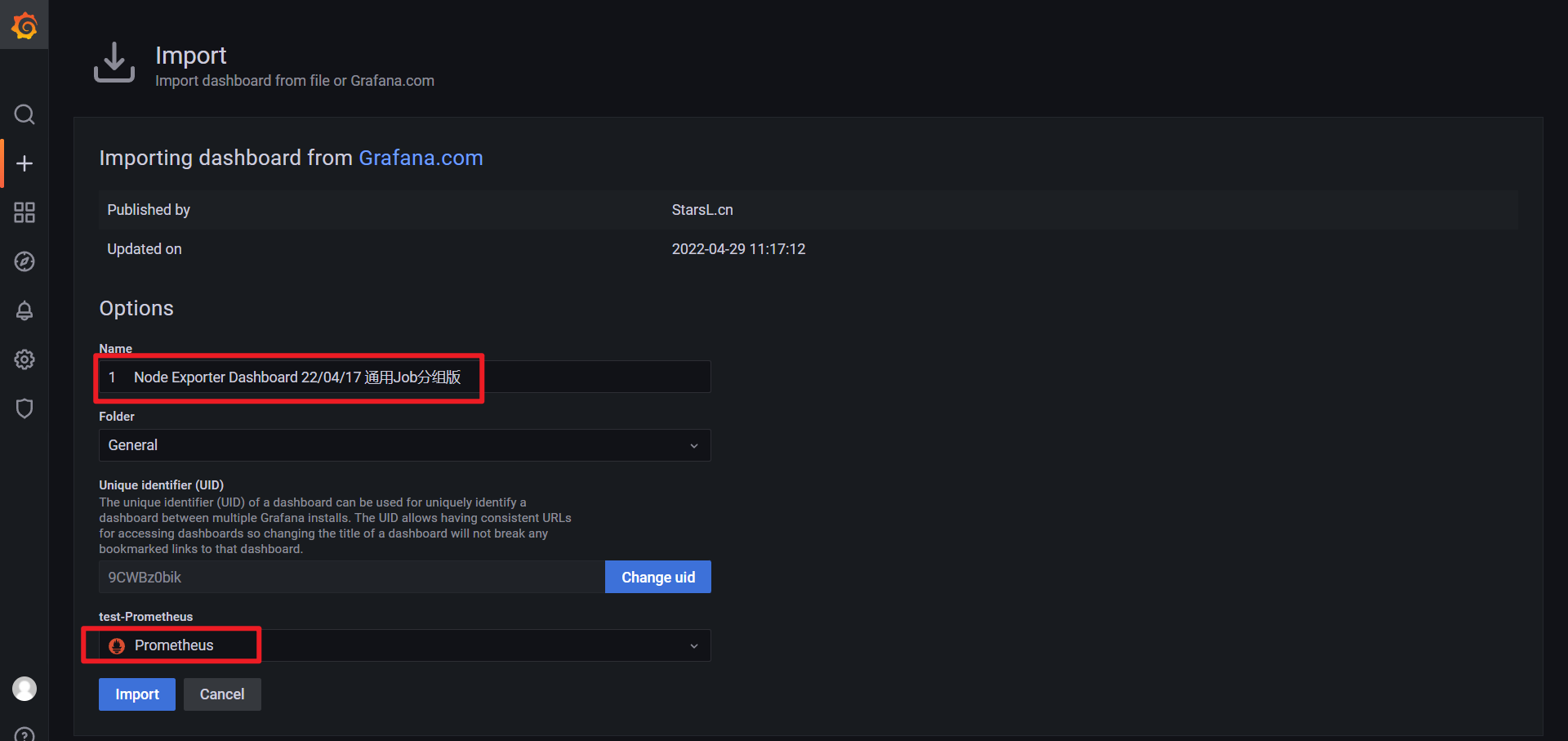
- 进入导入 Dashboard 的页面,可以编辑名称,选择 Prometheus 的数据源:
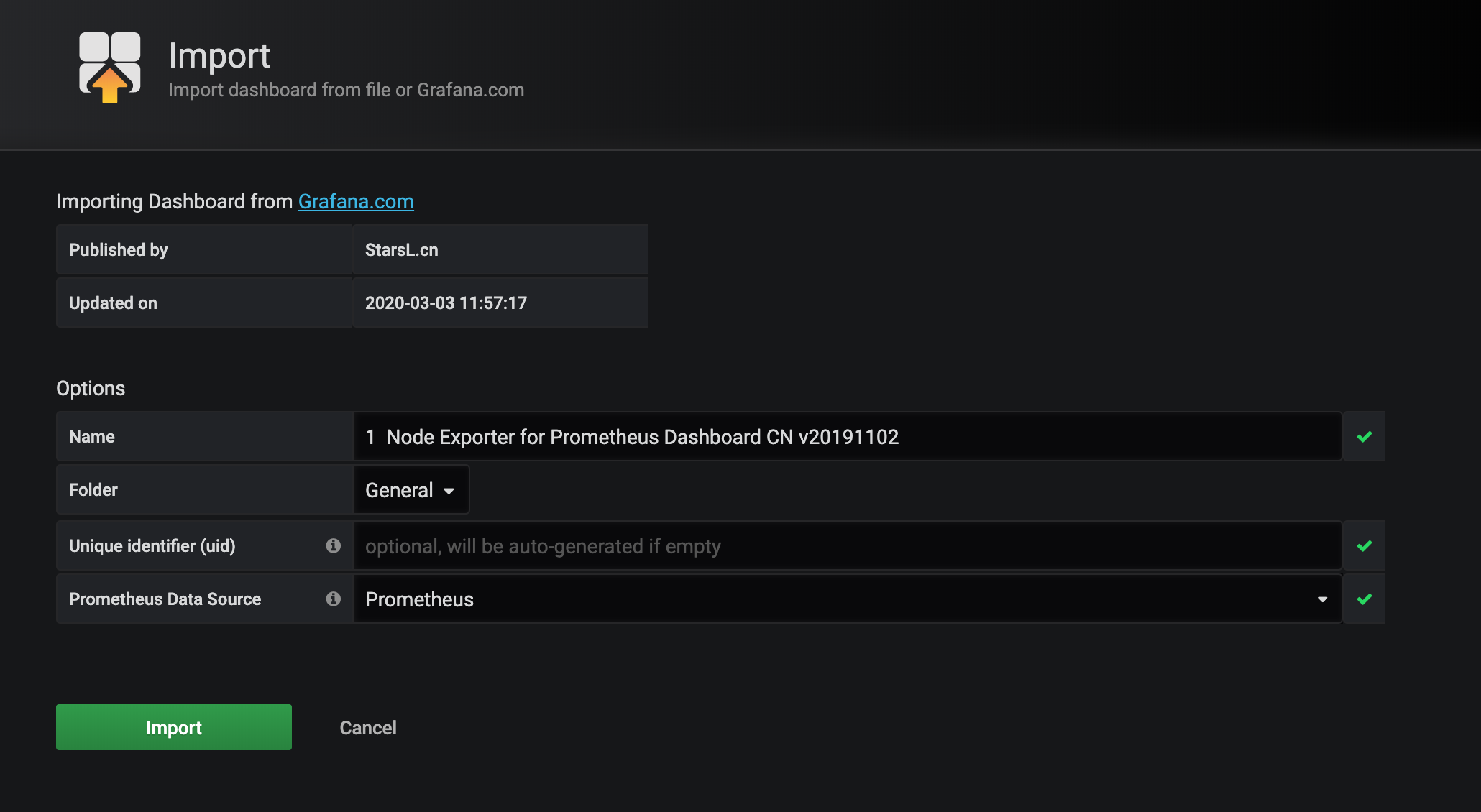
保存后即可进入导入的 Dashboard 页面。
- 由于该 Dashboard 更新比较及时,所以基本上导入进来就可以直接使用了,我们也可以对页面进行一些调整,如果有的图表没有出现对应的图形,则可以编辑根据查询语句去 DEBUG。
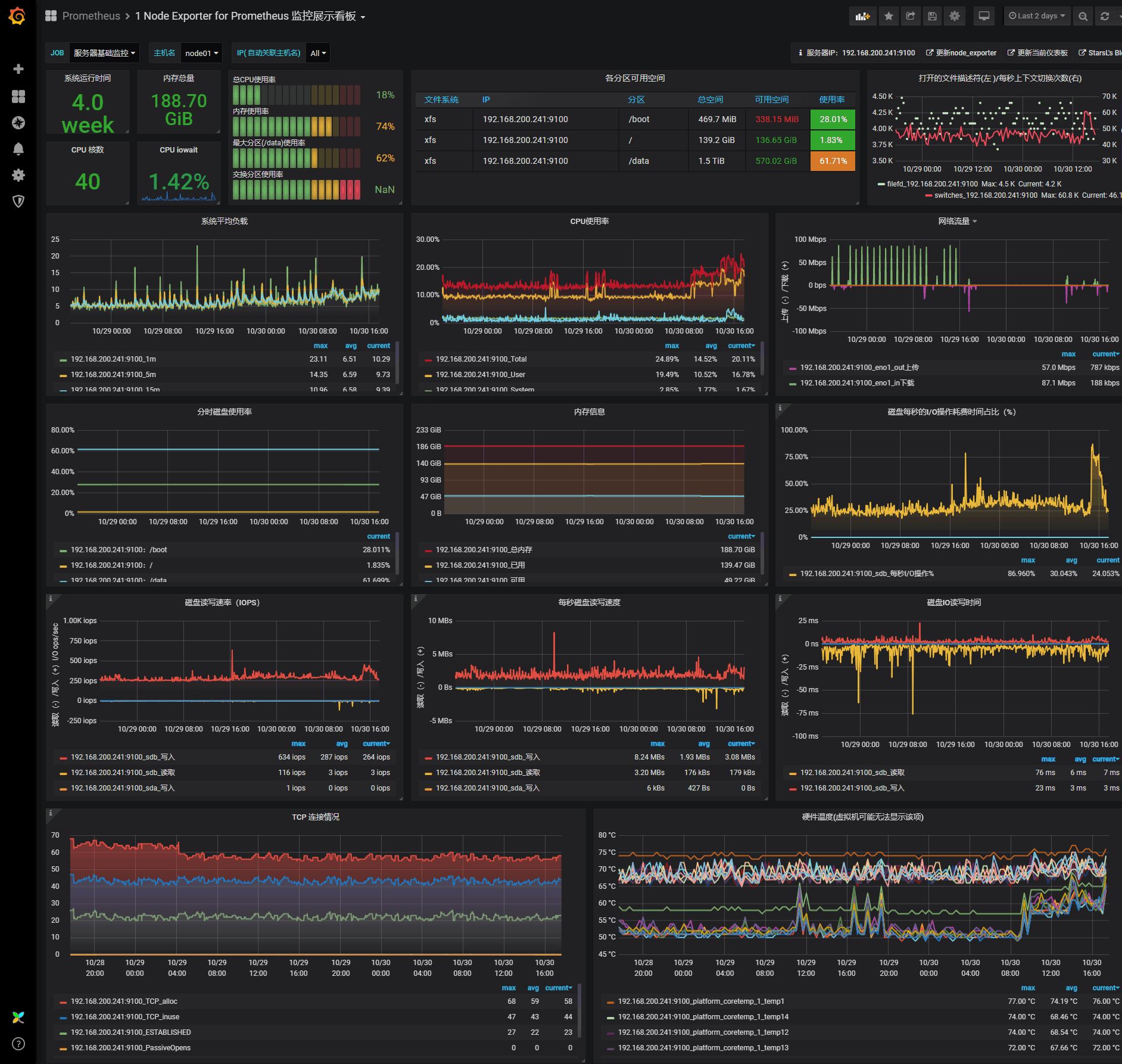
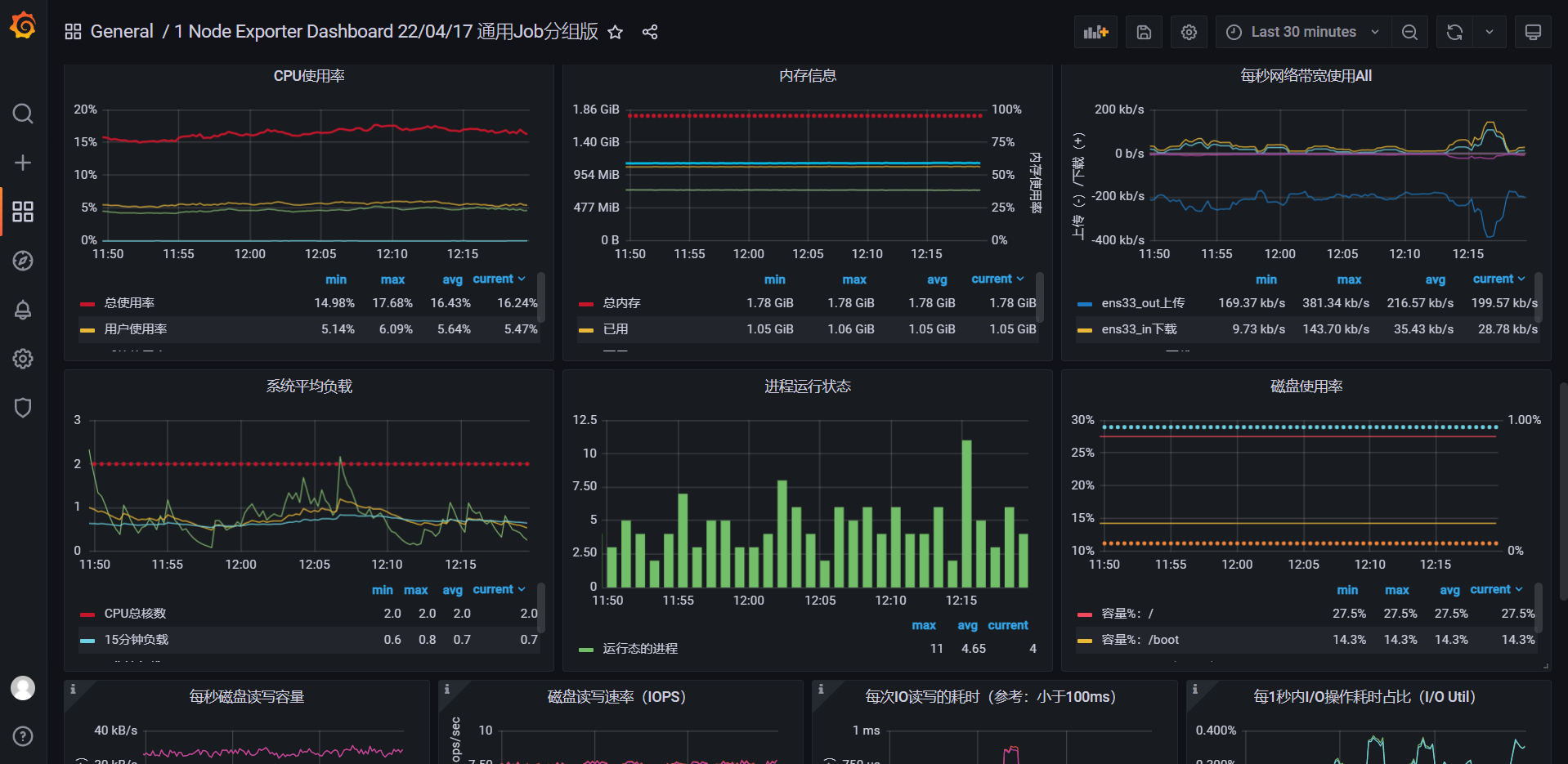
🍀 案例:导入16098
效果:
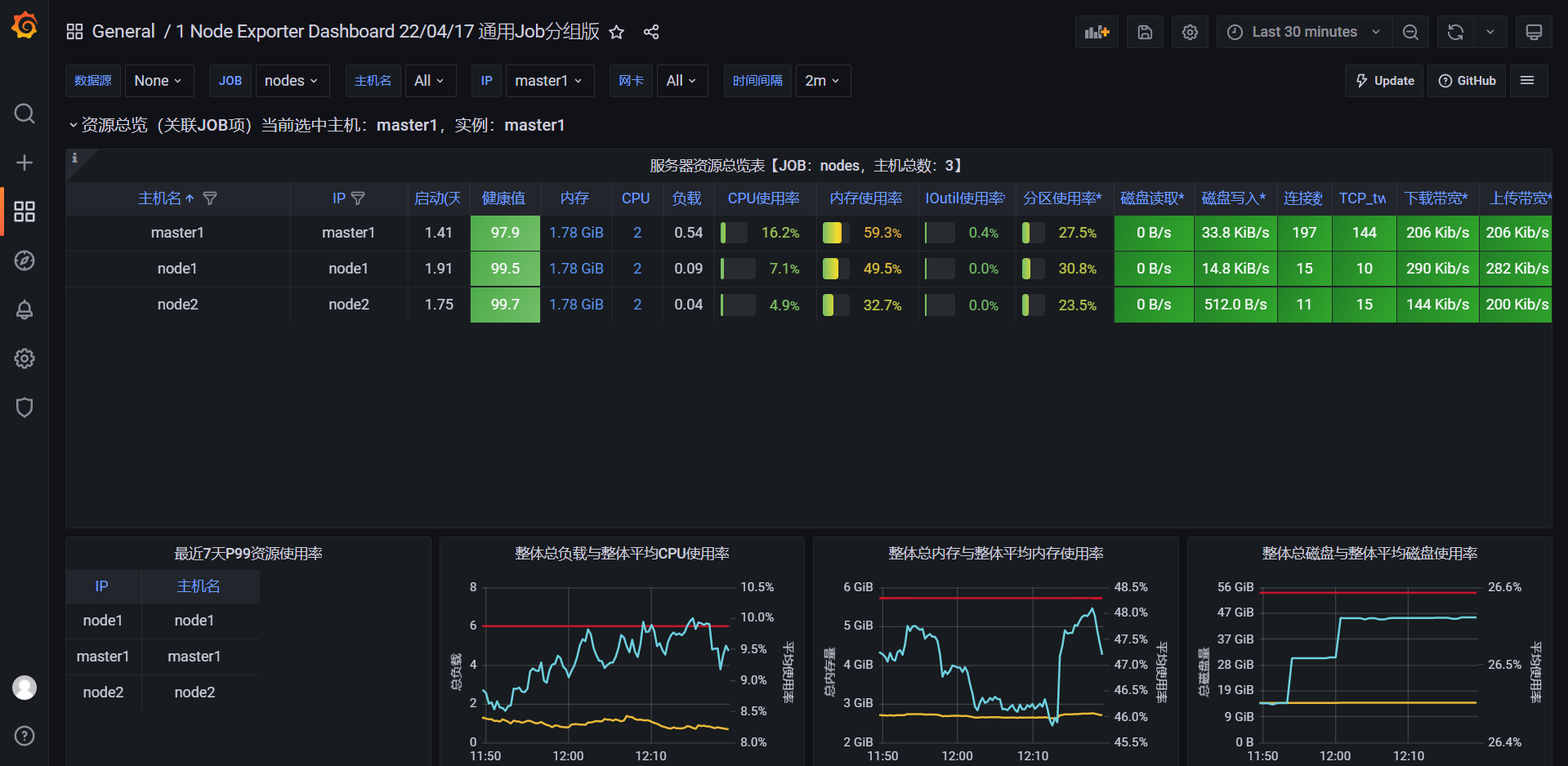
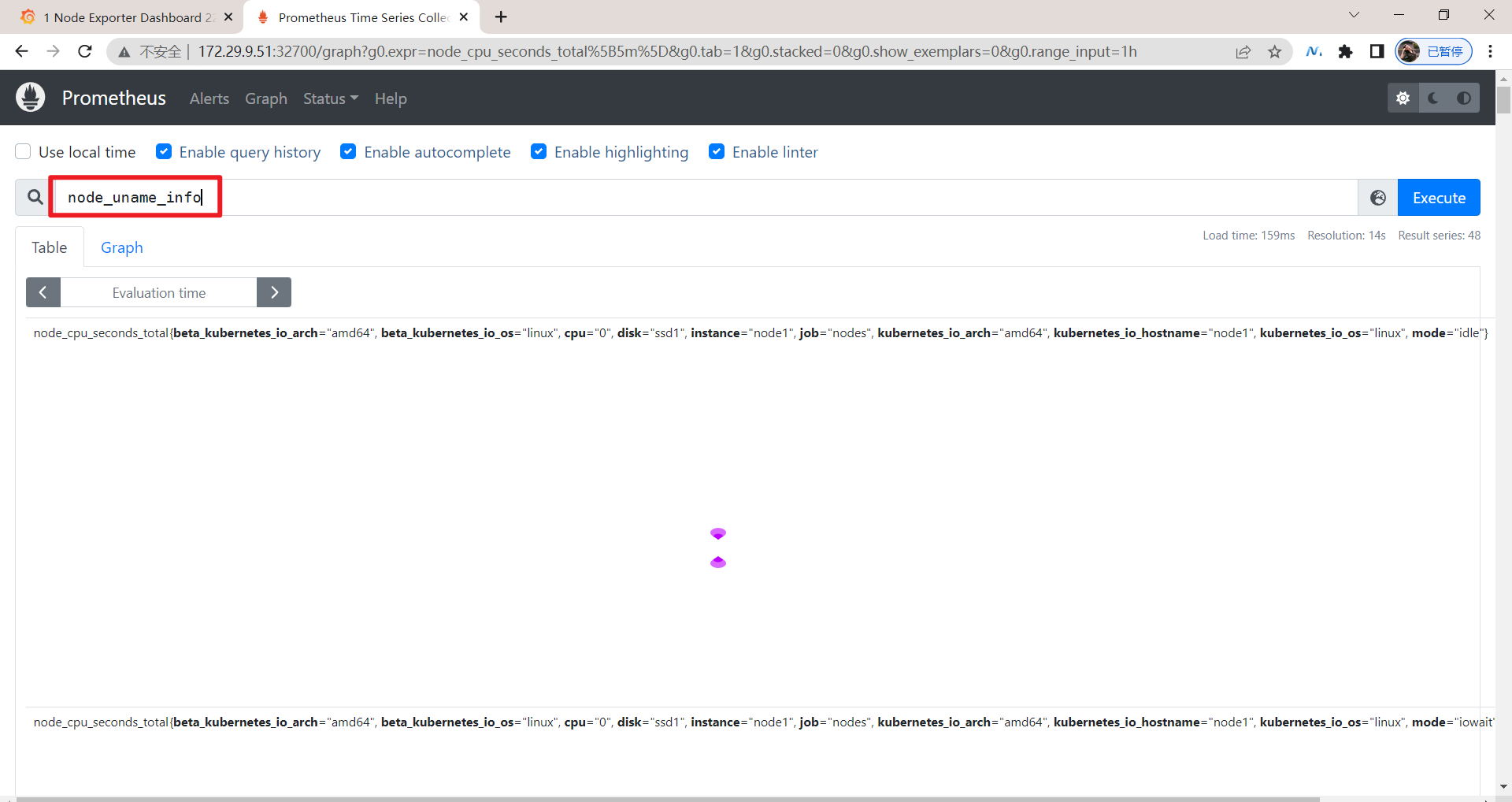
但是,这里的ip不对,我们来修正下:
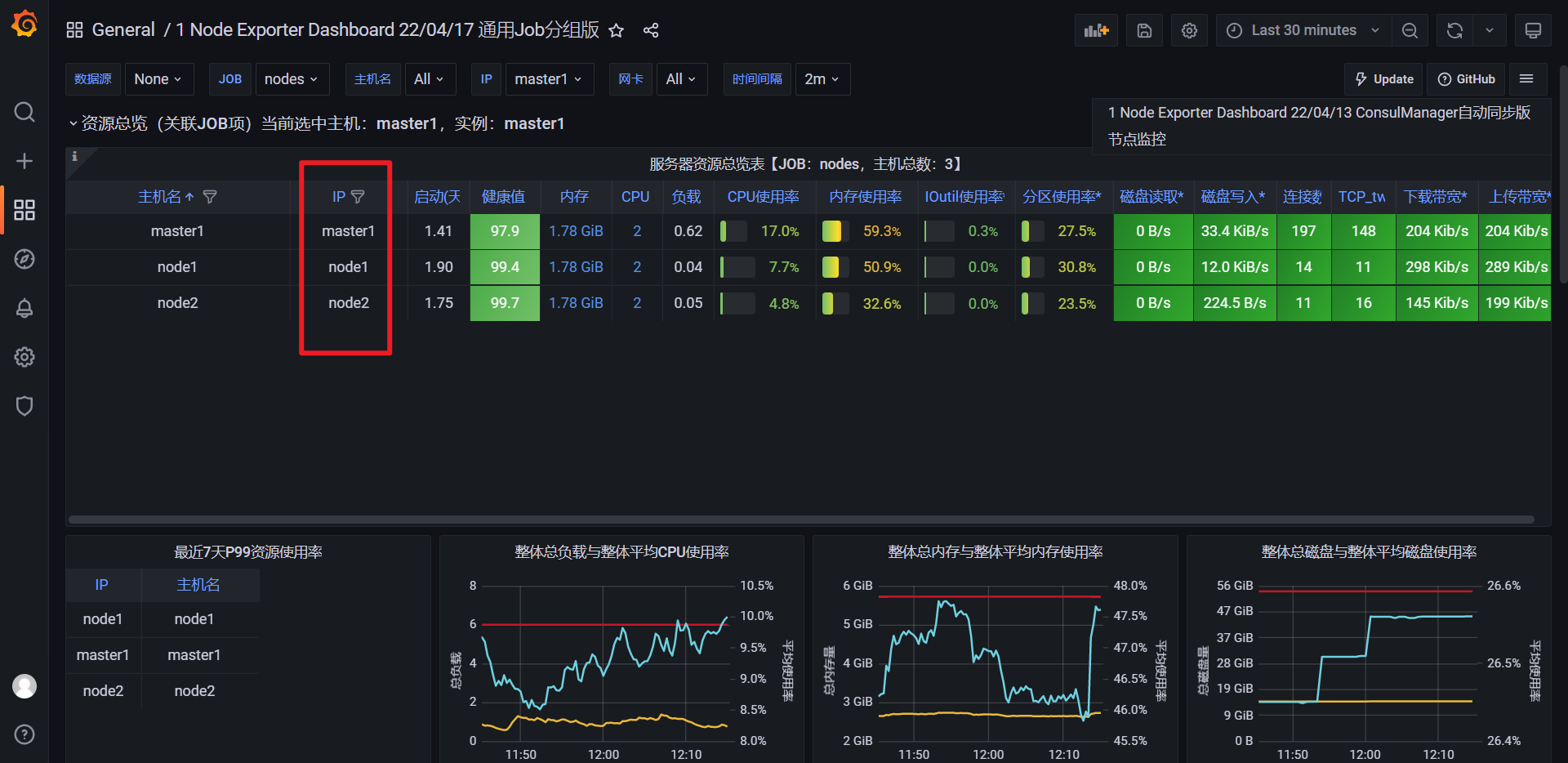
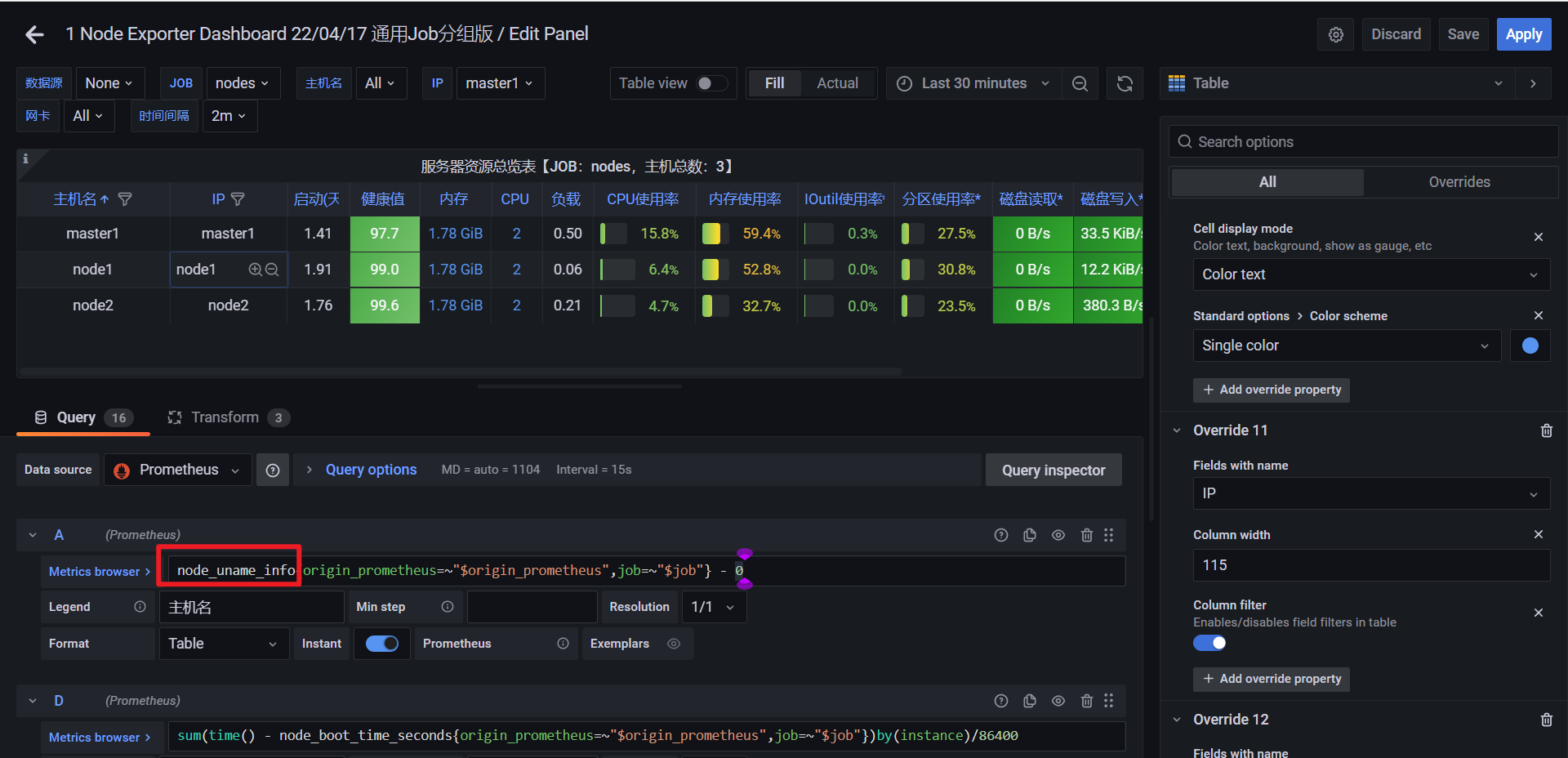
可以看到node_uname_info没有输出ip的,这里隐藏起来就好:
💘 实战2:k8s里部署Grafna(成功测试)-2022.8.20(helm方式)
文档来源
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5
实验软件(无)
1.添加helm仓库
[root@master1 vm-operator]#helm repo add grafana https://grafana.github.io/helm-charts
"grafana" has been added to your repositories
[root@master1 vm-operator]#helm repo update
2.自定义values.yaml文件并部署
-我们可以在 values 中提前定义数据源和内置一些 dashboard,如下所示:
cat <<EOF | helm install grafana grafana/grafana -f -
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: victoriametrics
type: prometheus
orgId: 1
url: http://vmselect-vmcluster-demo.default.svc.cluster.local:8481/select/0/prometheus/
access: proxy
isDefault: true
updateIntervalSeconds: 10
editable: true
dashboardProviders:
dashboardproviders.yaml:
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: true
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards:
default:
victoriametrics:
gnetId: 11176
revision: 18
datasource: victoriametrics
vmagent:
gnetId: 12683
revision: 7
datasource: victoriametrics
kubernetes:
gnetId: 14205
revision: 1
datasource: victoriametrics
EOF
NAME: grafana
LAST DEPLOYED: Tue May 17 17:13:14 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.default.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: admin
######################################################################################################
######## WARNING: Persistence is disabled!!! You will lose your data when ######
######## the Grafana pod is terminated. ######
######################################################################################################
#本次log
W0818 12:14:16.833439 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0818 12:14:16.835043 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0818 12:14:17.014946 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0818 12:14:17.015087 52050 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: grafana
LAST DEPLOYED: Thu Aug 18 12:14:16 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.default.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: admin
######################################################################################################
######## WARNING: Persistence is disabled!!! You will lose your data when ######
######## the Grafana pod is terminated. ######
######################################################################################################
👉 说明:
```yaml
cat <<EOF | helm install grafana grafana/grafana -f -
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: victoriametrics
type: prometheus
orgId: 1
url: http://vmselect-vmcluster-demo.default.svc.cluster.local:8481/select/0/prometheus/ #这里是指定了grafna数据源的
access: proxy
isDefault: true
updateIntervalSeconds: 10
editable: true
dashboardProviders:
dashboardproviders.yaml: #个人对这个不是太清楚呀。。。
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: true
editable: true
options:
path: /var/lib/grafana/dashboards/default
dashboards: #注意:这里是默认安装在grafna里的dashboard
default:
victoriametrics:
gnetId: 11176
revision: 18
datasource: victoriametrics
vmagent:
gnetId: 12683
revision: 7
datasource: victoriametrics
kubernetes:
gnetId: 14205
revision: 1
datasource: victoriametrics
EOF
3.验证
- 安装完成后可以使用上面提示的命令在本地暴露 Grafana 服务:
☸ ➜ export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
登录的用户名为 admin,密码可以通过下面的命令获取:
[root@master1 ~]#kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
GcVlzxMsneJoa8PDBeDMHHQmUeAfA9zAWRLmAM7i
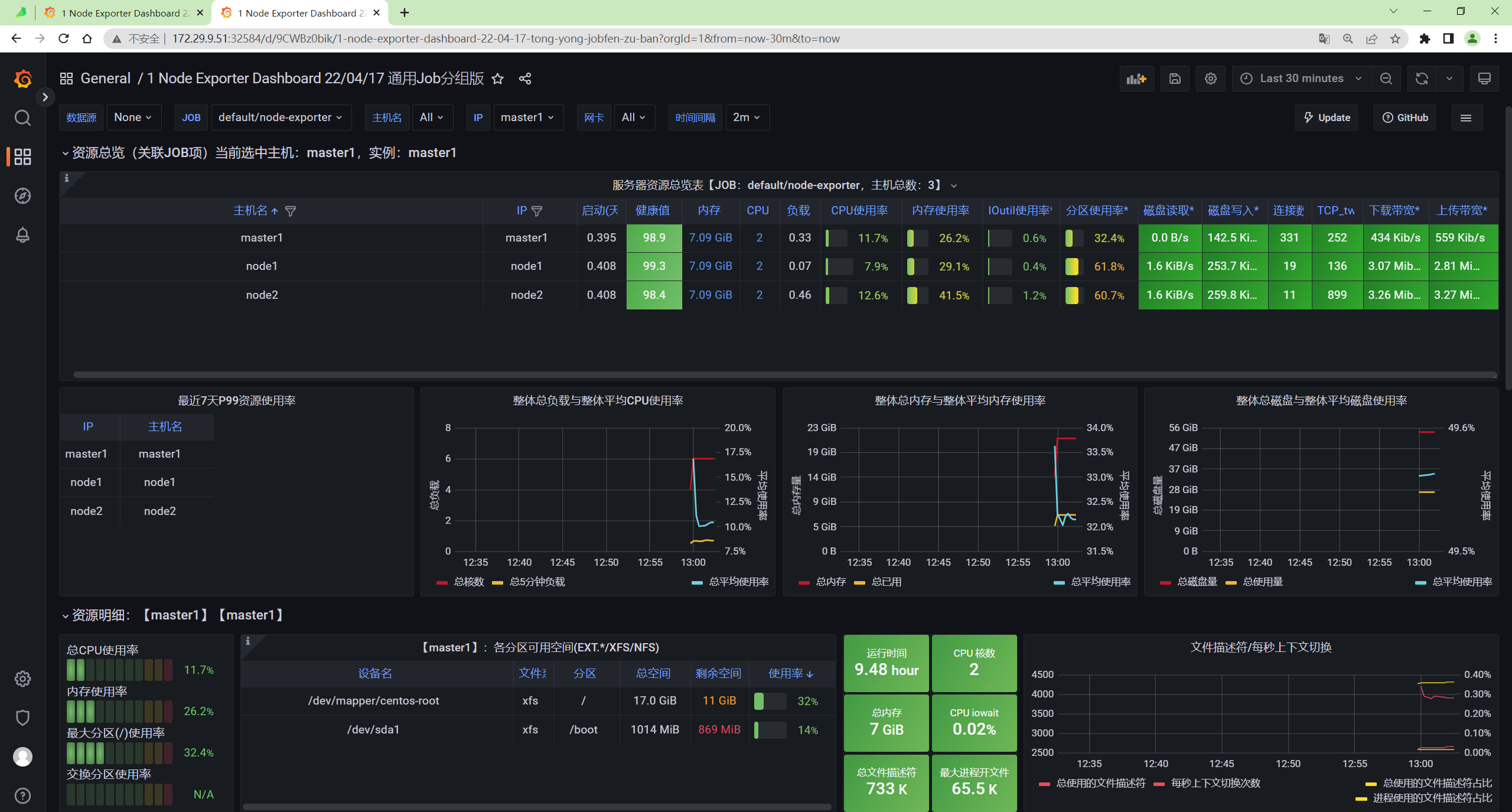
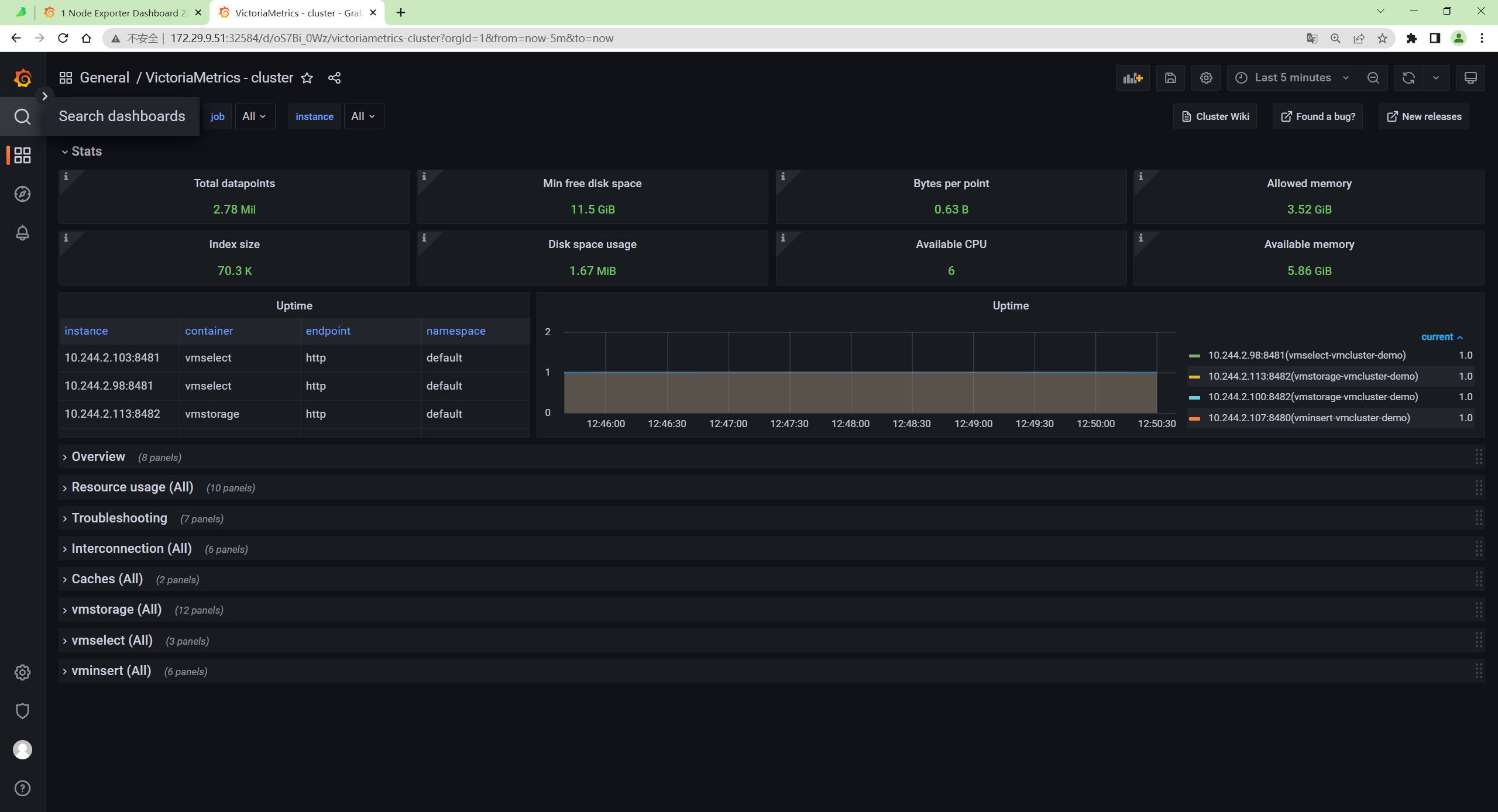
我们可以查看下 victoriametrics cluster 的 dashboard:
127.0.0.1:3000/dashboards
正常可以看到如下所示的页面:
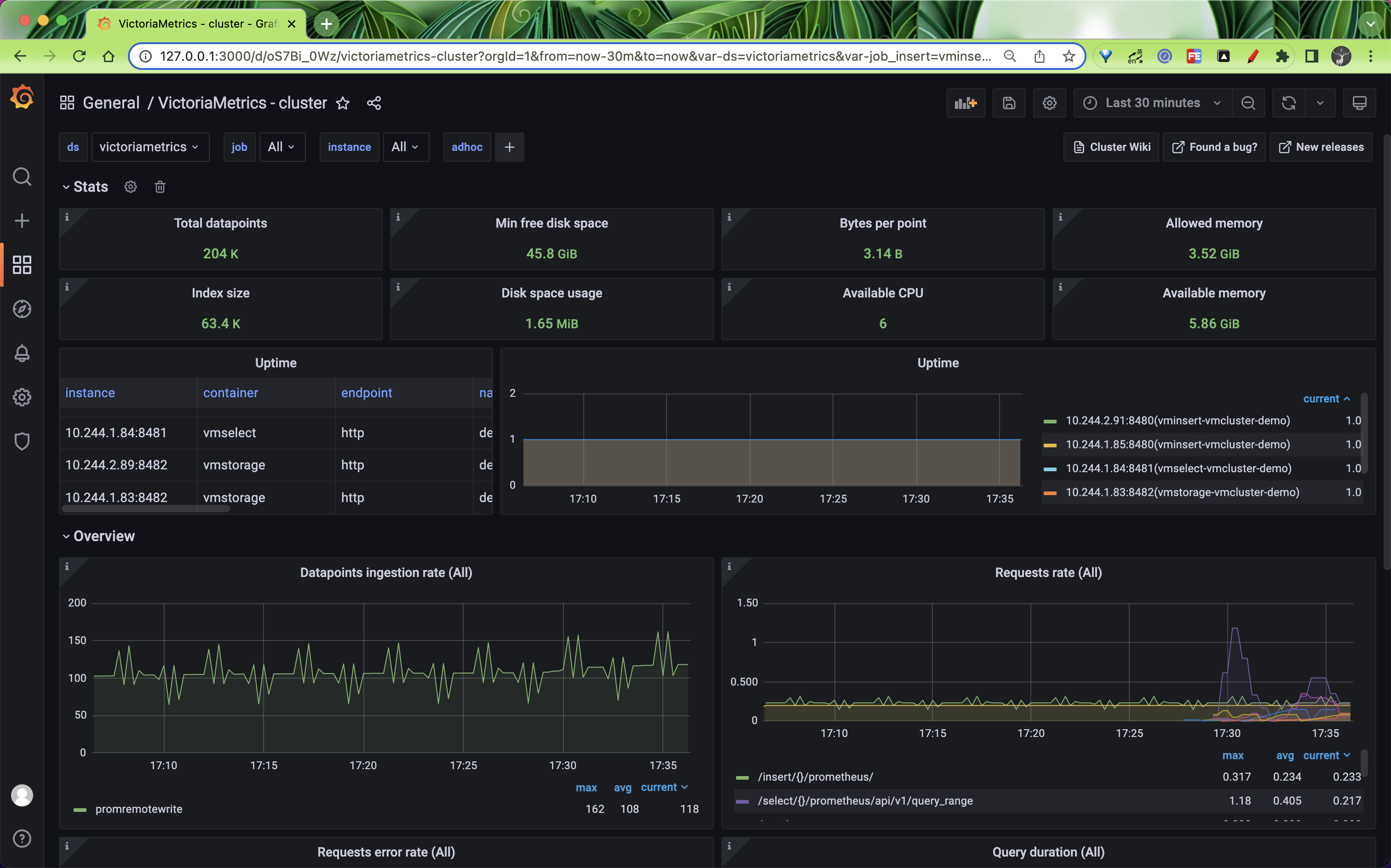
这是因为默认情况下 VMAgent 会采集 VM 集群相关组件的指标,包括 vmagent 本身的,所以我们可以正常看到 VM 集群的 Dashboard。
注意:这里又和之前一样的现象……
利用kubectl --namespace default port-forward $POD_NAME 3000命令后,依然无法在本地用127.0.0.1:3000来访问
于是自己将grafana这个svc的类型变为NodePort,再访问就正常了:
kubectl edit svc grafana
……
type: NodePort
……
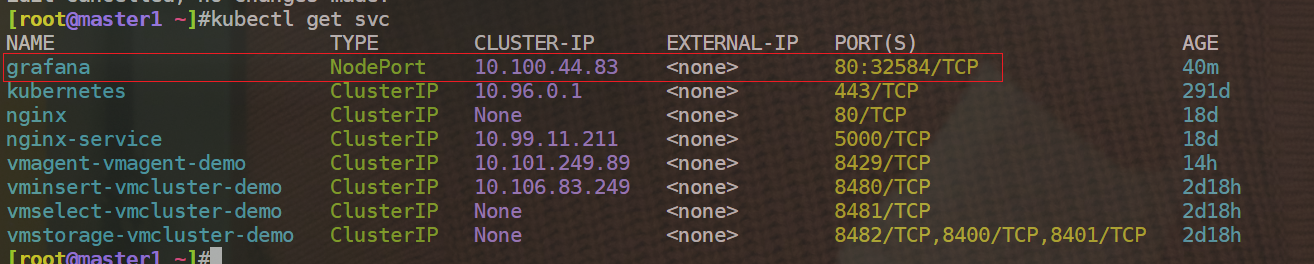
自己本次现象:
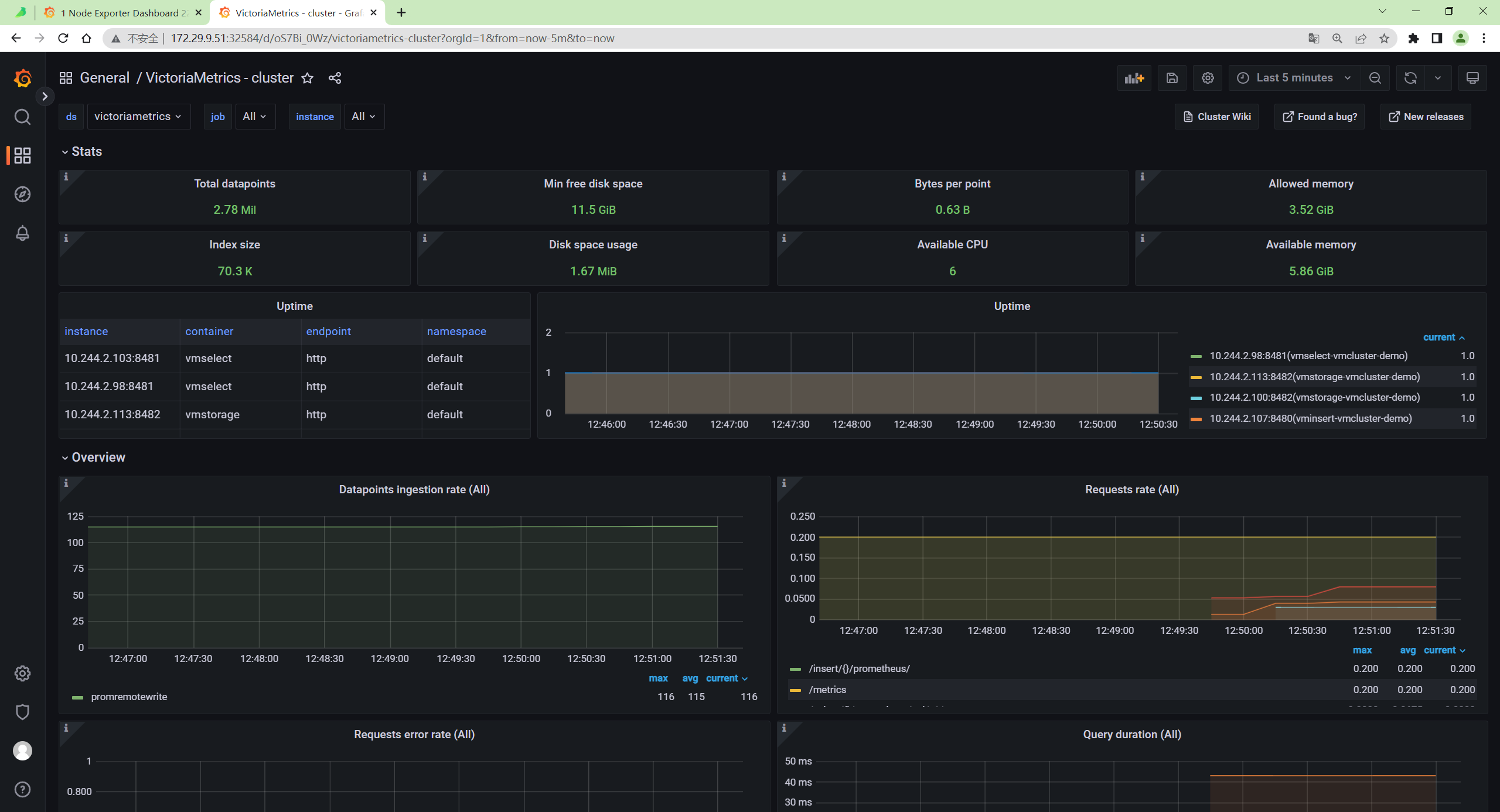
安装完成。😘
3、自定义图表
导入现成的第三方 Dashboard 或许能解决我们大部分问题,但是毕竟还会有需要定制图表的时候,这个时候就需要了解如何去自定义图表了。
同样在侧边栏点击 "+",选择 Dashboard,然后选择 Add new panel 创建一个图表:
然后在下方 Query 栏中选择 Prometheus 这个数据源:
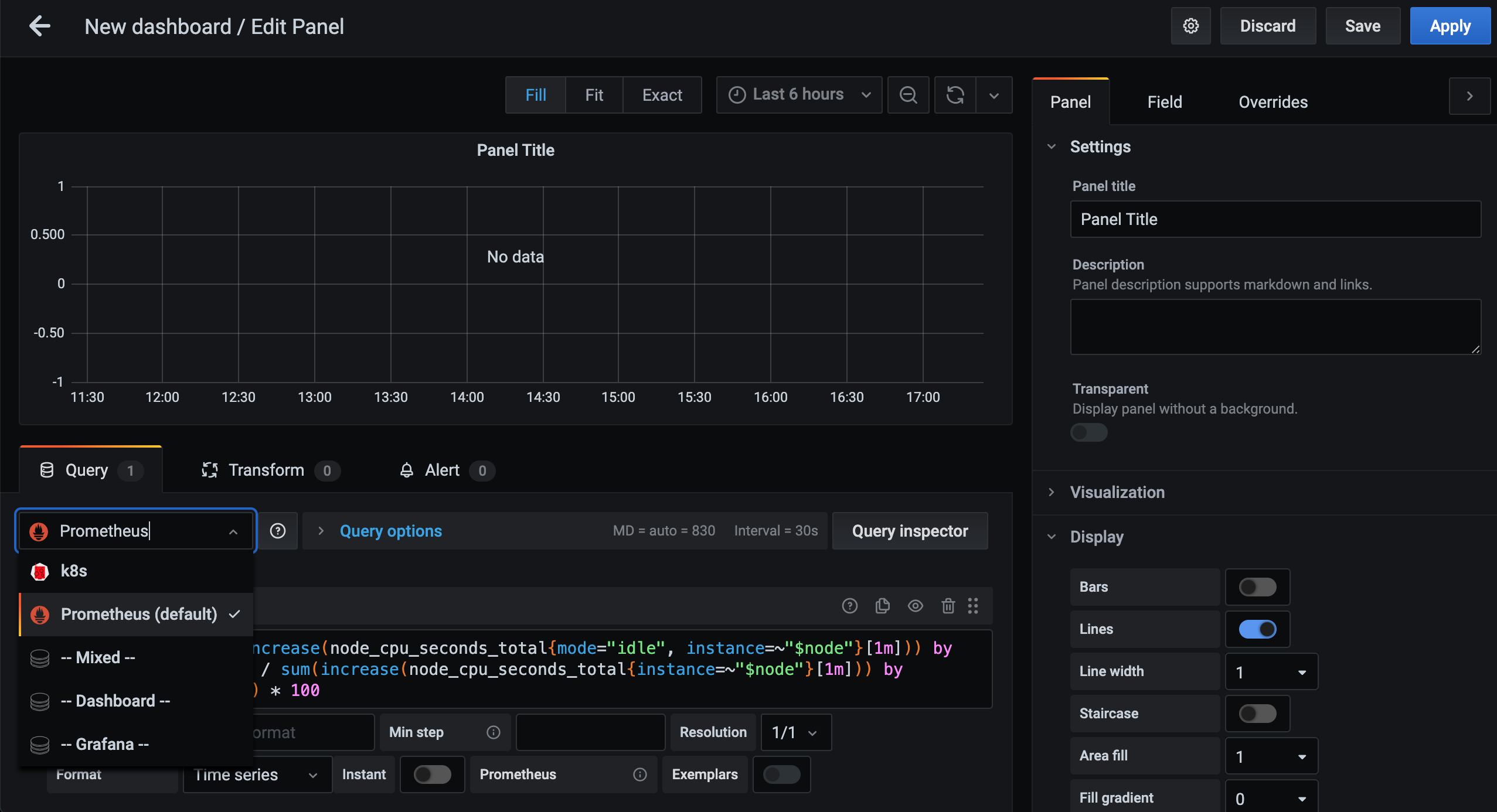
然后在 Metrics 区域输入我们要查询的监控 PromQL 语句,比如我们这里想要查询集群节点 CPU 的使用率:
(1 - sum(increase(node_cpu_seconds_total{mode="idle", instance=~"$node"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total{instance=~"$node"}[1m])) by (instance)) * 100
虽然我们现在还没有具体的学习过 PromQL 语句,但其实我们仔细分析上面的语句也不是很困难,集群节点的 CPU 使用率实际上就相当于排除空闲 CPU 的使用率,所以我们可以优先计算空闲 CPU 的使用时长,除以总的 CPU 时长就是使用率了,用 1 减掉过后就是 CPU 的使用率了,如果想用百分比来表示的话则乘以 100 即可。
这里有一个需要注意的地方是在 PromQL 语句中有一个 instance=~"$node" 的标签,其实意思就是根据 $node 这个参数来进行过滤,也就是我们希望在 Grafana 里面通过参数化来控制每一次计算哪一个节点的 CPU 使用率。
所以这里就涉及到 Grafana 里面的参数使用。点击页面顶部的 Dashboard Settings 按钮进入配置页面:
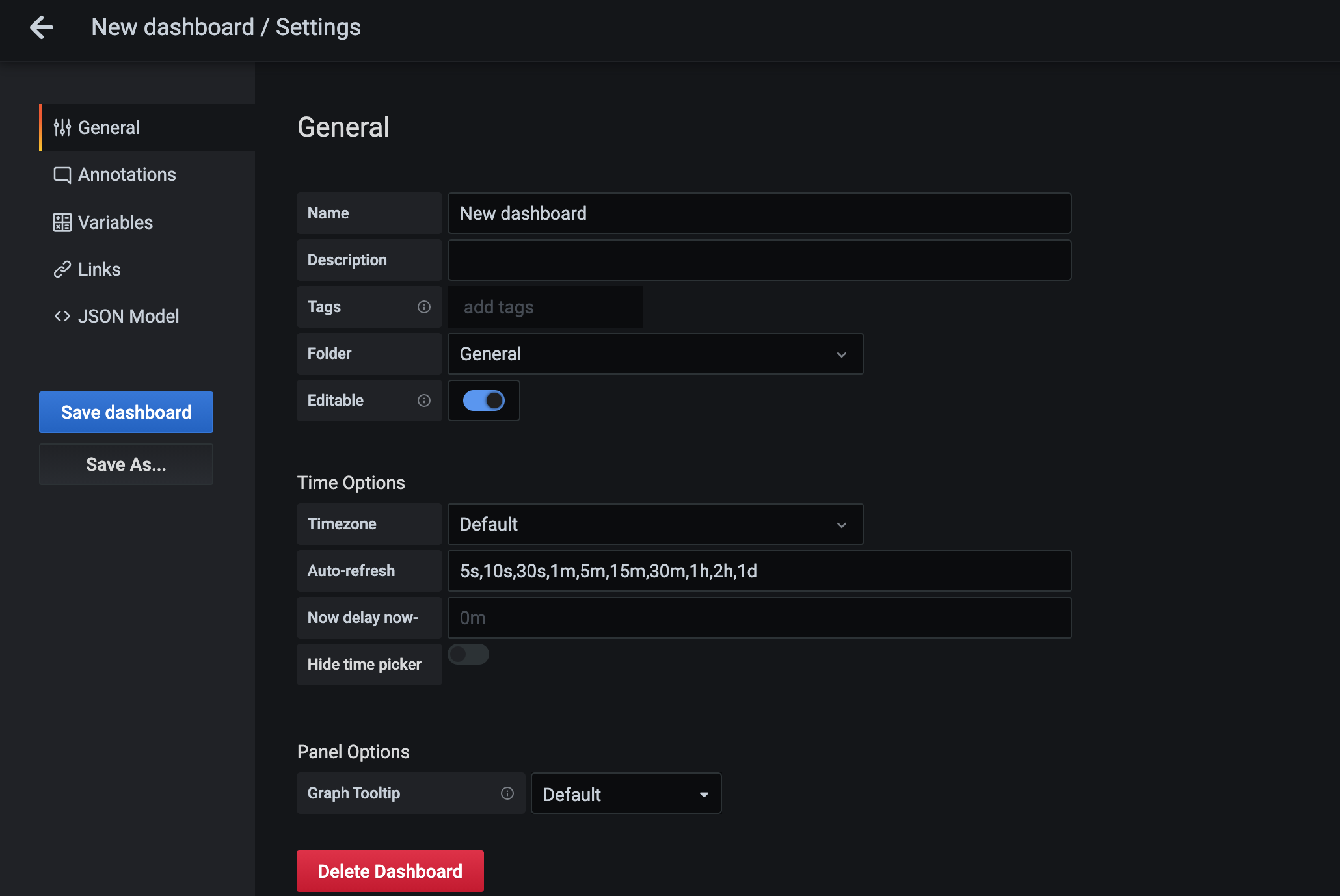
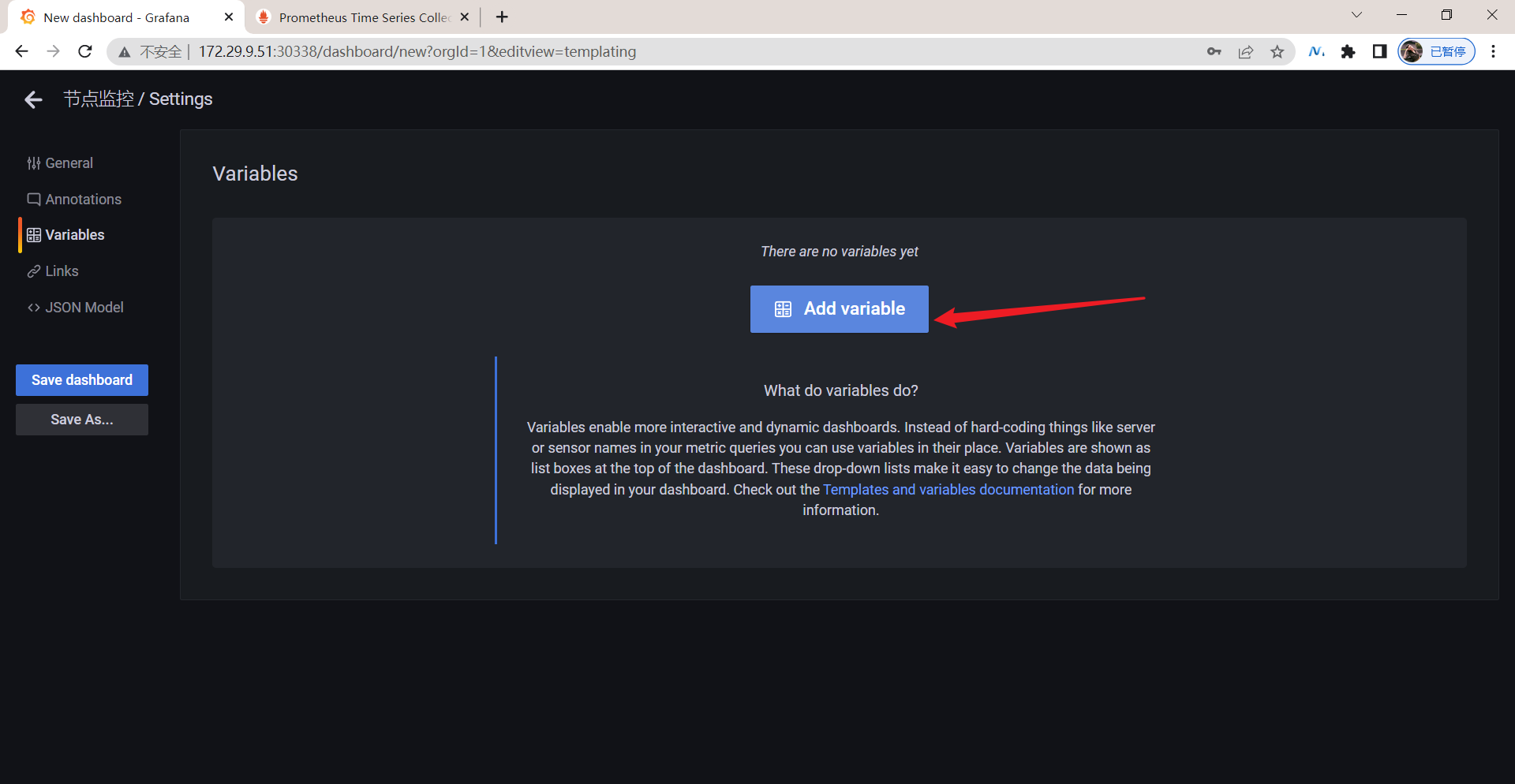
在左侧 tab 栏点击 Variables 进入参数配置页面,如果还没有任何参数,可以通过点击 Add Variable 添加一个新的变量:
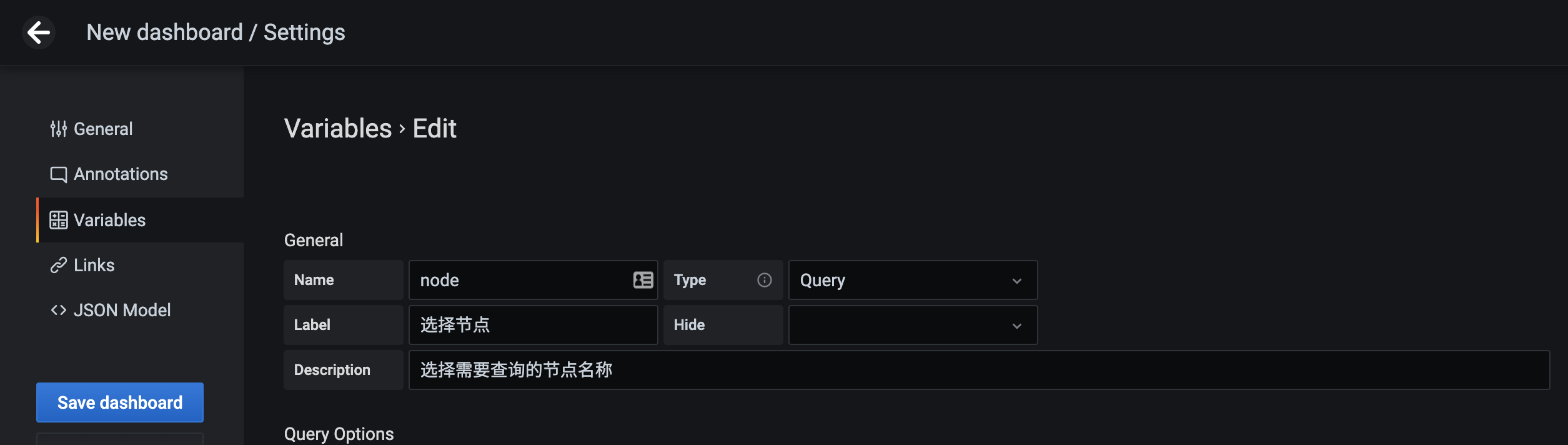
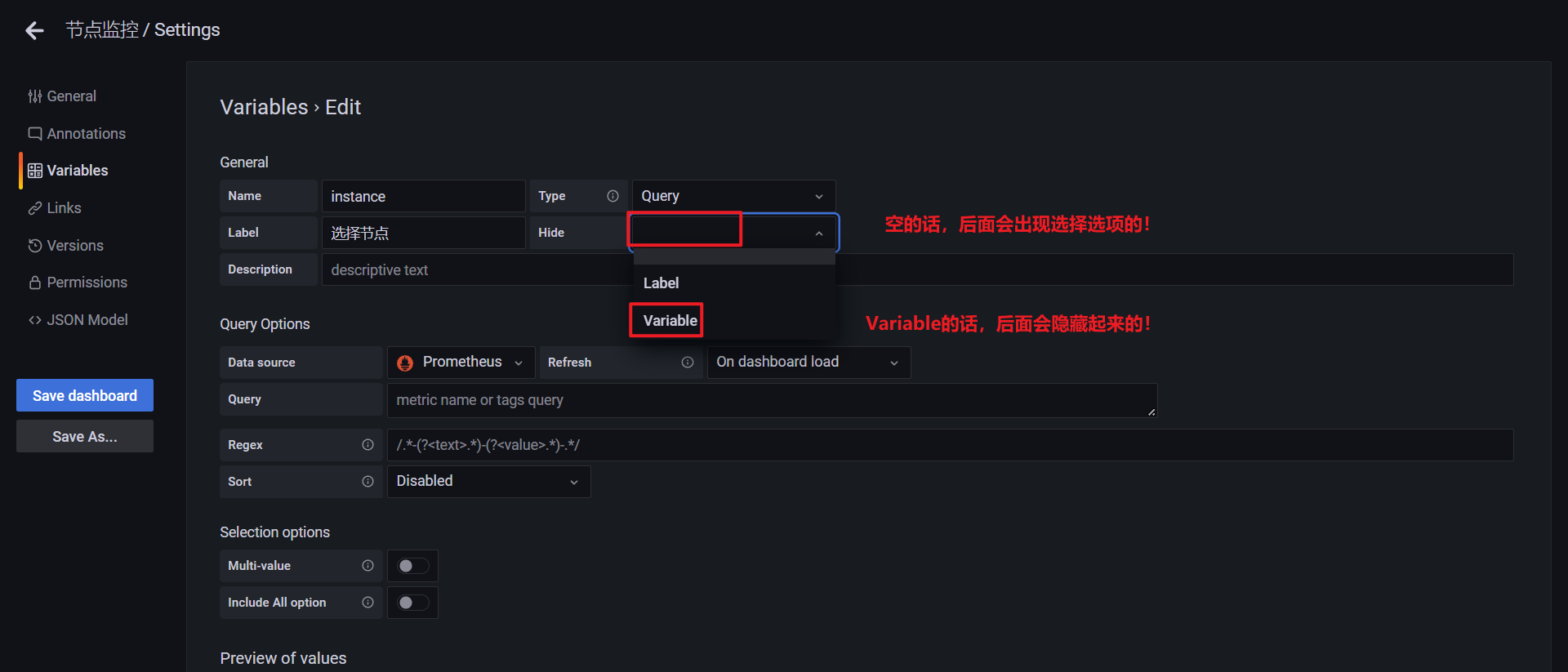
这里需要注意的是变量的名称 node 就是上面我们在 PromQL 语句里面使用的 $node 这个参数,这两个地方必须保持一致,然后最重要的就是参数的获取方式了,比如我们可以通过 Prometheus 这个数据源,通过 kubelet_node_name 这个指标来获取,在 Prometheus 里面我们可以查询该指标获取到的值为:
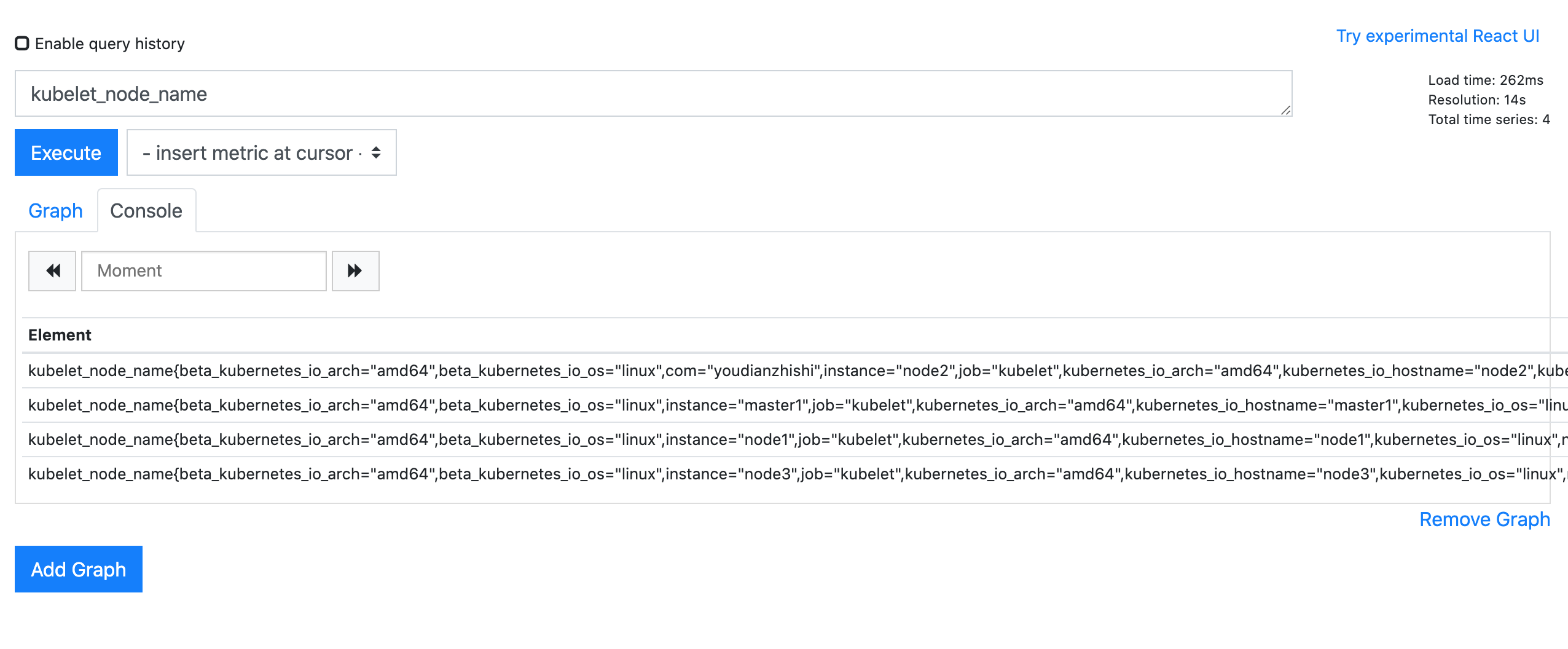
我们其实只是想要获取节点的名称,所以我们可以用正则表达式去匹配 node=xxx 这个标签,将匹配的值作为参数的值即可:
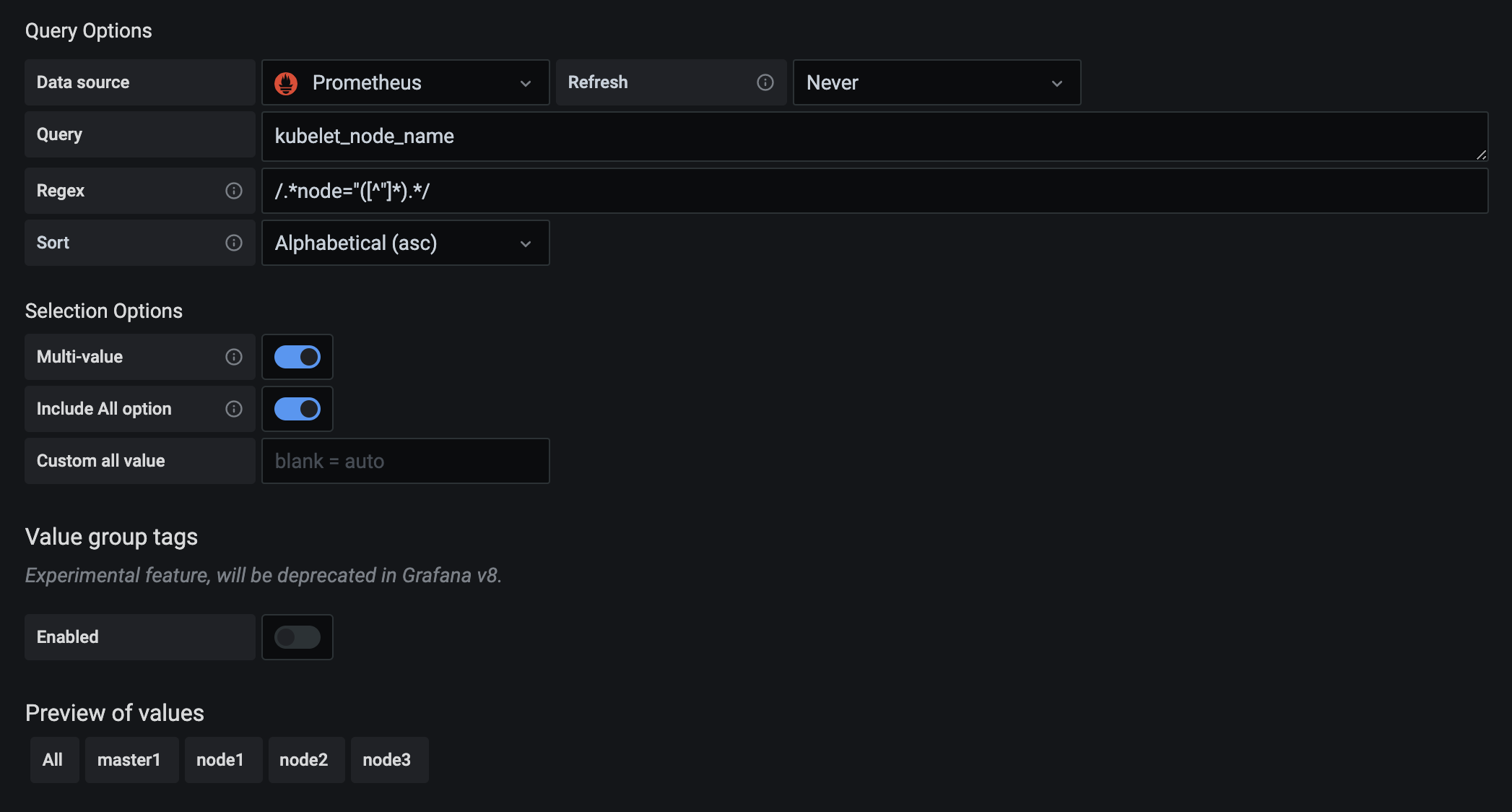
在最下面的 Preview of values 里面会有获取的参数值的预览结果。除此之外,我们还可以使用一个更方便的 label_values 函数来获取,该函数可以用来直接获取某个指标的 label 值:
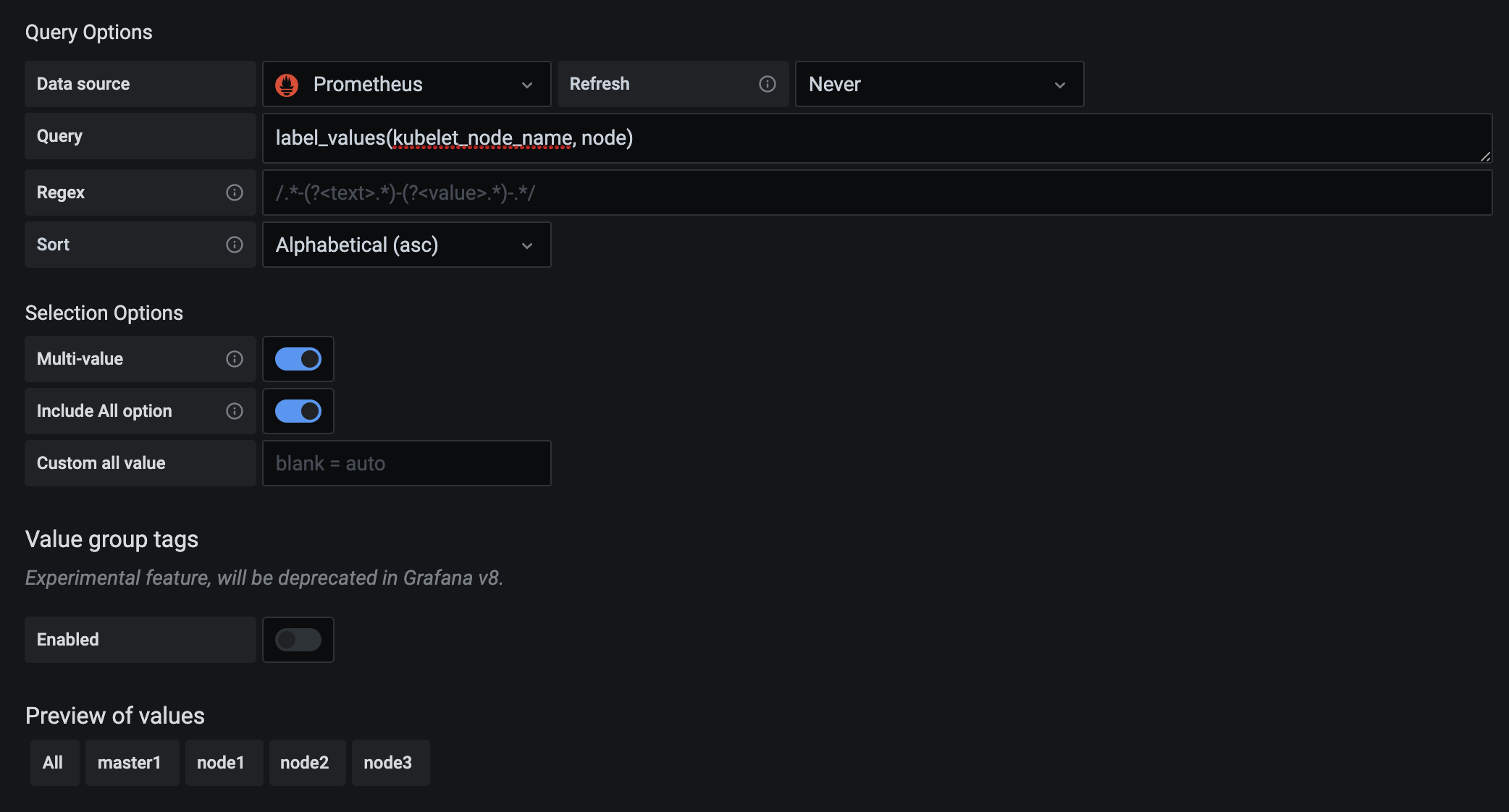
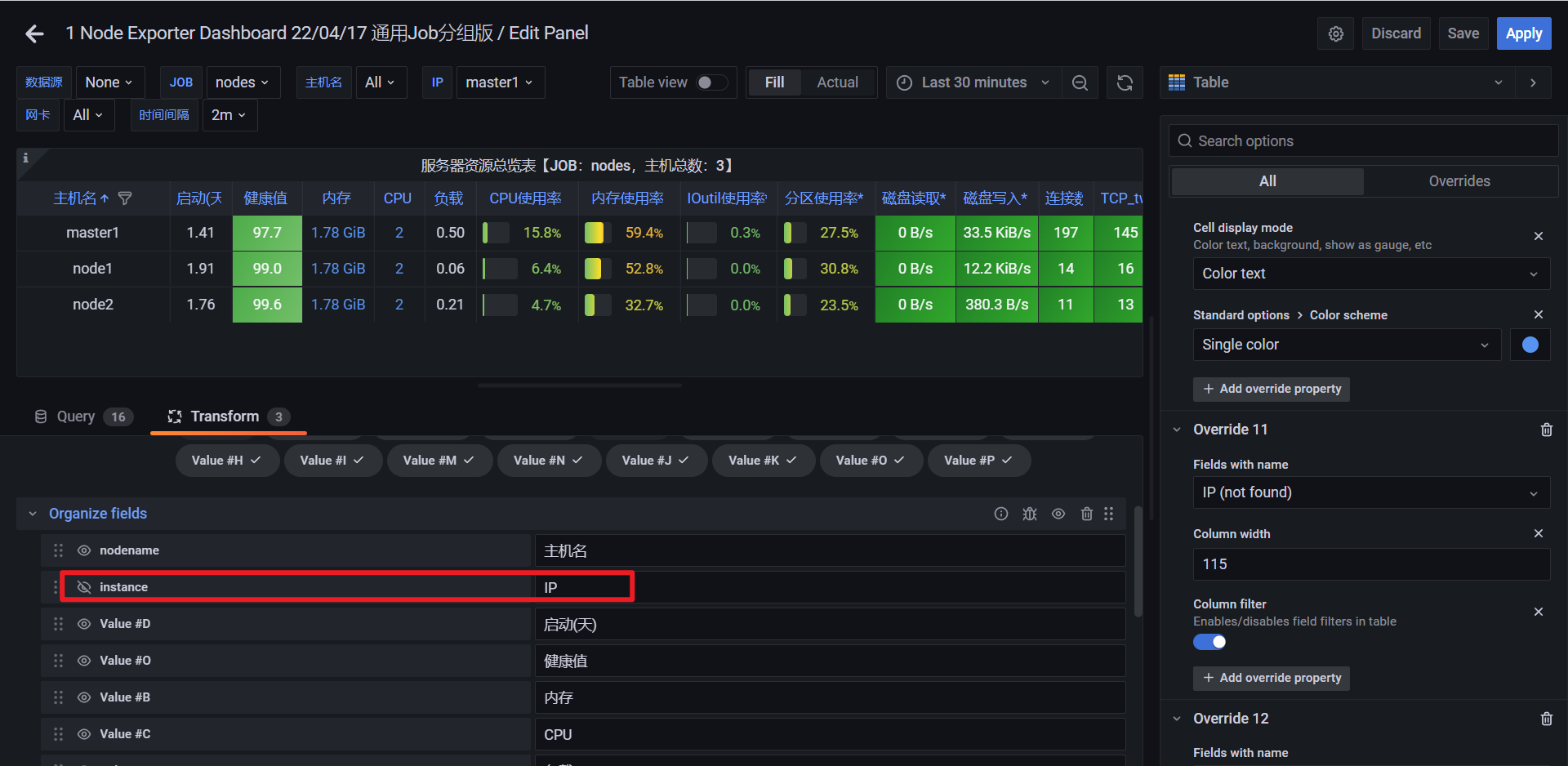
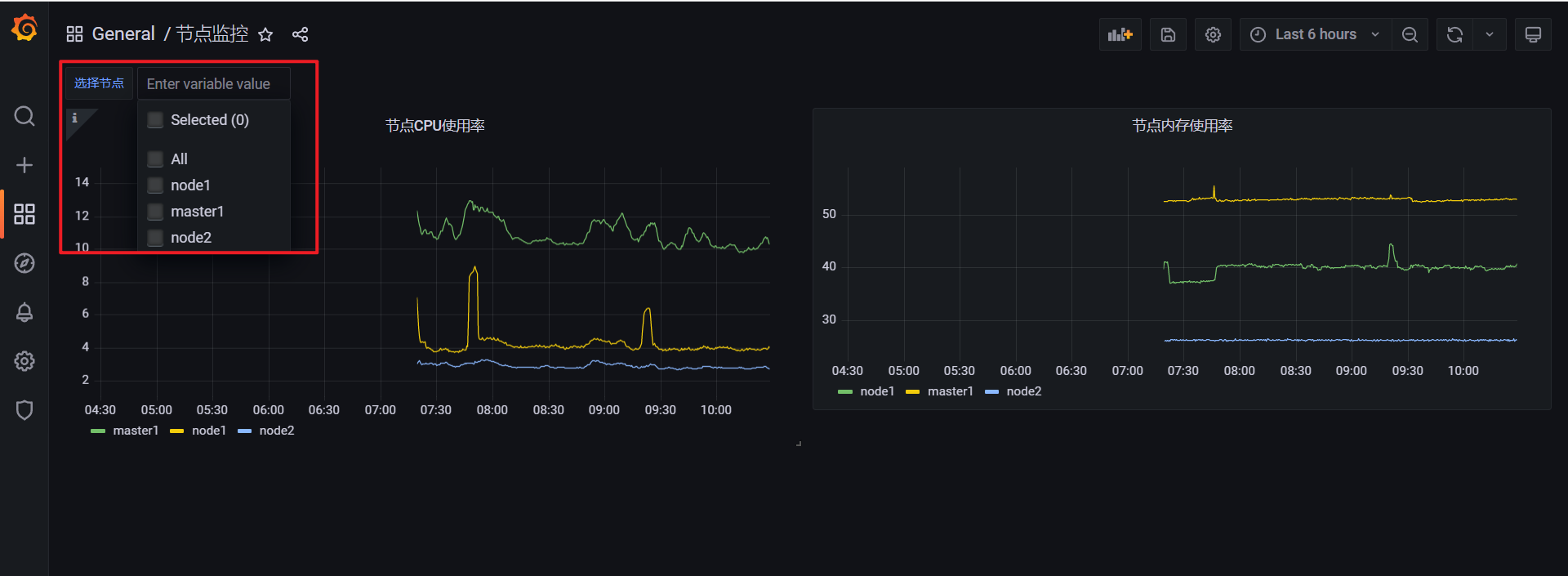
另外由于我们希望能够让用户自由选择一次性可以查询多少个节点的数据,所以我们将 Multi-value 以及 Include All option 都勾选上了,最后记得保存,保存后跳转到 Dashboard 页面就可以看到我们自定义的图表信息:
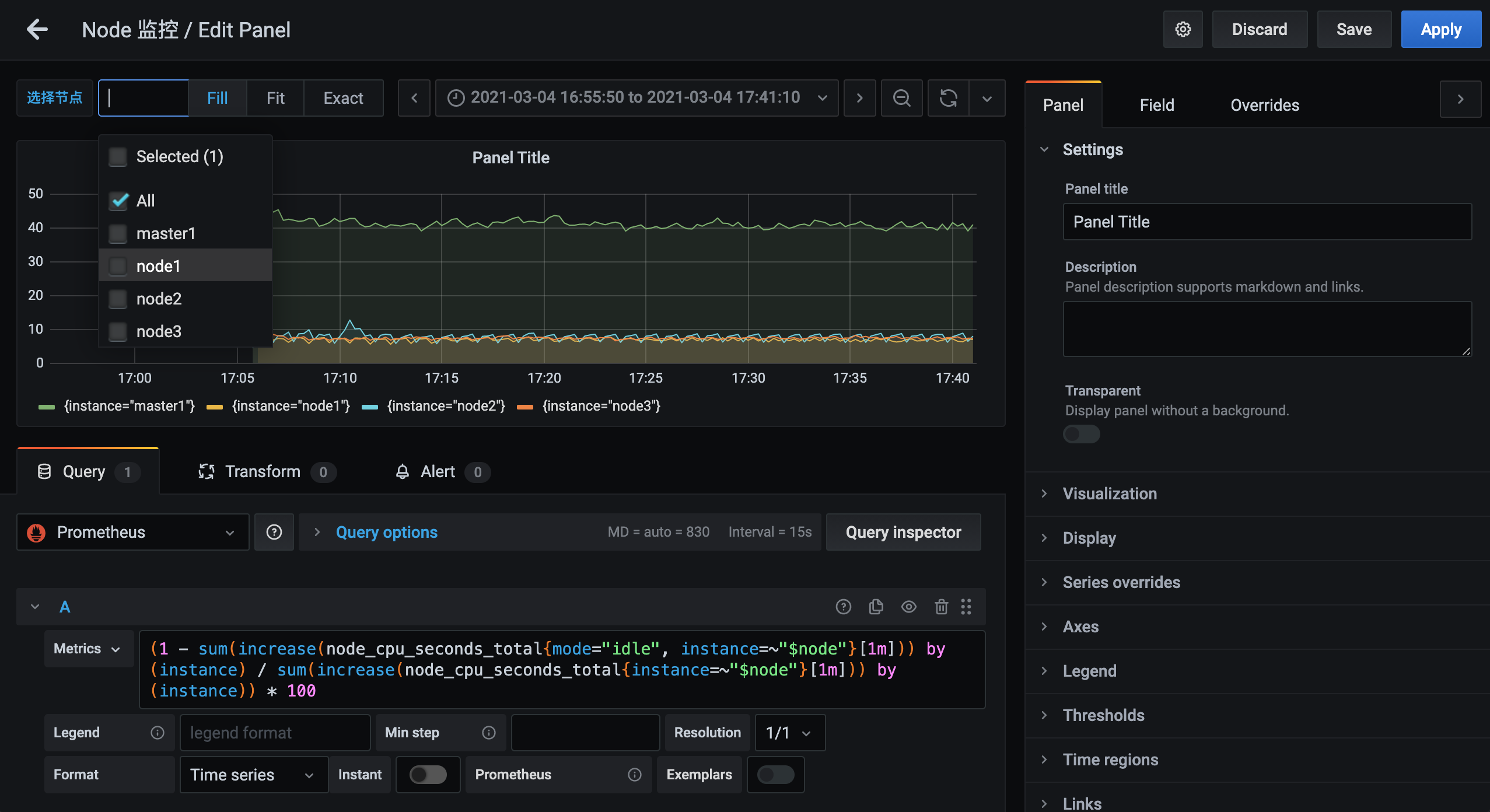
而且还可以根据参数选择一个或者多个节点,当然图表的标题和大小都可以自由去更改:
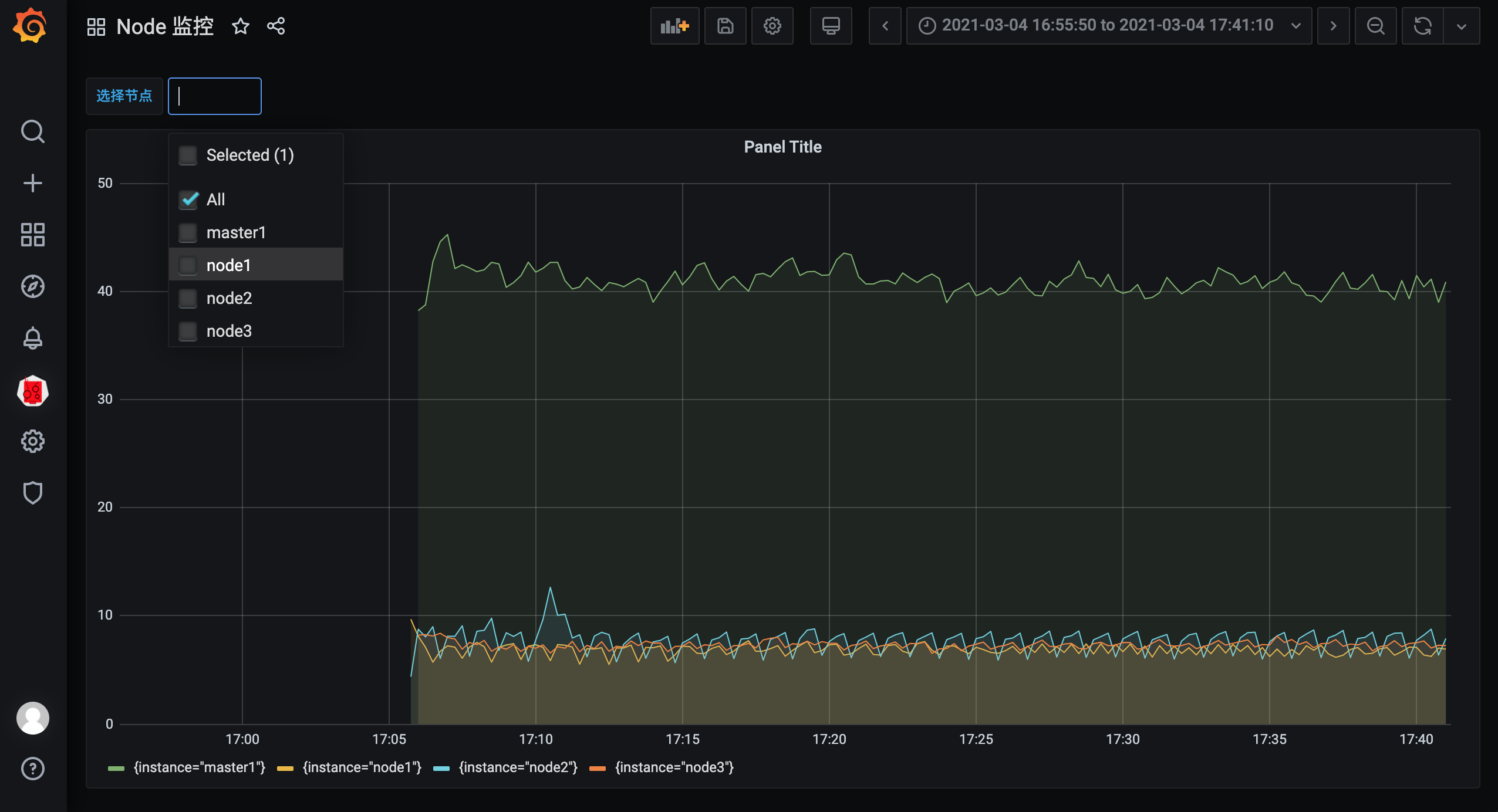
🍀 自己实际测试过程
创建pannel和row:
一般,同一类监控放在一个row中;
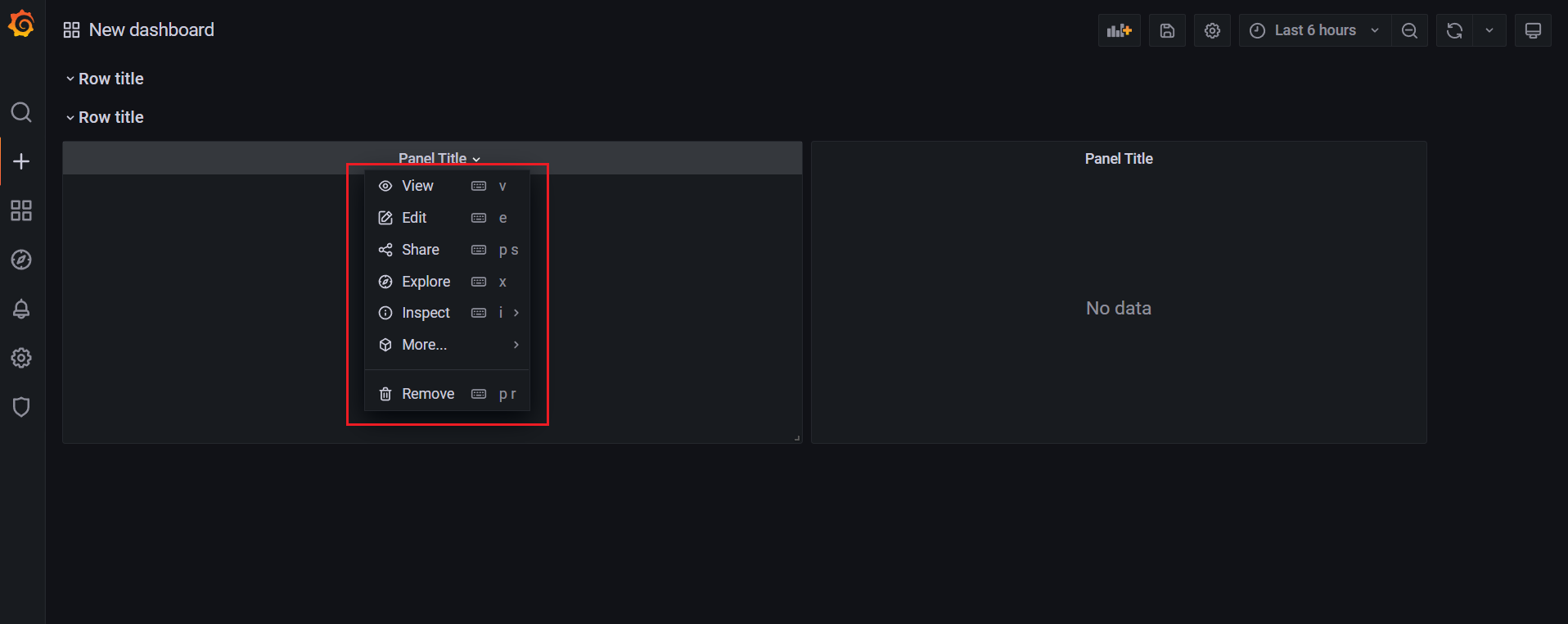
🍀 query
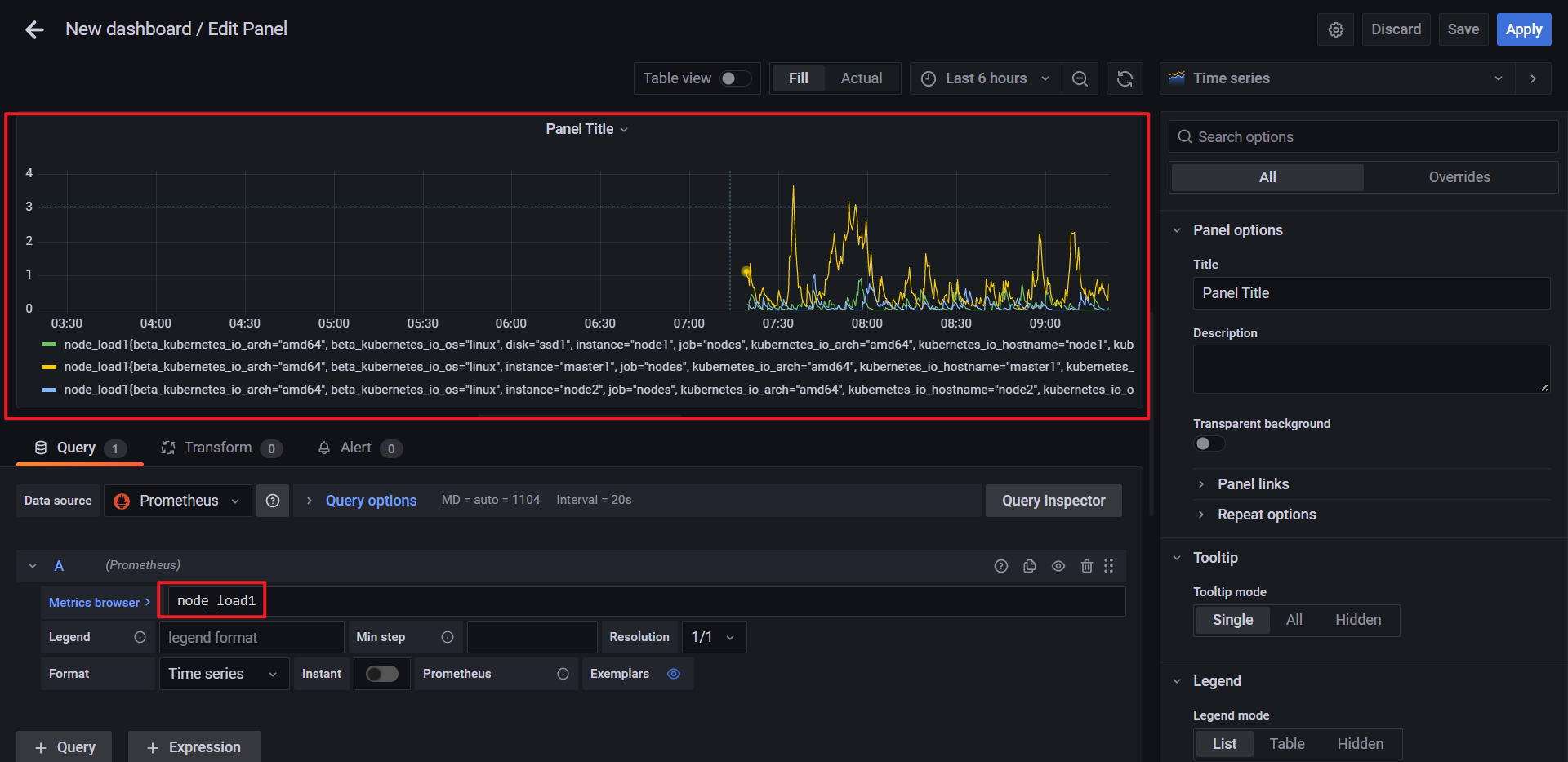
🍀 只显示instance
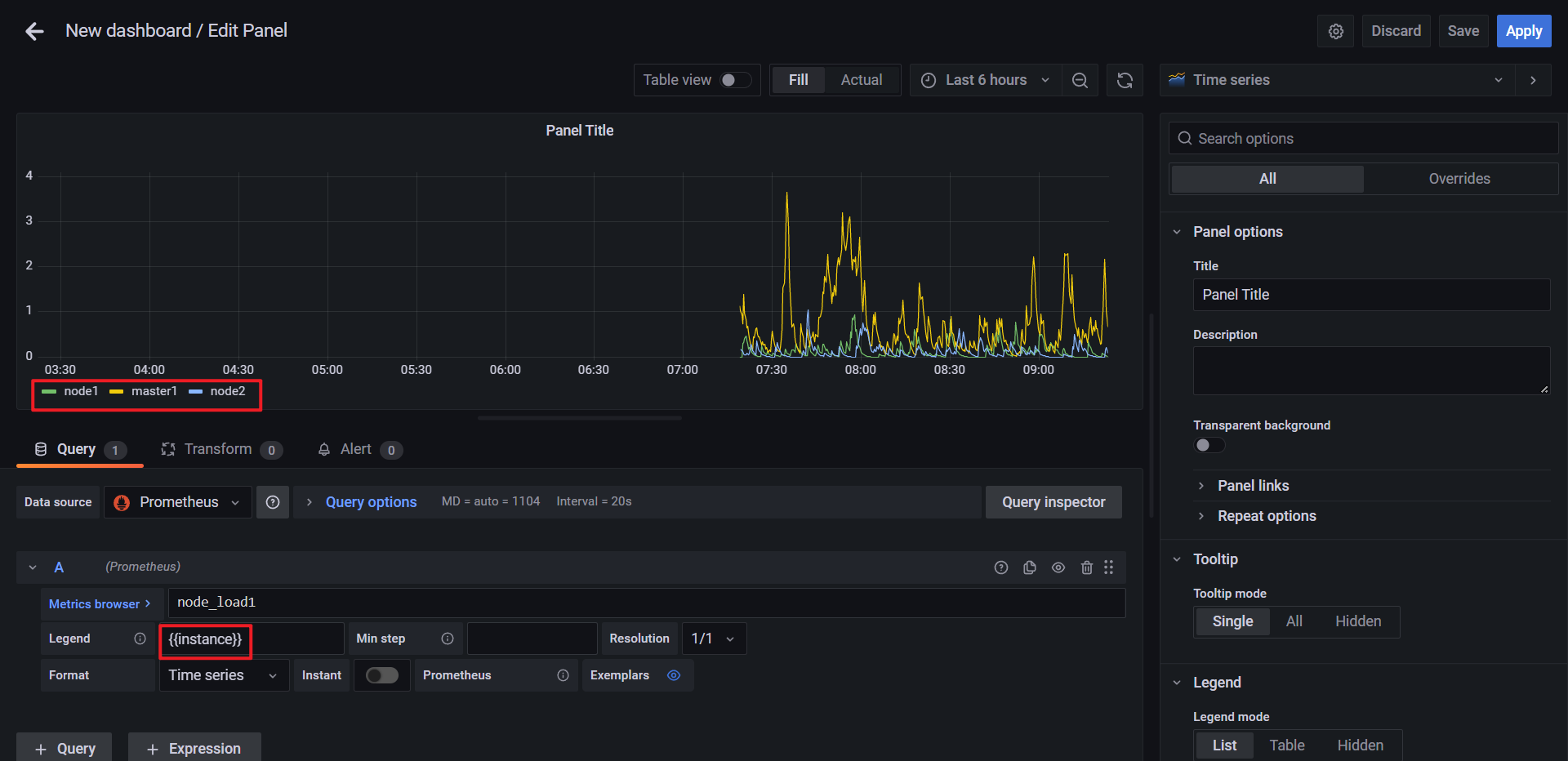
🍀 pannel标题及描述
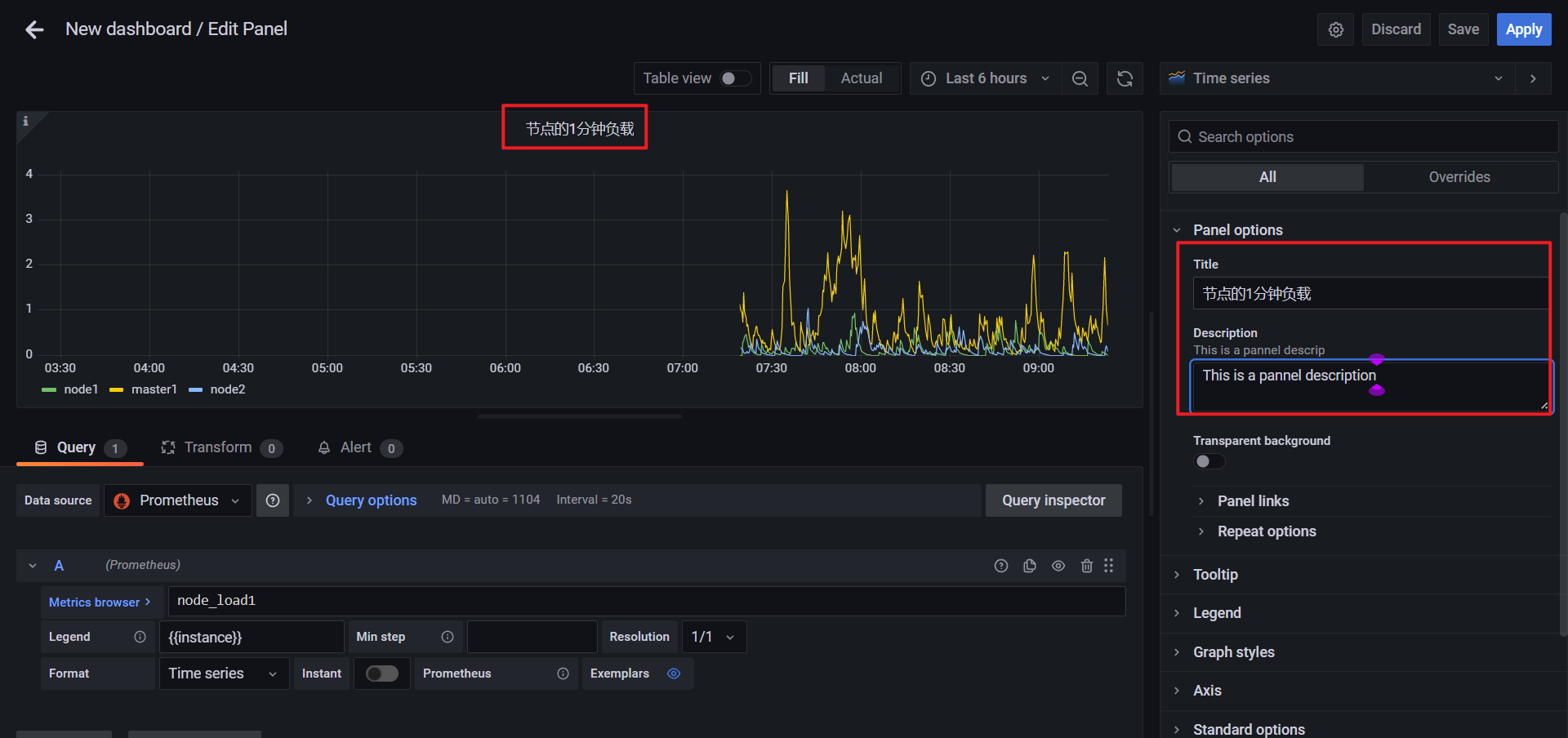
🍀 点击Time series:(重点来看这个就好)
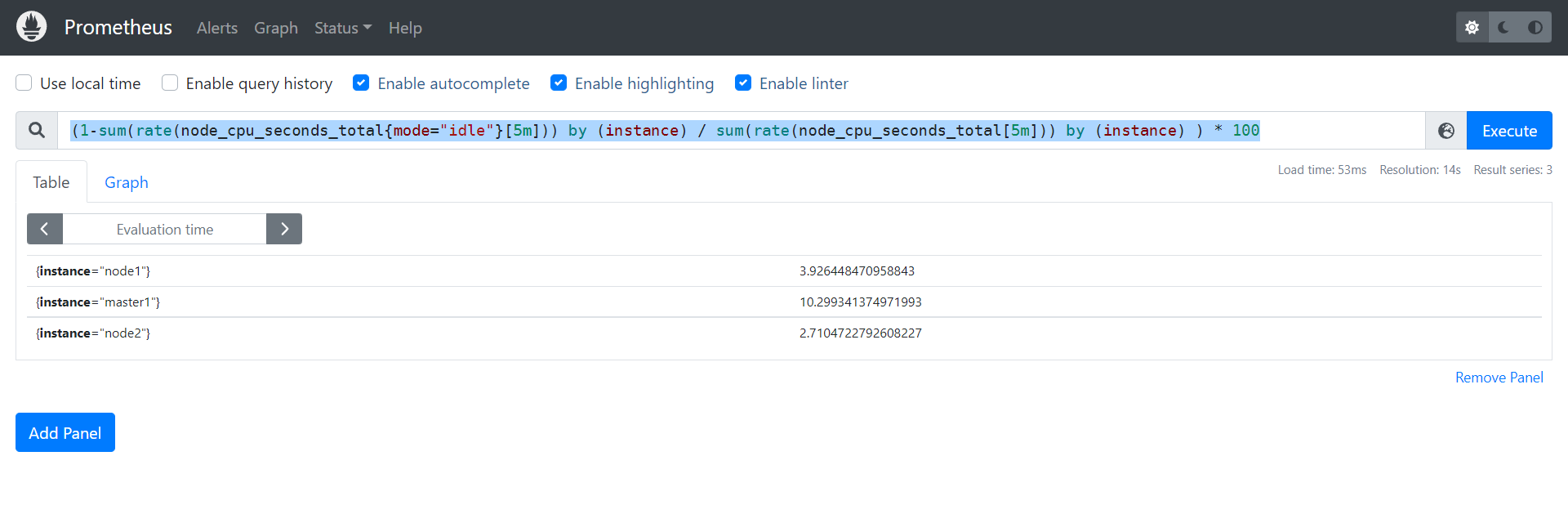
🍀 测试:查询CPU使用率
(1-sum(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) / sum(rate(node_cpu_seconds_total[5m])) by (instance) ) * 100
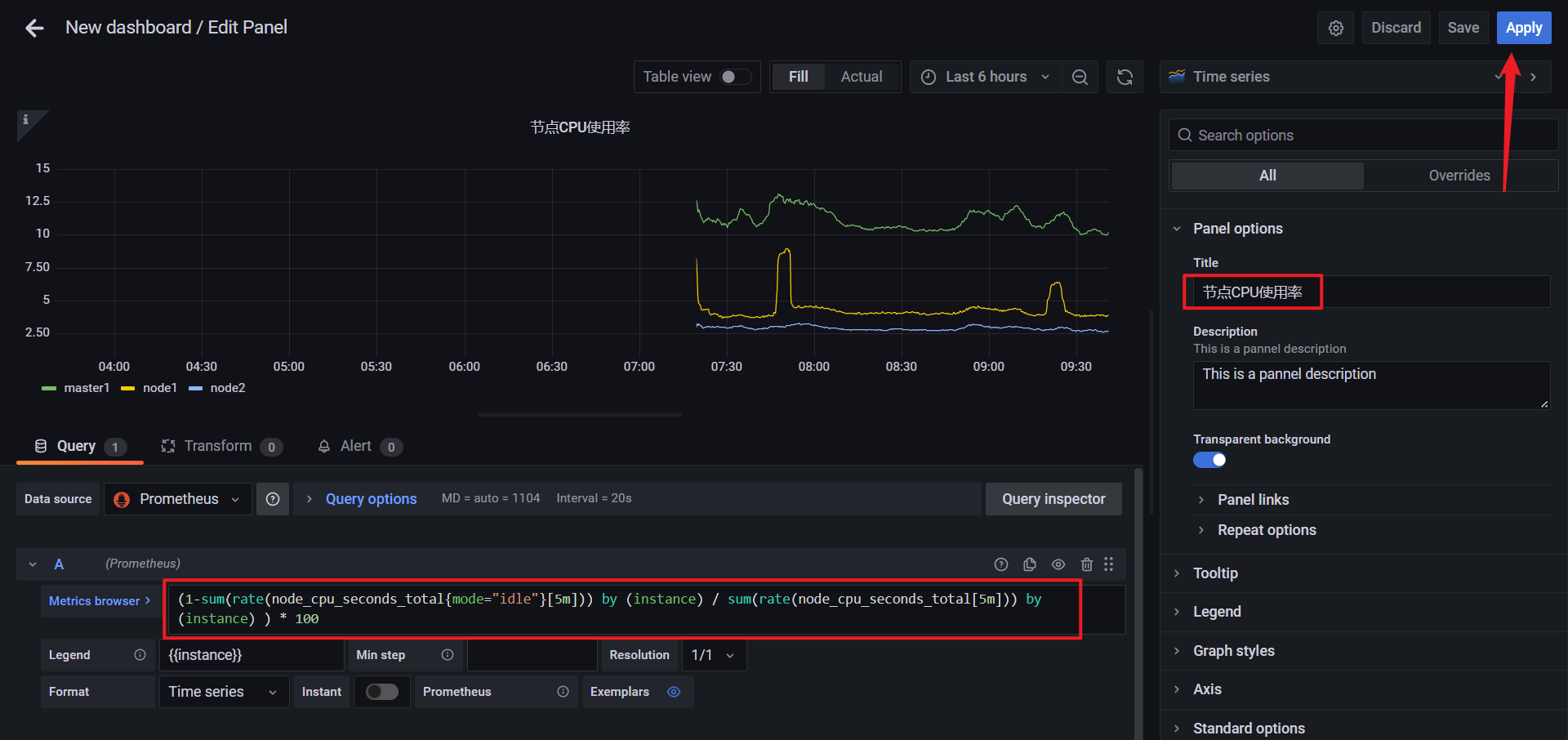
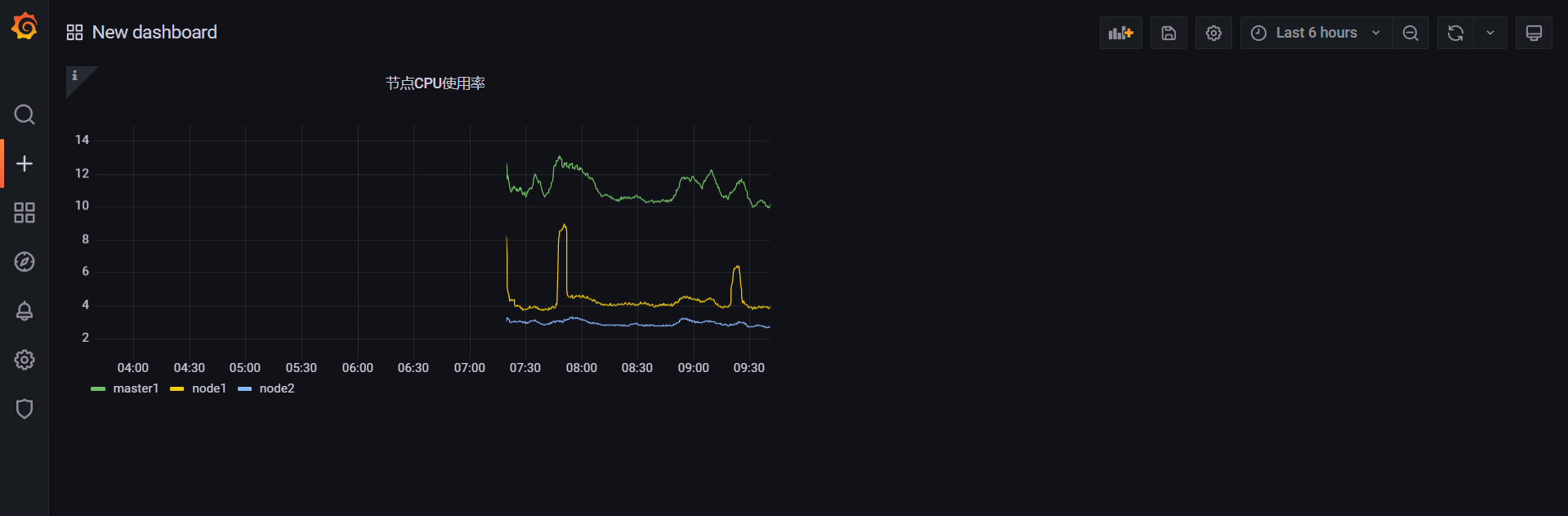
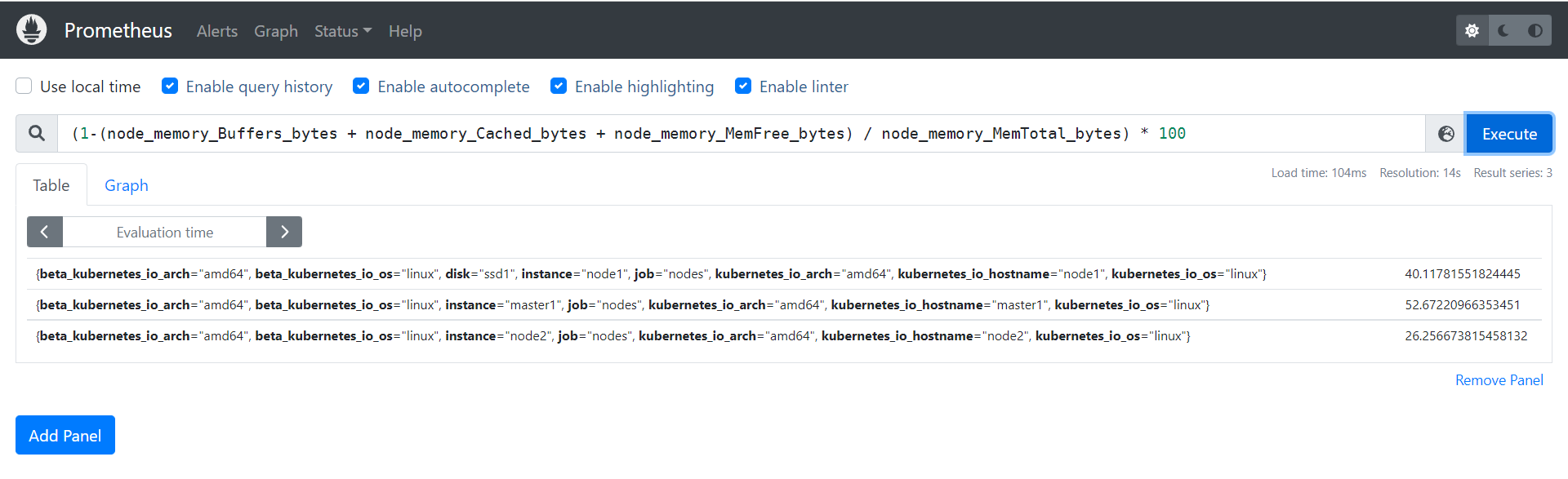
🍀 测试:创建节点内存使用率面板
(1-(node_memory_Buffers_bytes + node_memory_Cached_bytes + node_memory_MemFree_bytes) / node_memory_MemTotal_bytes) * 100
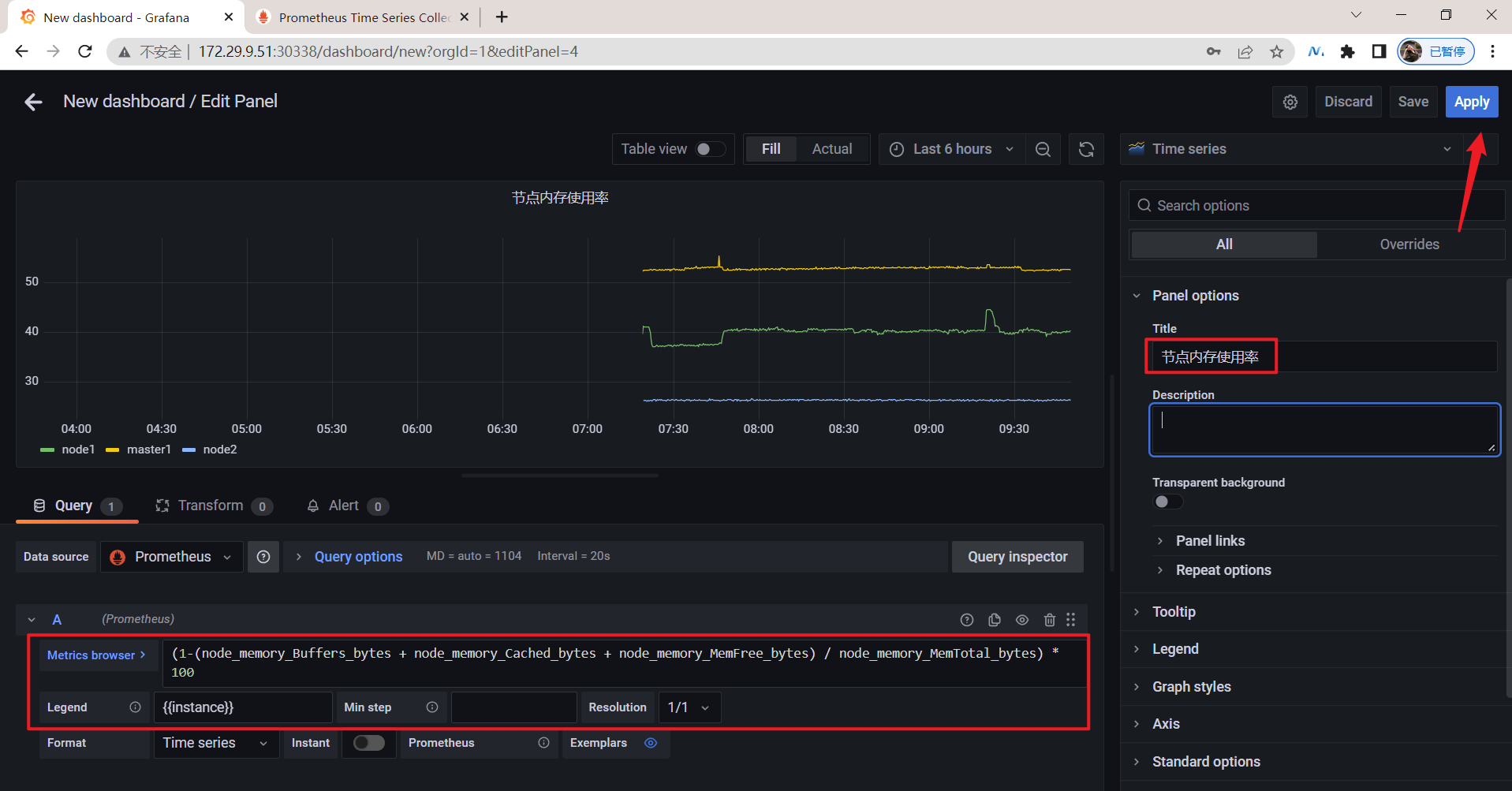
🍀 进一步定制
点击Dashboard settings:
填写Dashboard Name:
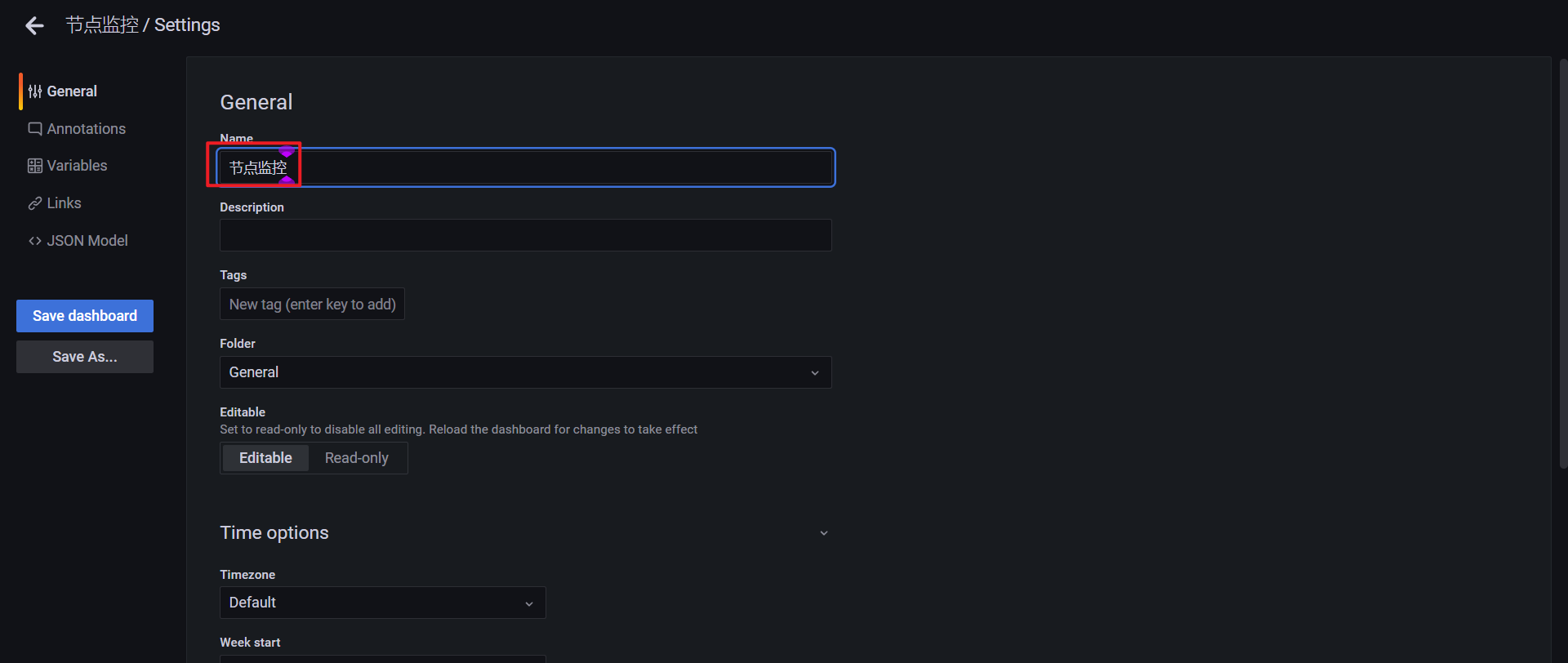
注意:这里的变量也是很重要的,我们来添加一个变量!
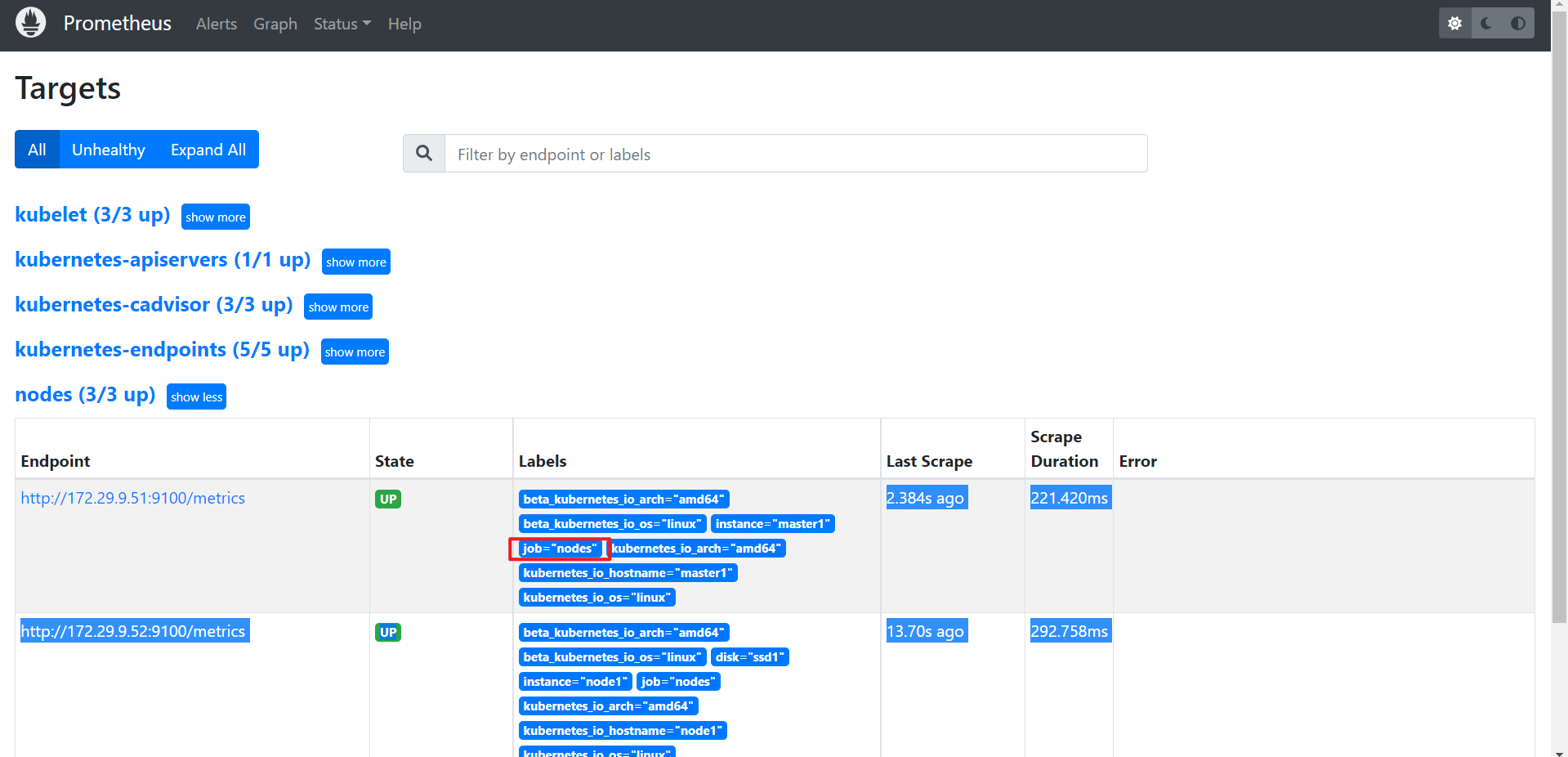
up{job="nodes",instance=~".*?"}
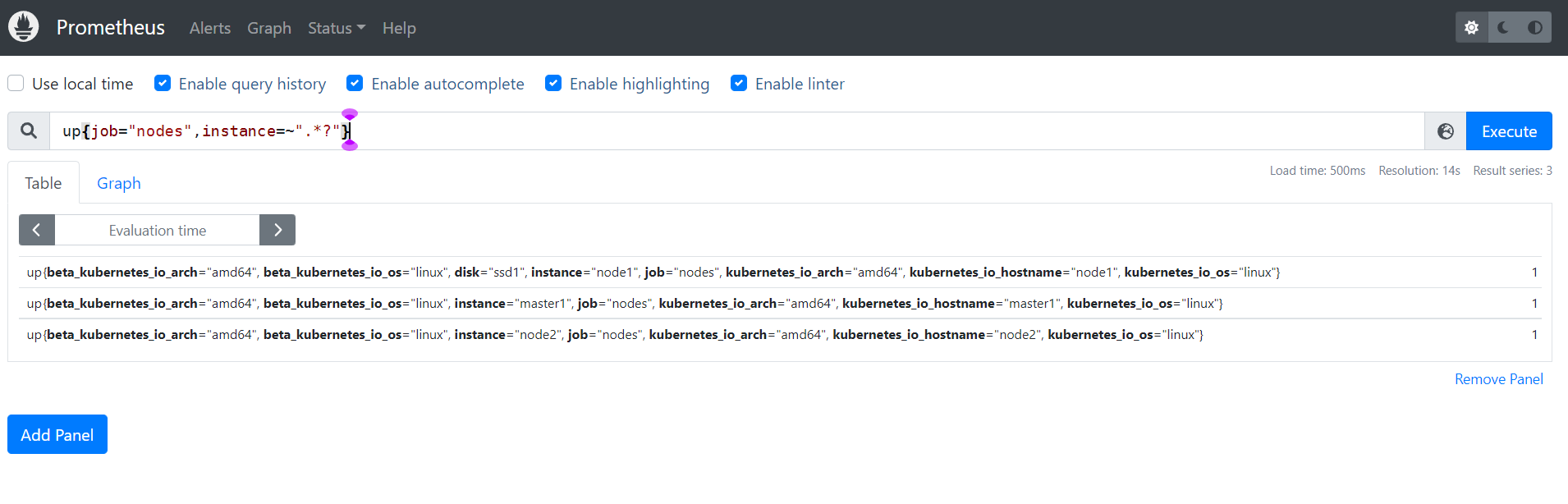
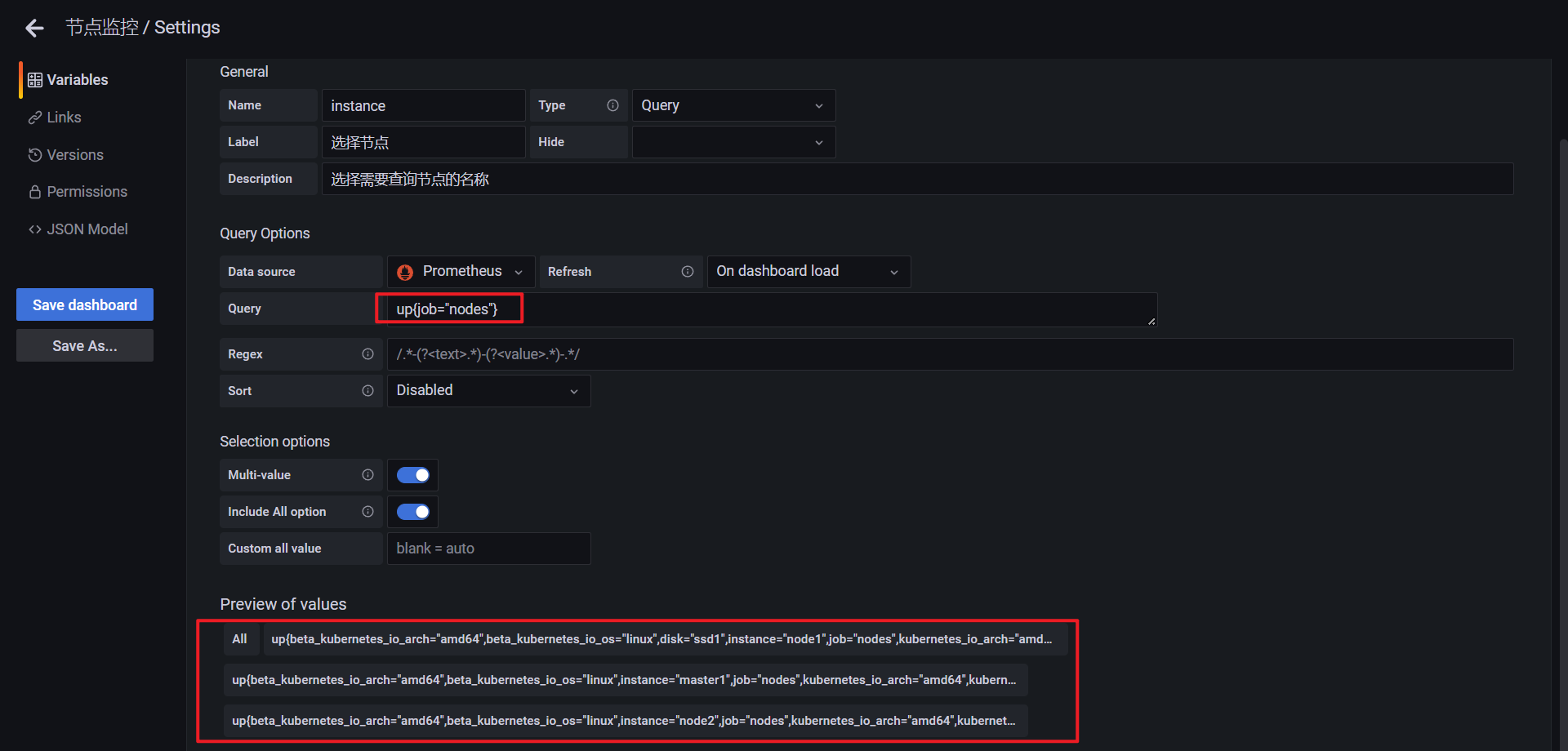
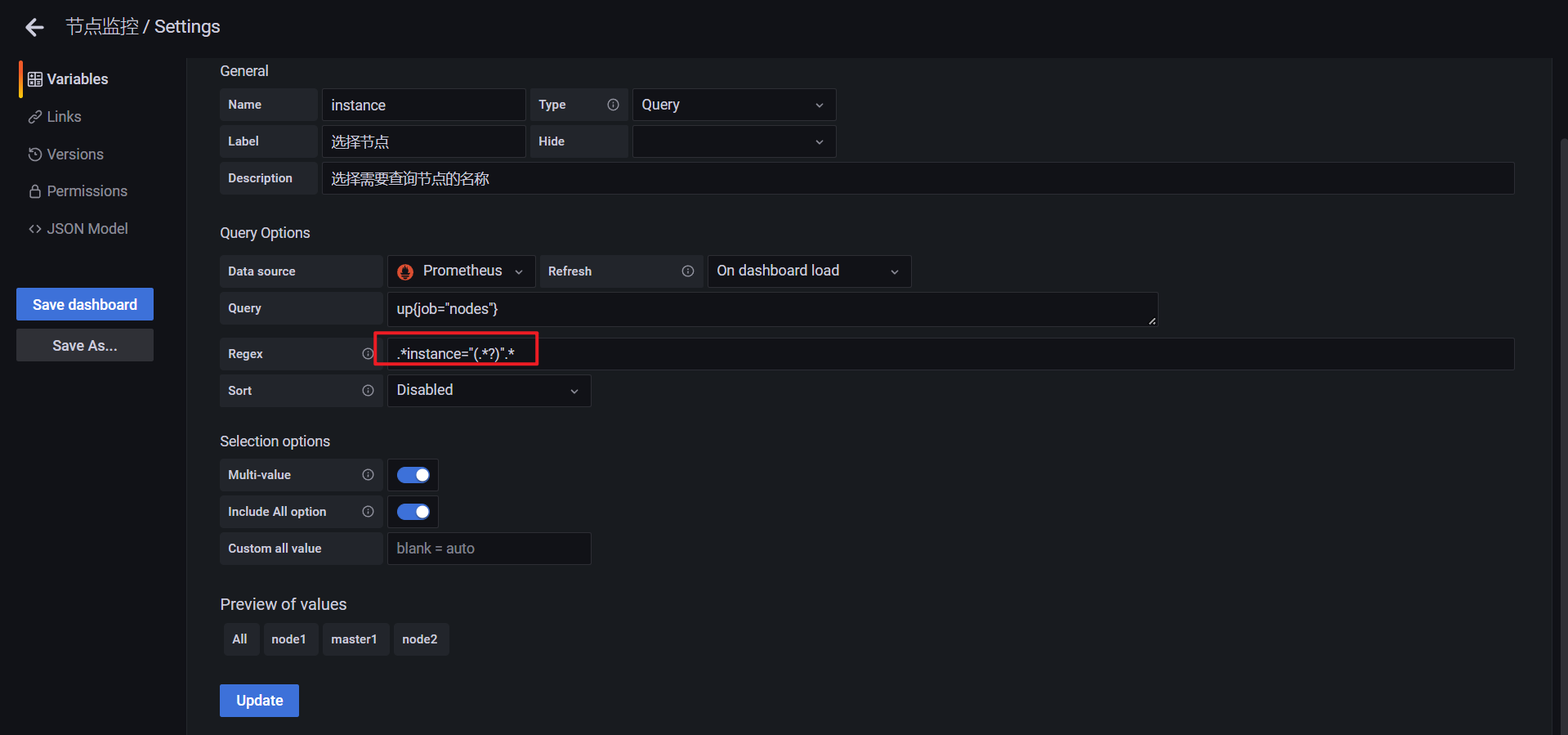
或者使用label函数:
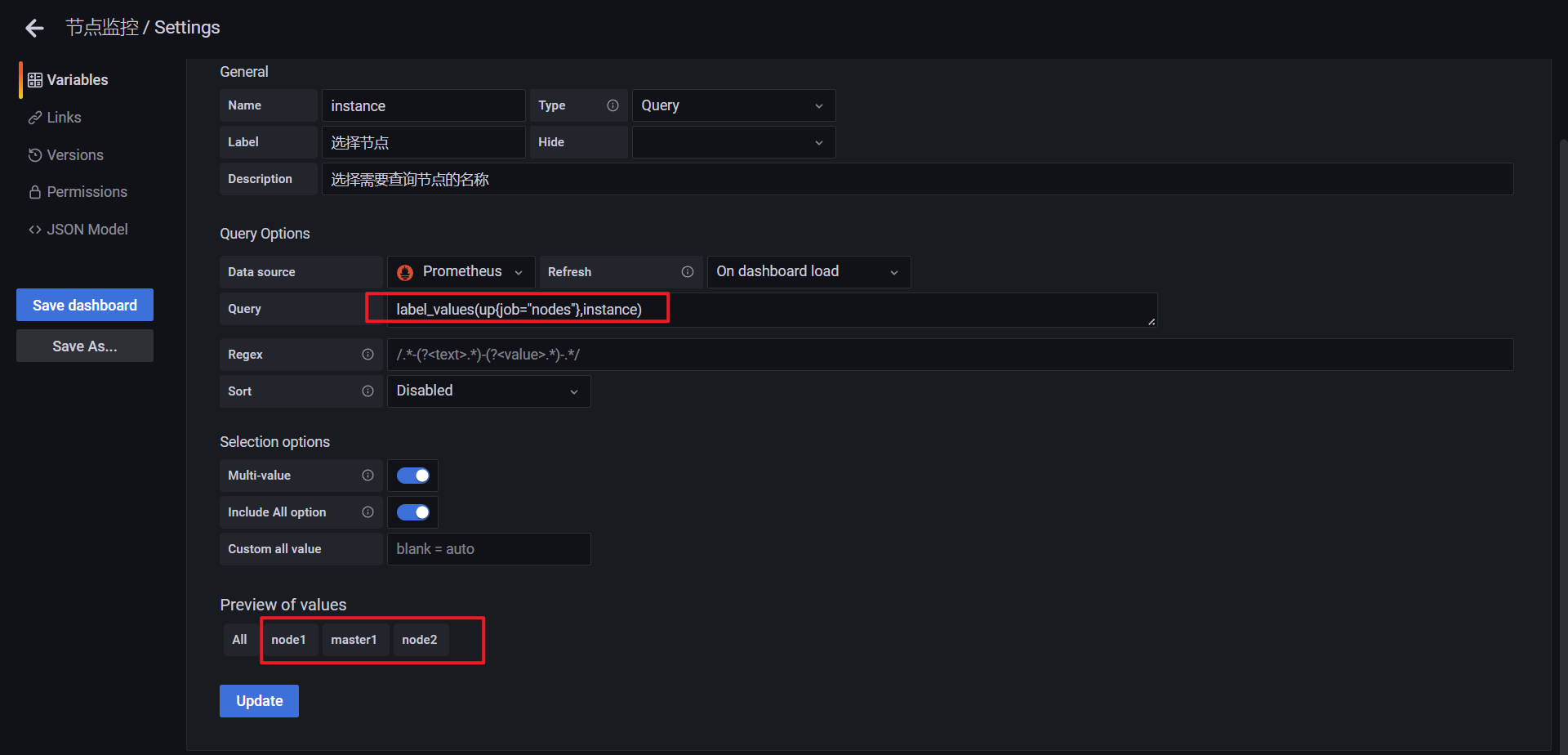
以上配置后,还需要在pannel里进行配置才行:
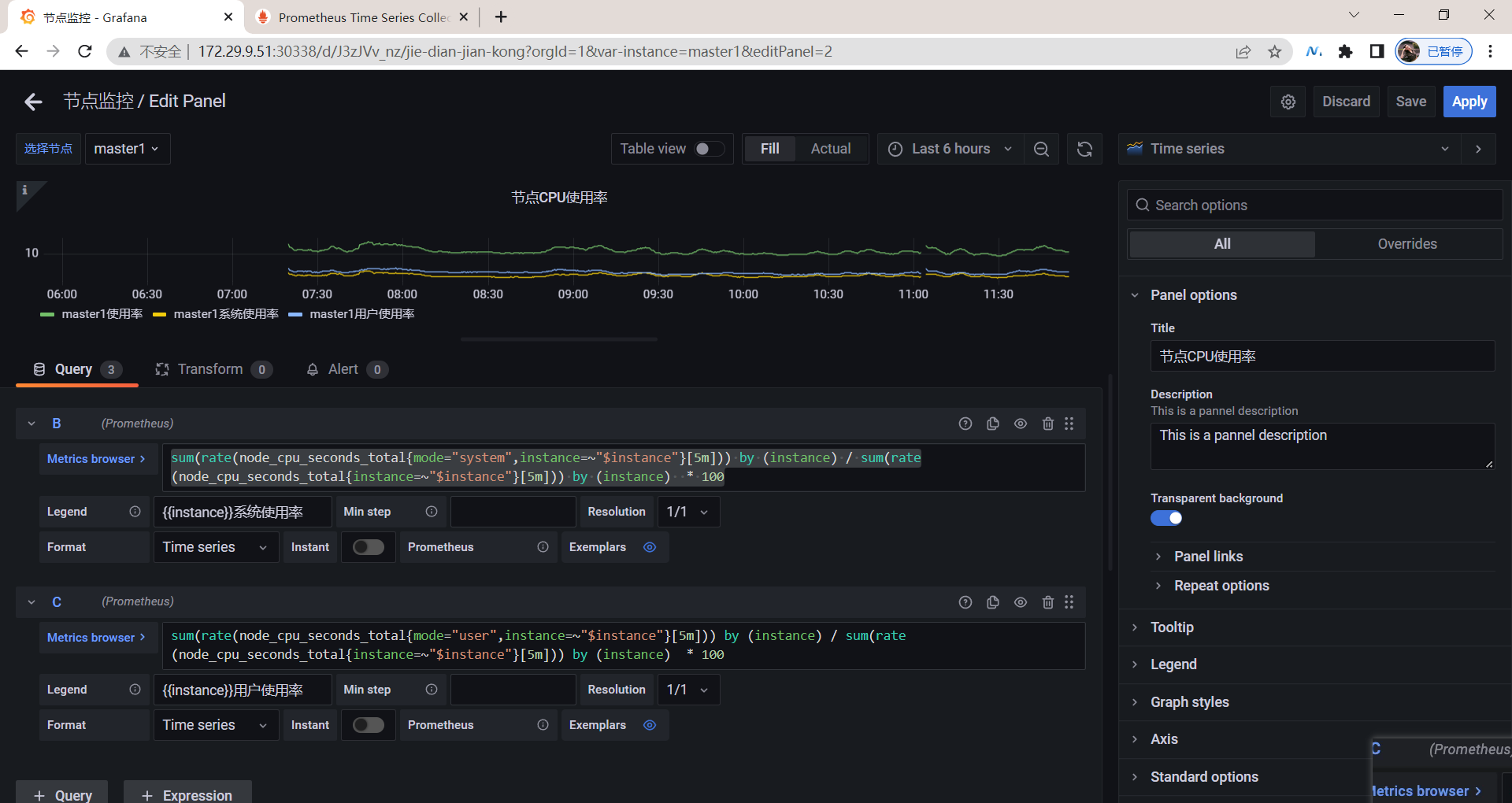
(1-sum(rate(node_cpu_seconds_total{mode="idle",instance=~"$instance"}[5m])) by (instance) / sum(rate(node_cpu_seconds_total{instance=~"$instance"}[5m])) by (instance) ) * 100
(1-(node_memory_Buffers_bytes{instance=~"$instance"} + node_memory_Cached_bytes{instance=~"$instance"} + node_memory_MemFree_bytes{instance=~"$instance"}) / node_memory_MemTotal_bytes{instance=~"$instance"}) * 100

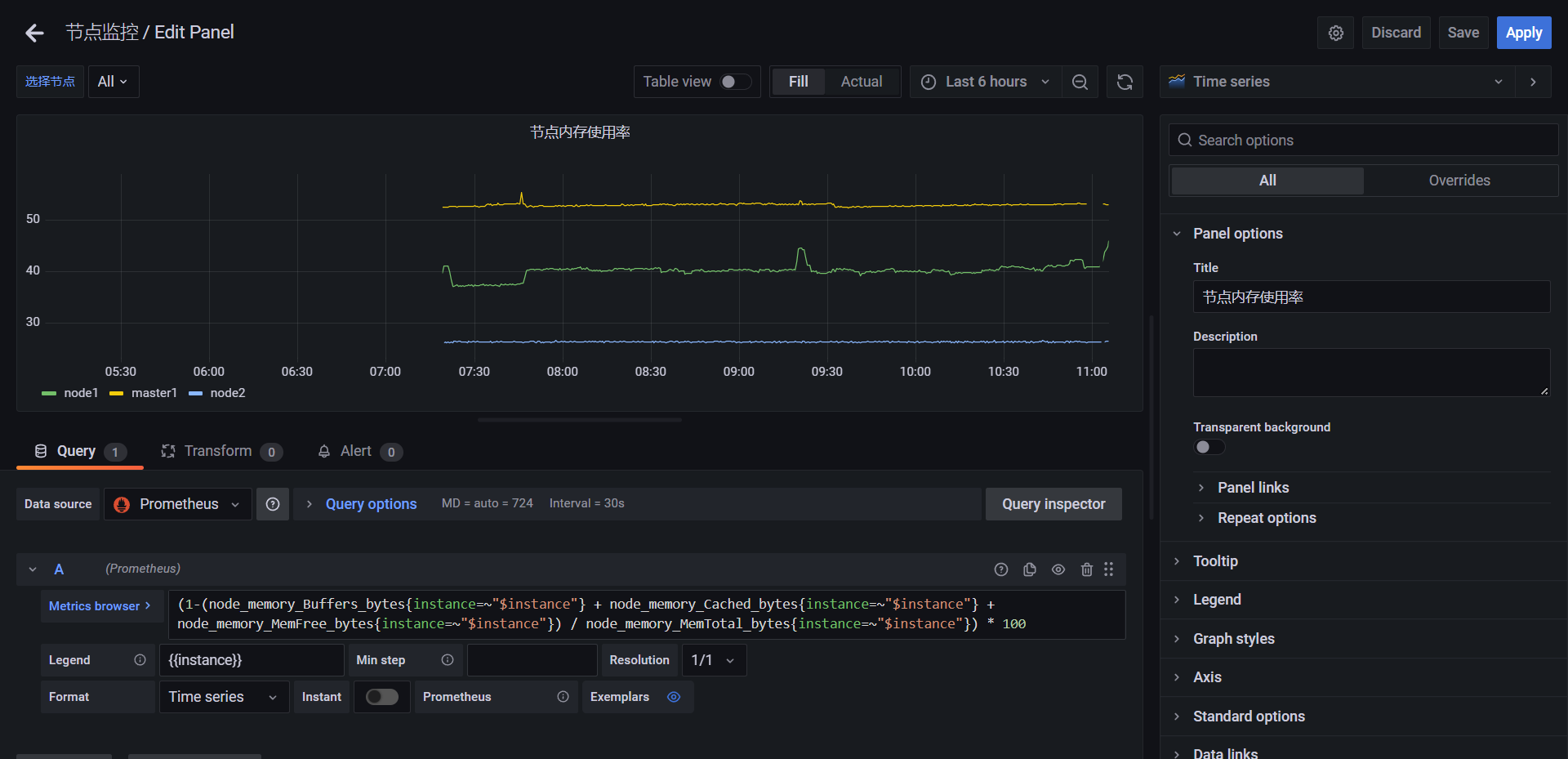
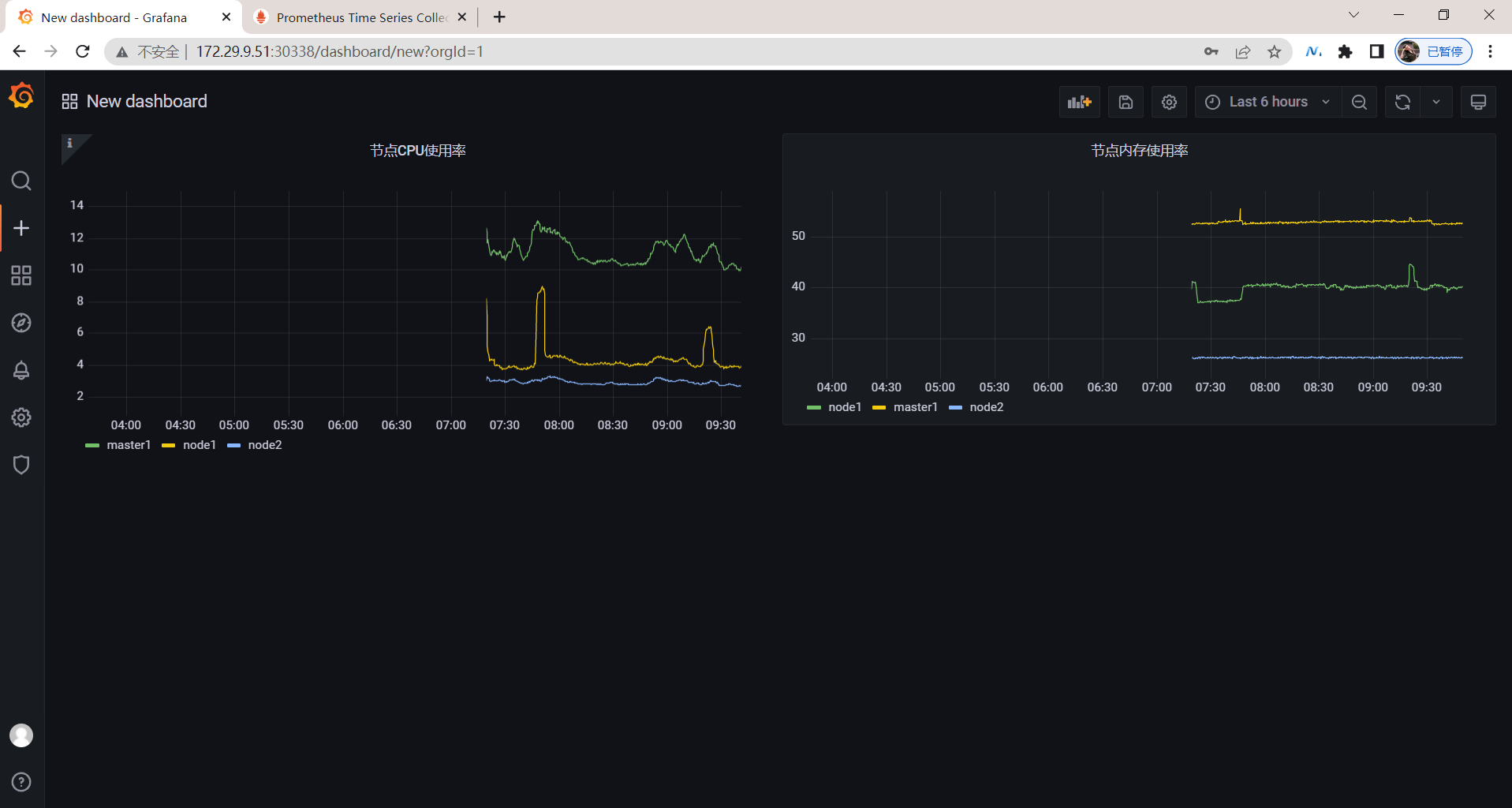
最终效果:😘
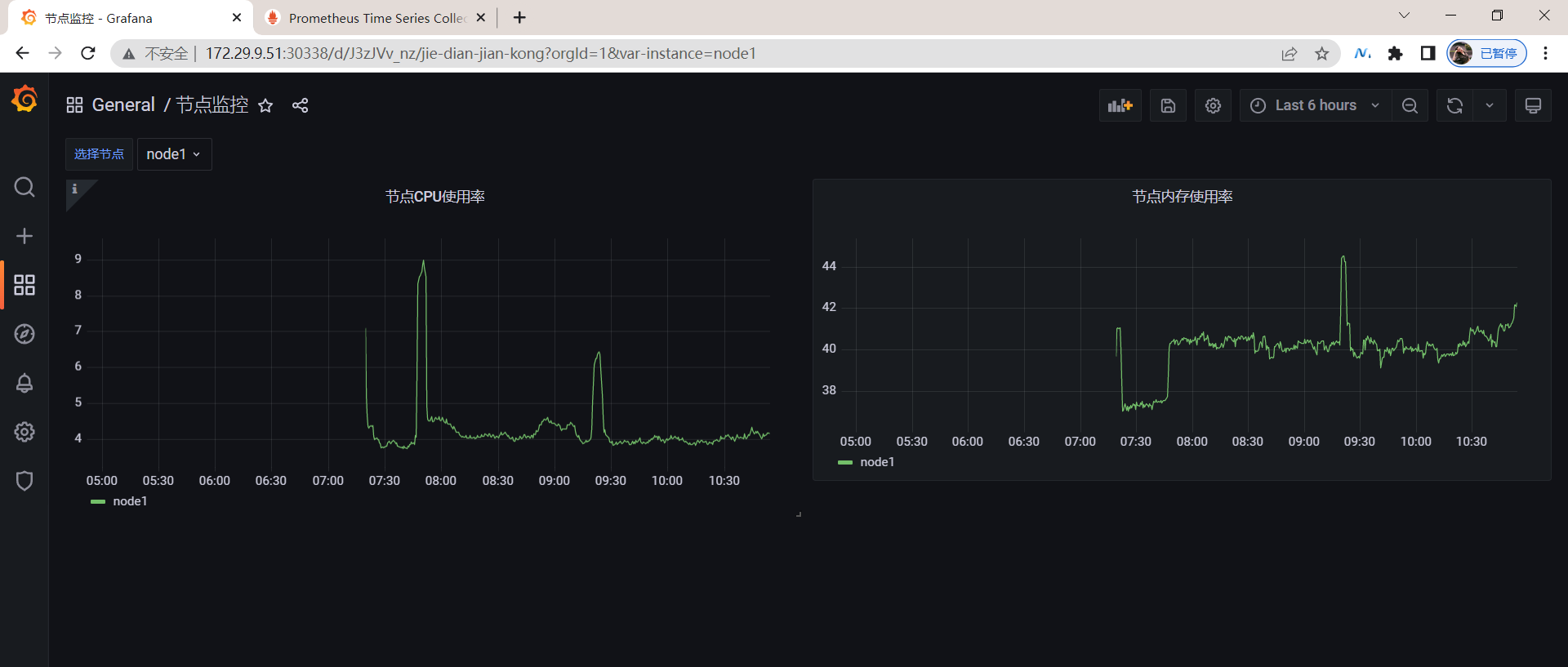

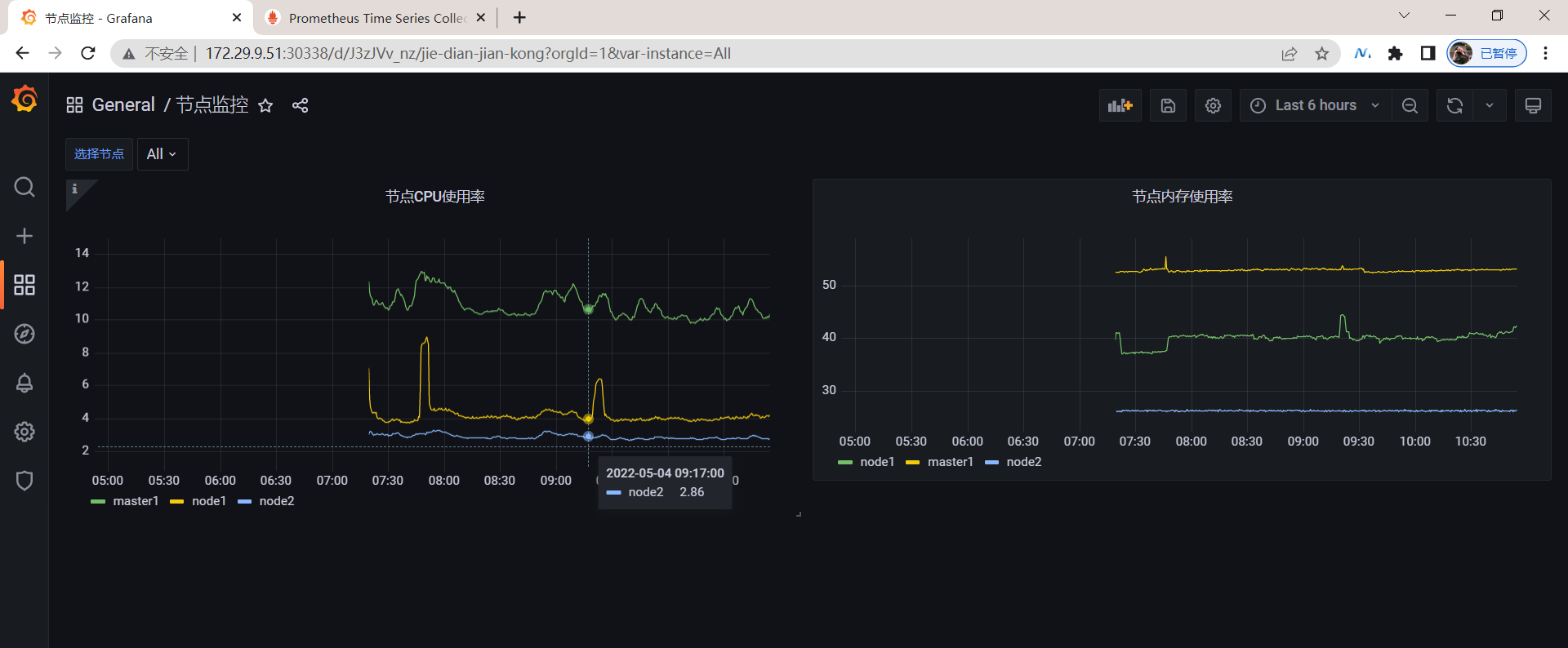
🍀 这边再加一个效果:
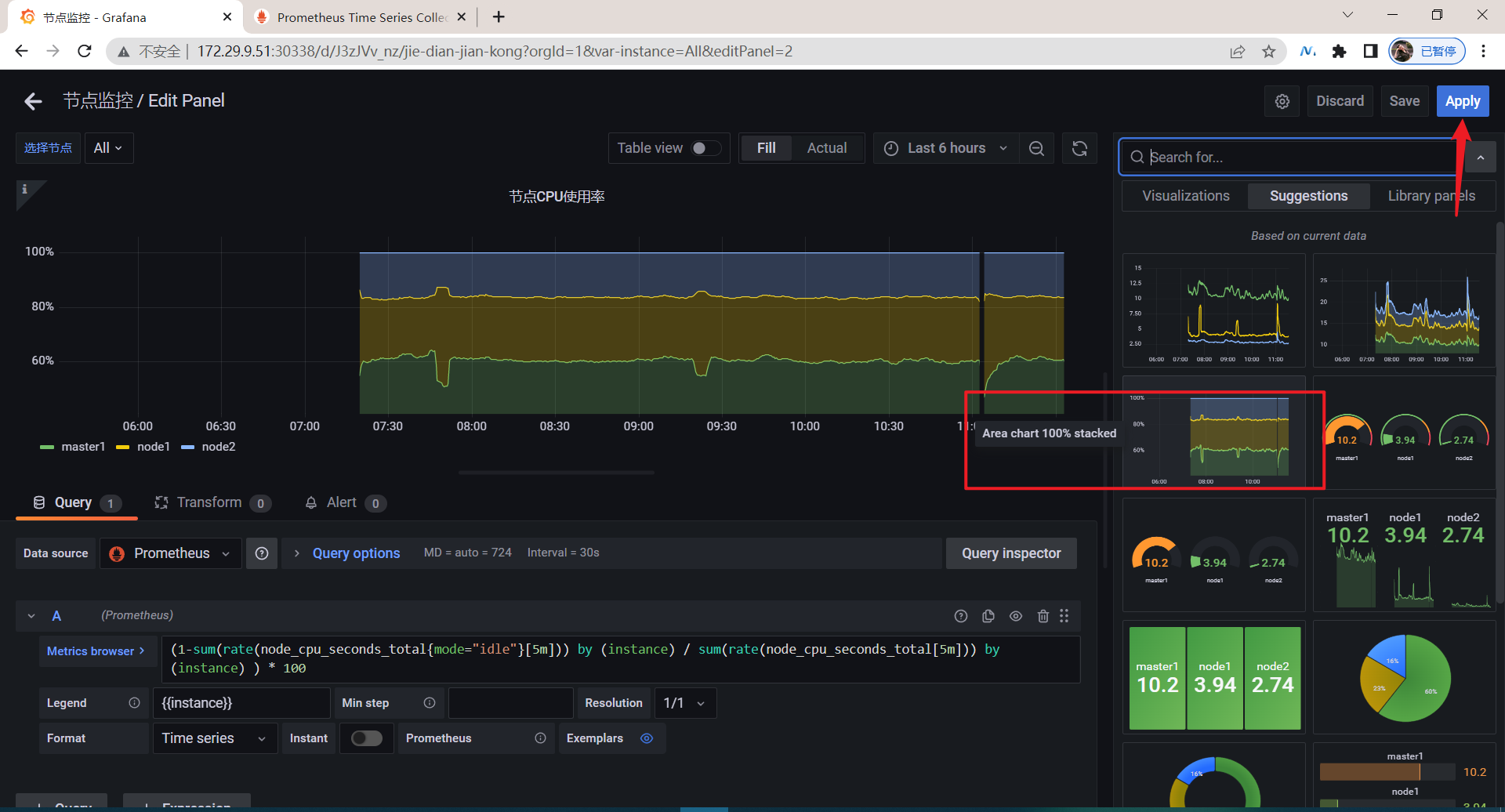
🍀 如何想在一个pannel里显示多个数据该怎么办呢?
sum(rate(node_cpu_seconds_total{mode="system",instance=~"$instance"}[5m])) by (instance) / sum(rate(node_cpu_seconds_total{instance=~"$instance"}[5m])) by (instance) * 100
sum(rate(node_cpu_seconds_total{mode="user",instance=~"$instance"}[5m])) by (instance) / sum(rate(node_cpu_seconds_total{instance=~"$instance"}[5m])) by (instance) * 100
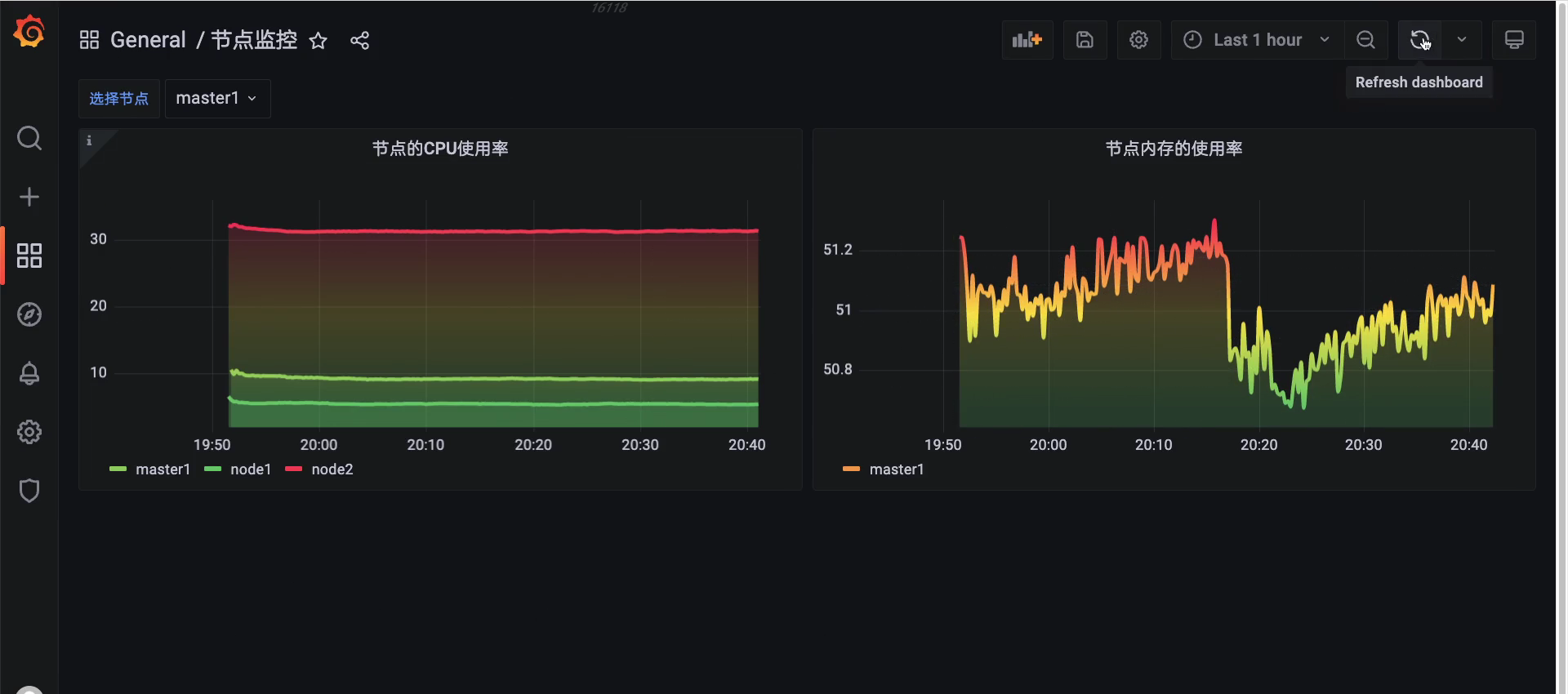
但是,所有节点都展示出来的话,看起来就不友好了:
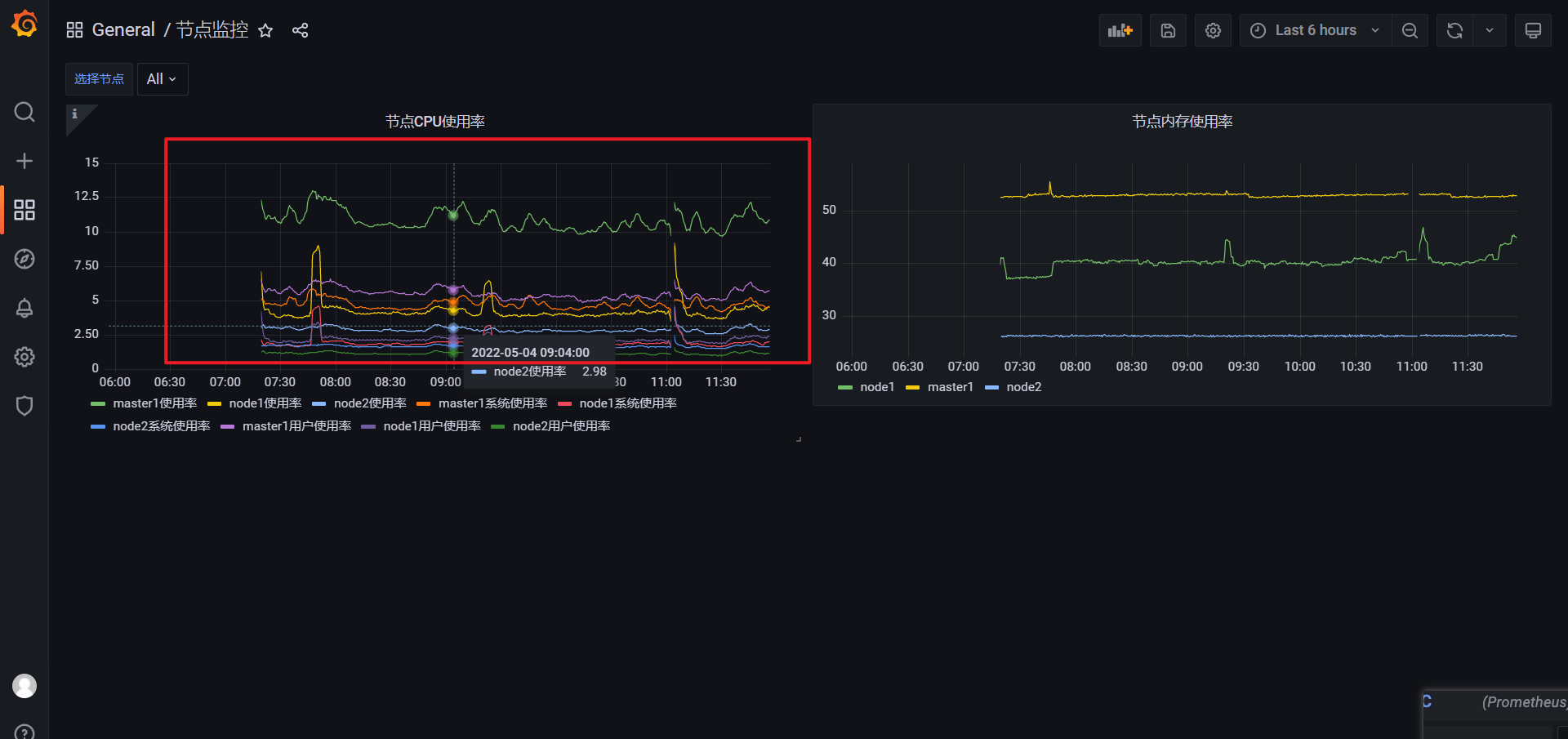
更新:
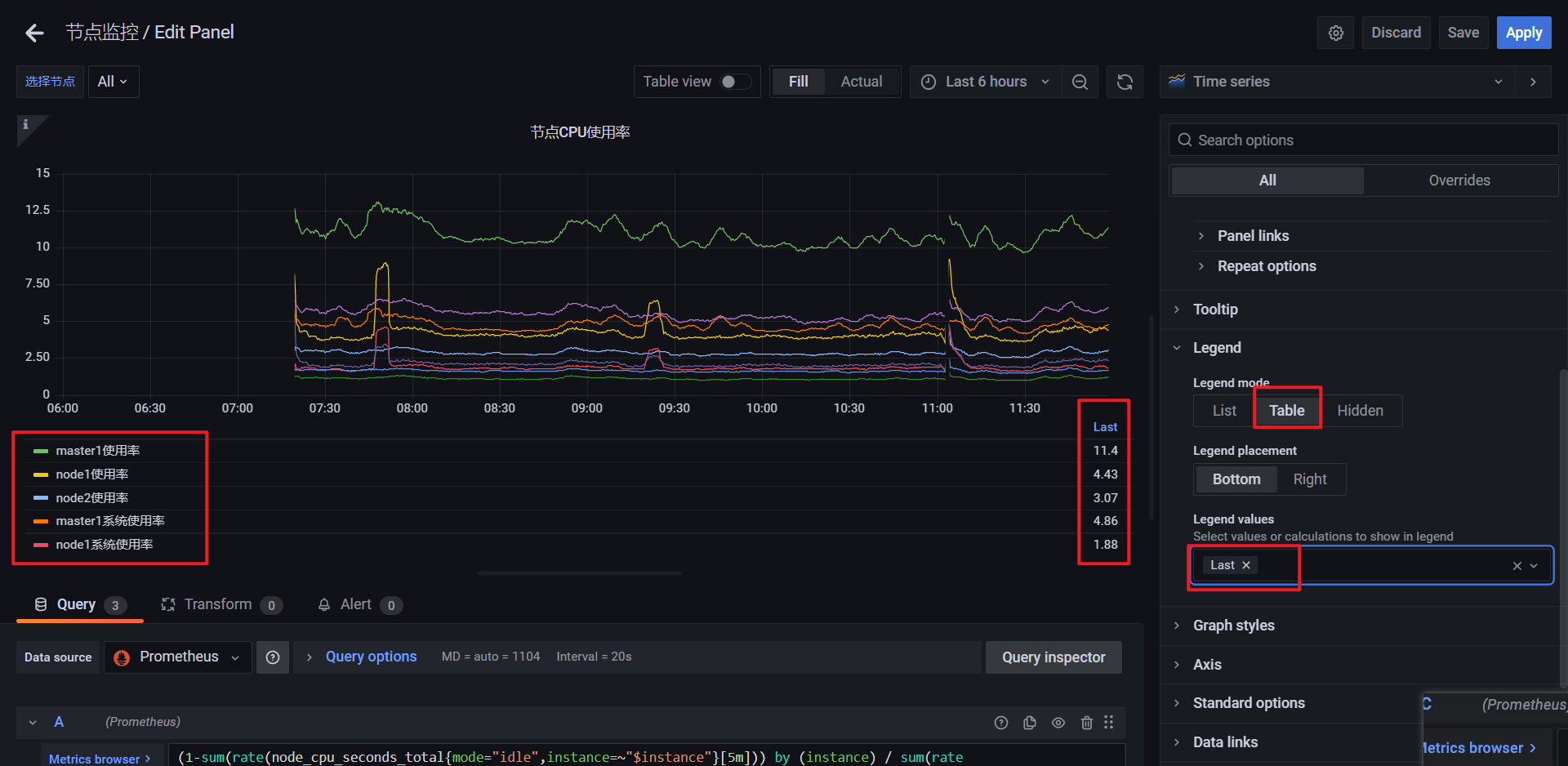
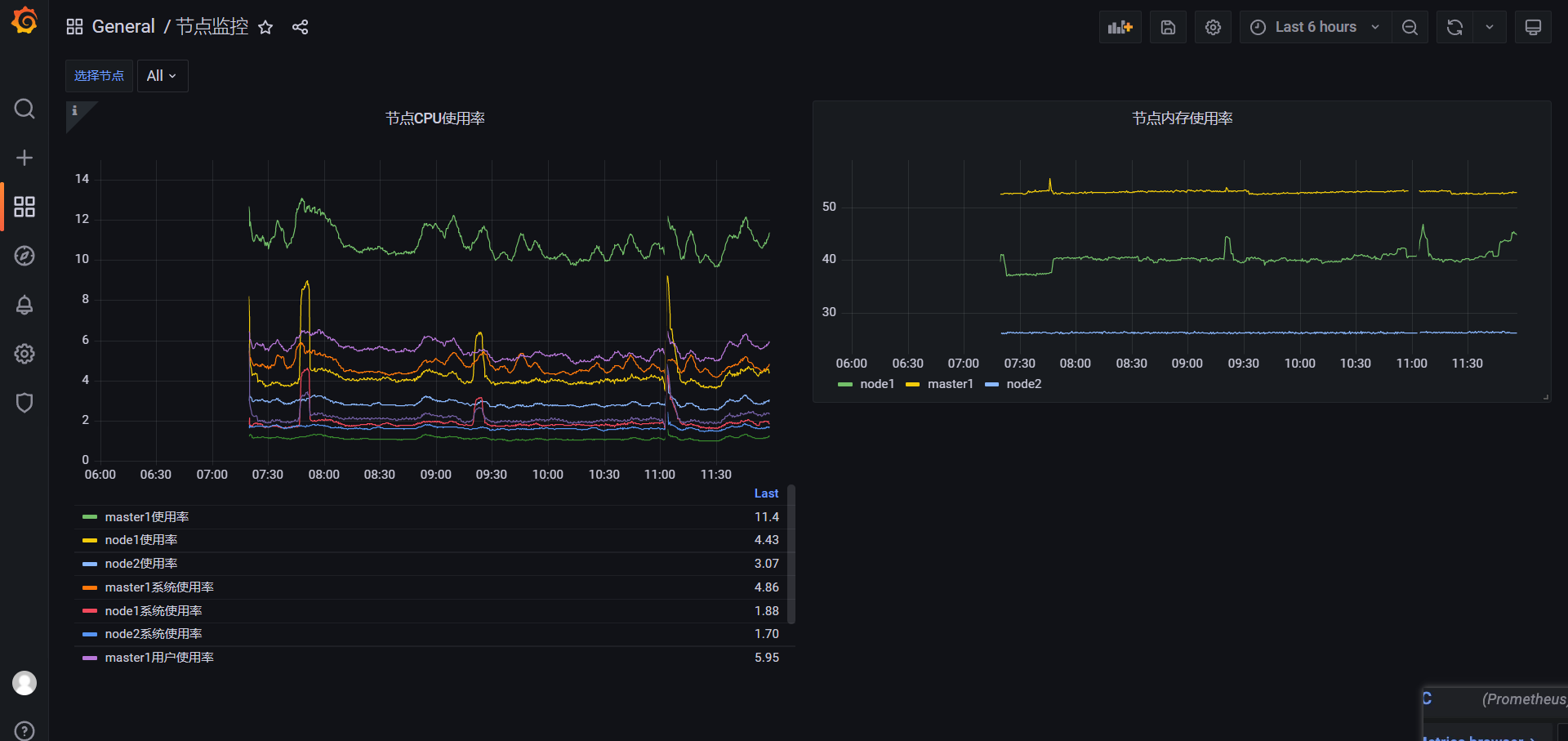
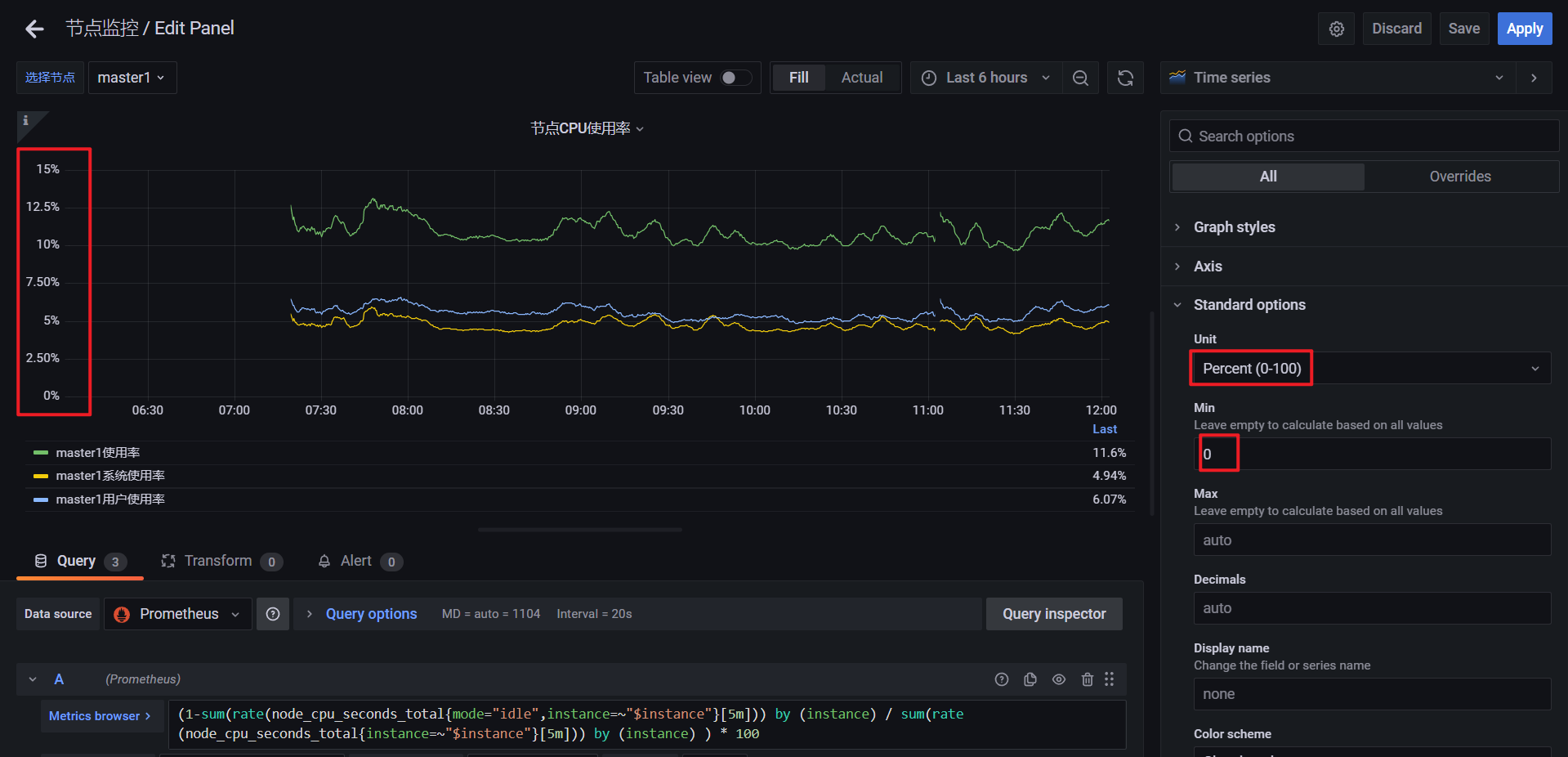
🍀 增加百分比:
4、Grafana模板
1628 监控k8s node节点模板
- 模板链接
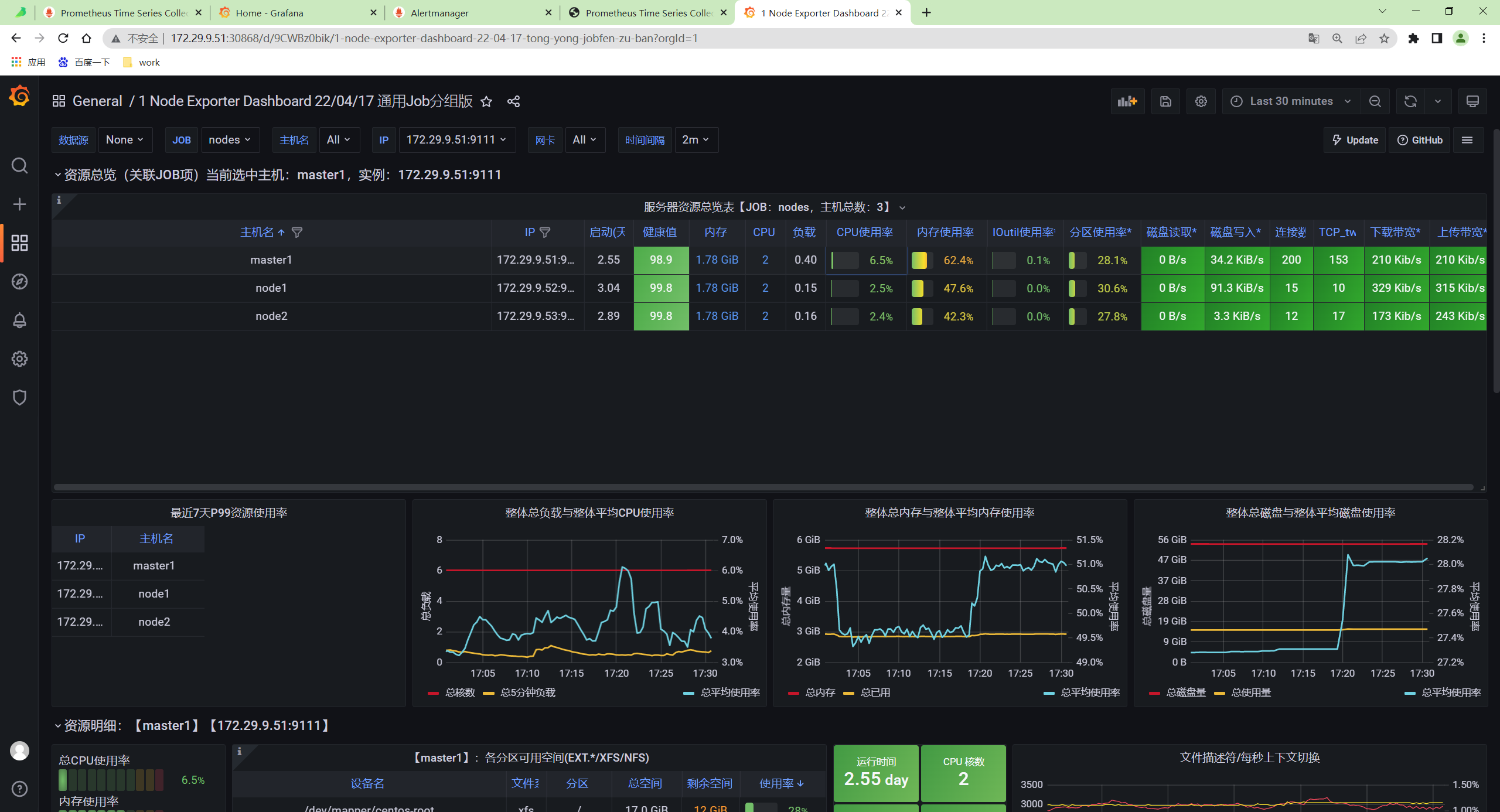
然后导入 16098 这个 Dashboard,导入后效果如下图所示。
- 效果如下
- 模板位置
1-node-exporter-for-prometheus-dashboard-cn-0417-job_rev2.json
FAQ
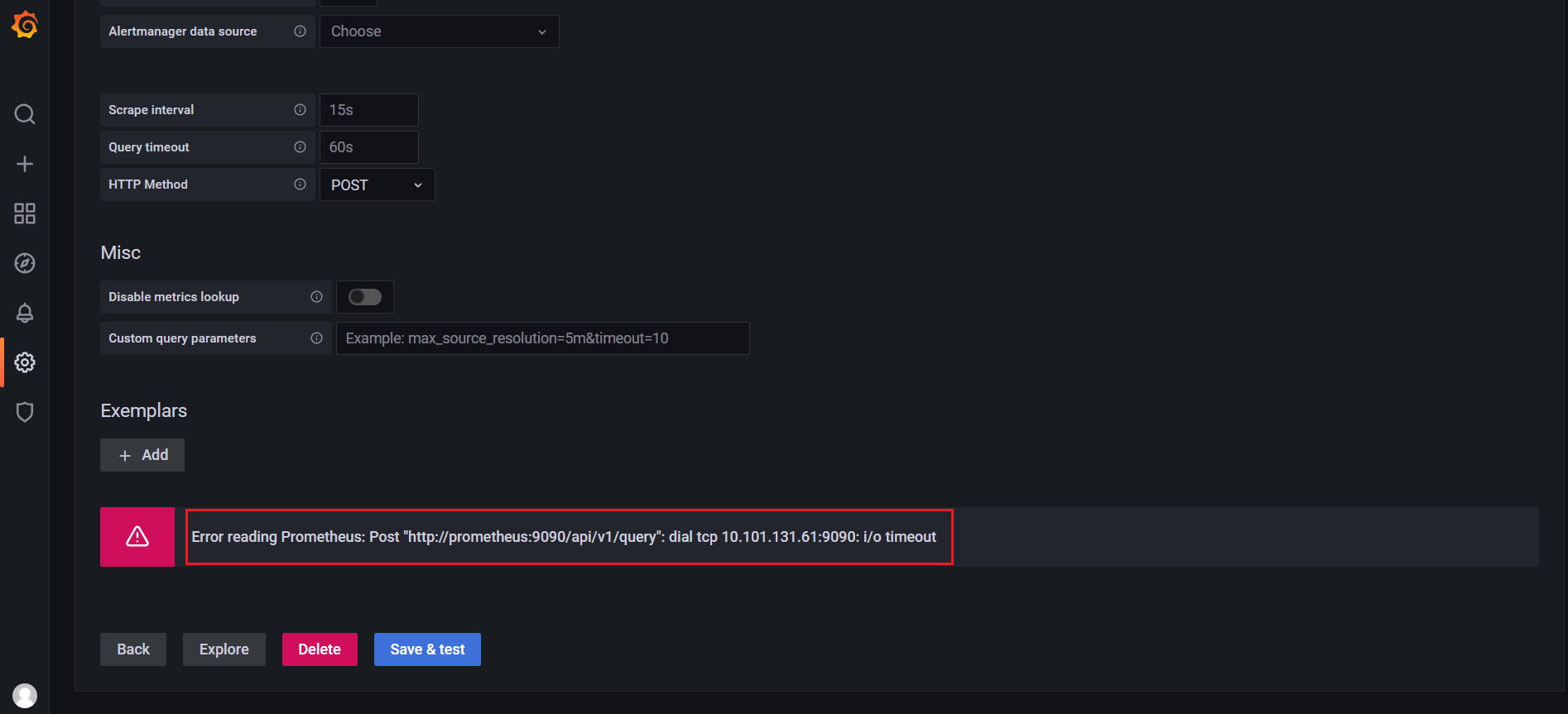
问题:prometheus svc作为数据源发生报错?
🍀 注意:我这里为什么Testing错误了呢?
🍀 奇怪:这里换成Browser就可以了:……😥;
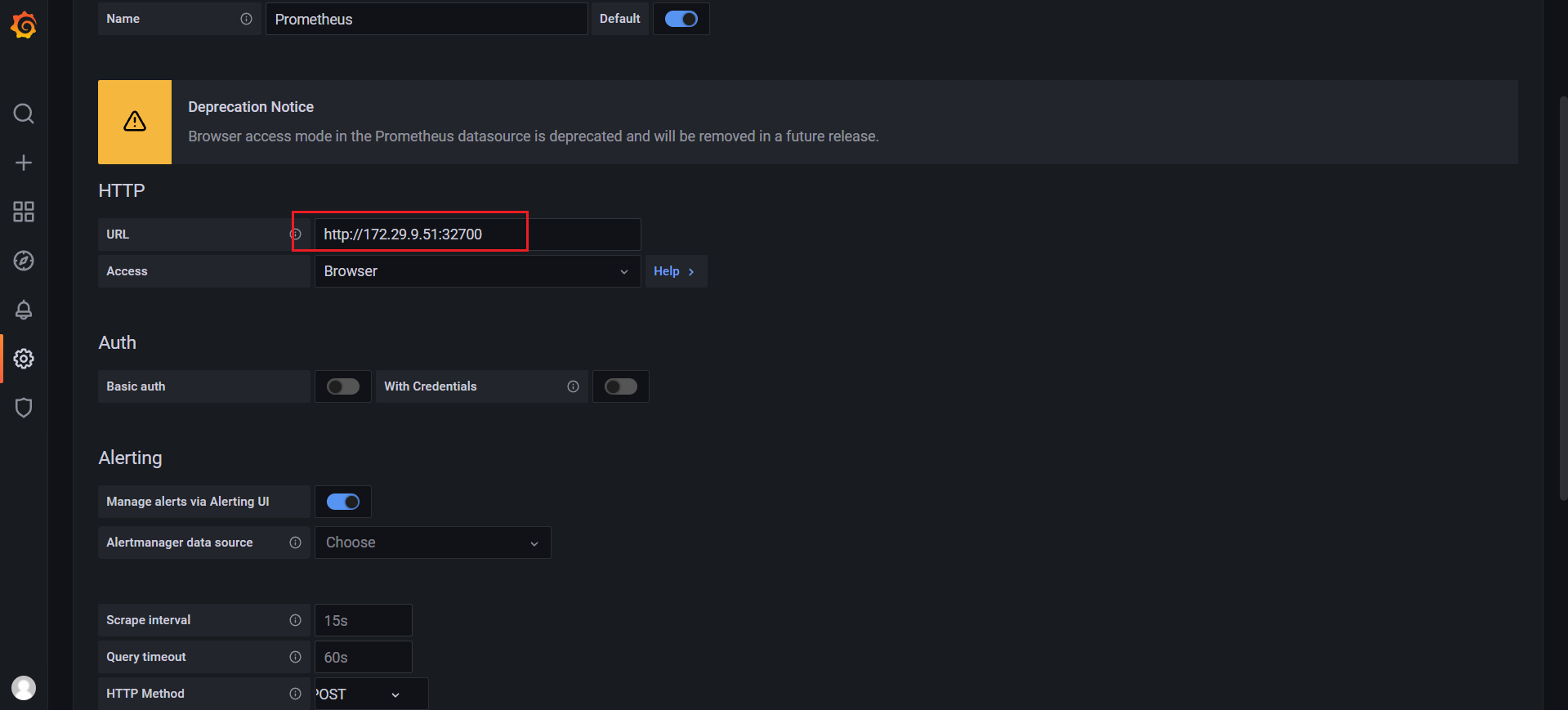
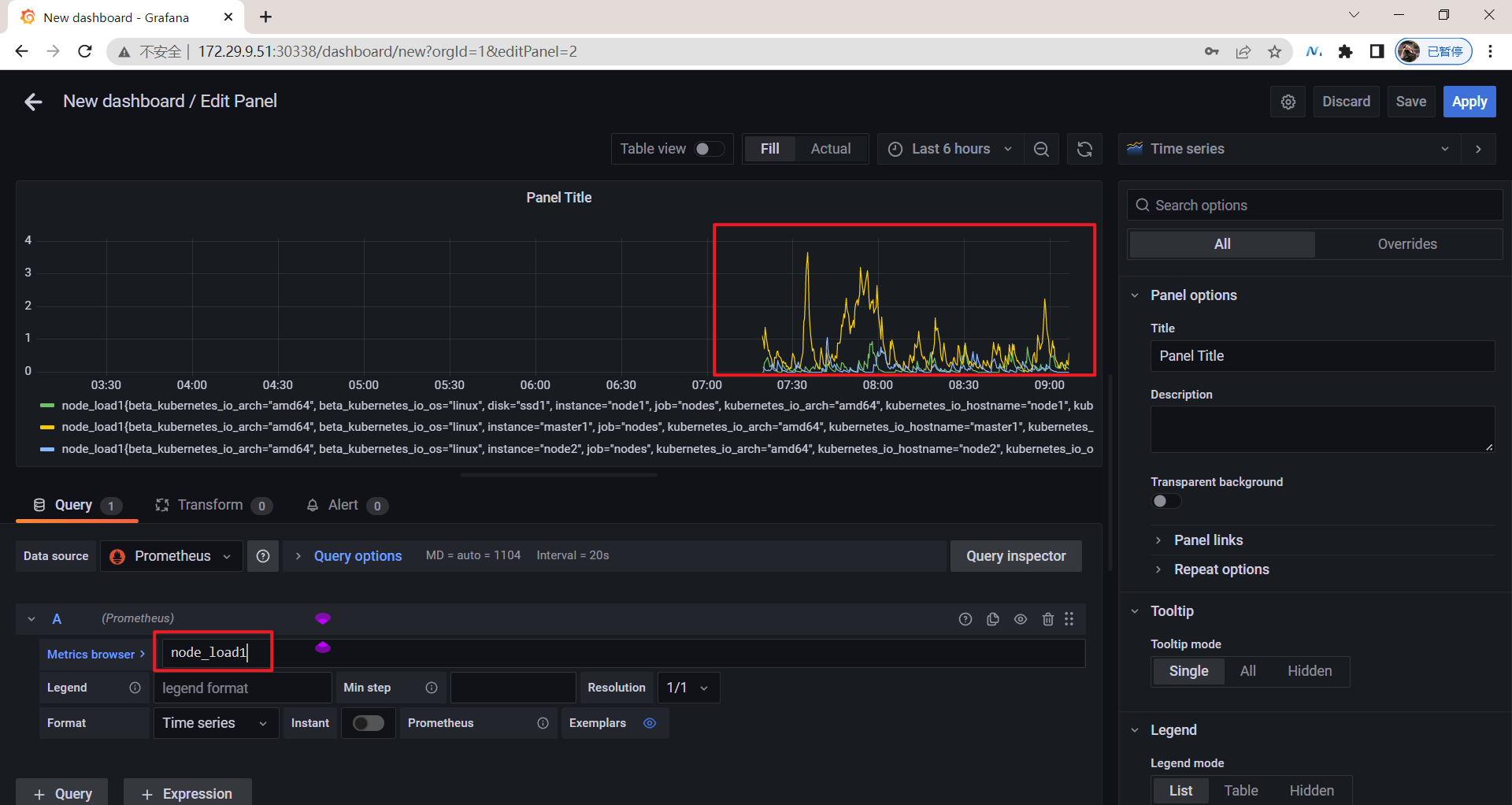
🍀 或者这里使用prometheus pod ip也是可以的哈!
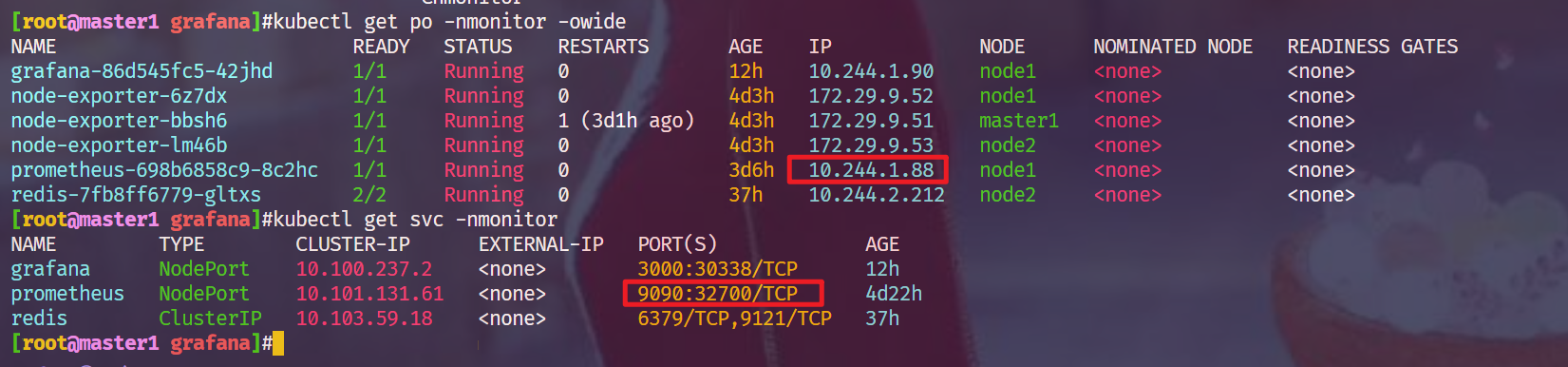
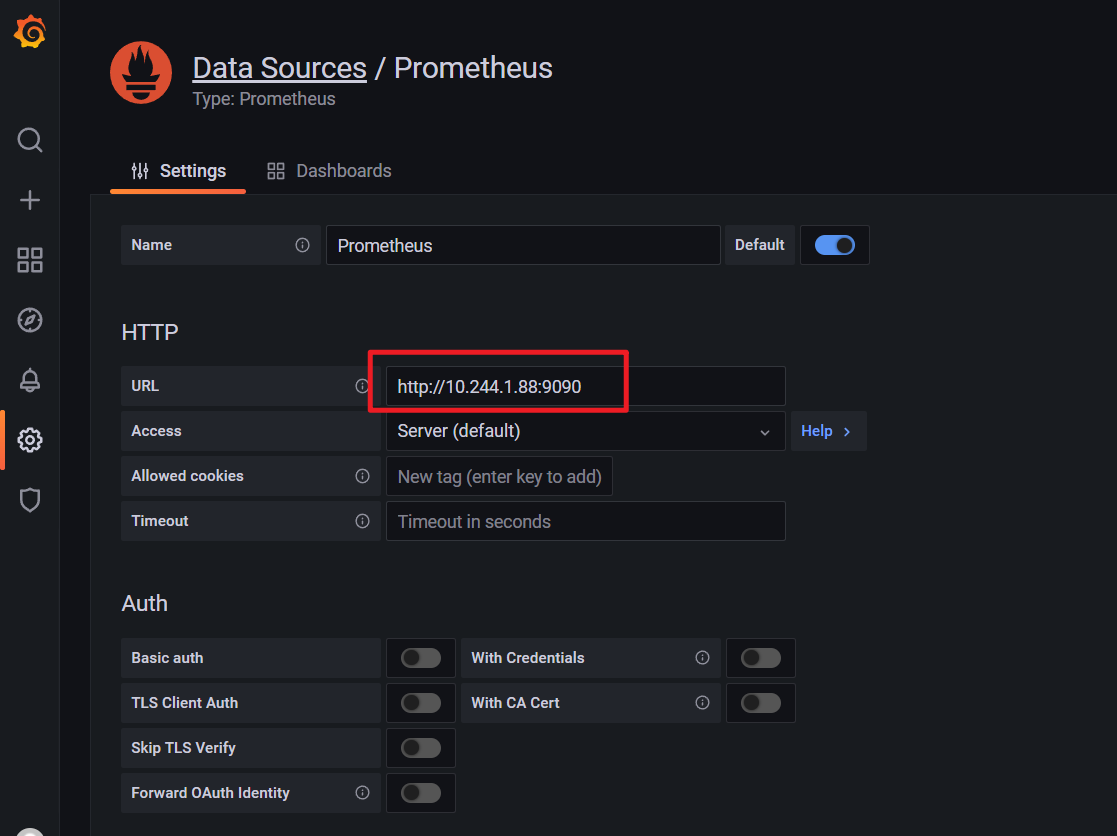
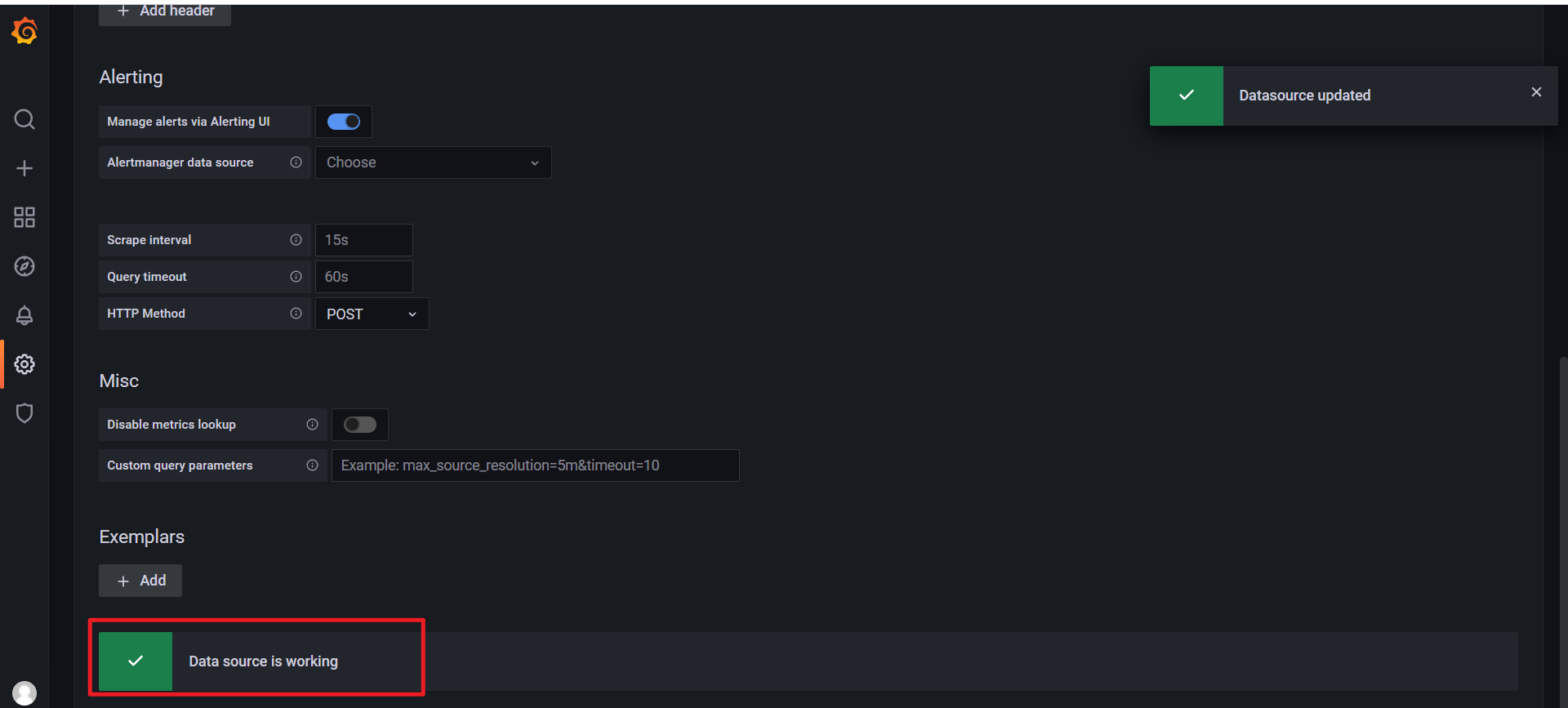
🍀 但是自己使用prometheus的svcName:9090端口就不行了,,😥
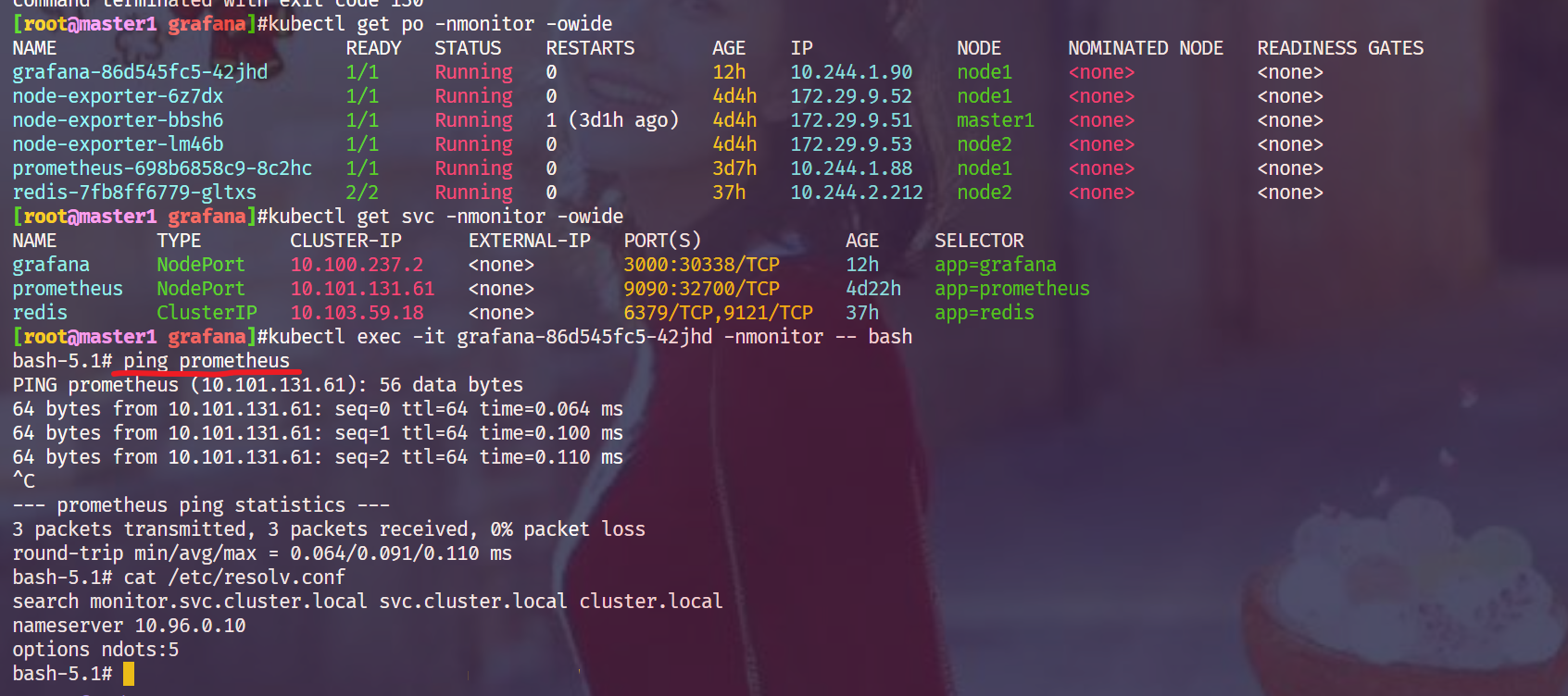
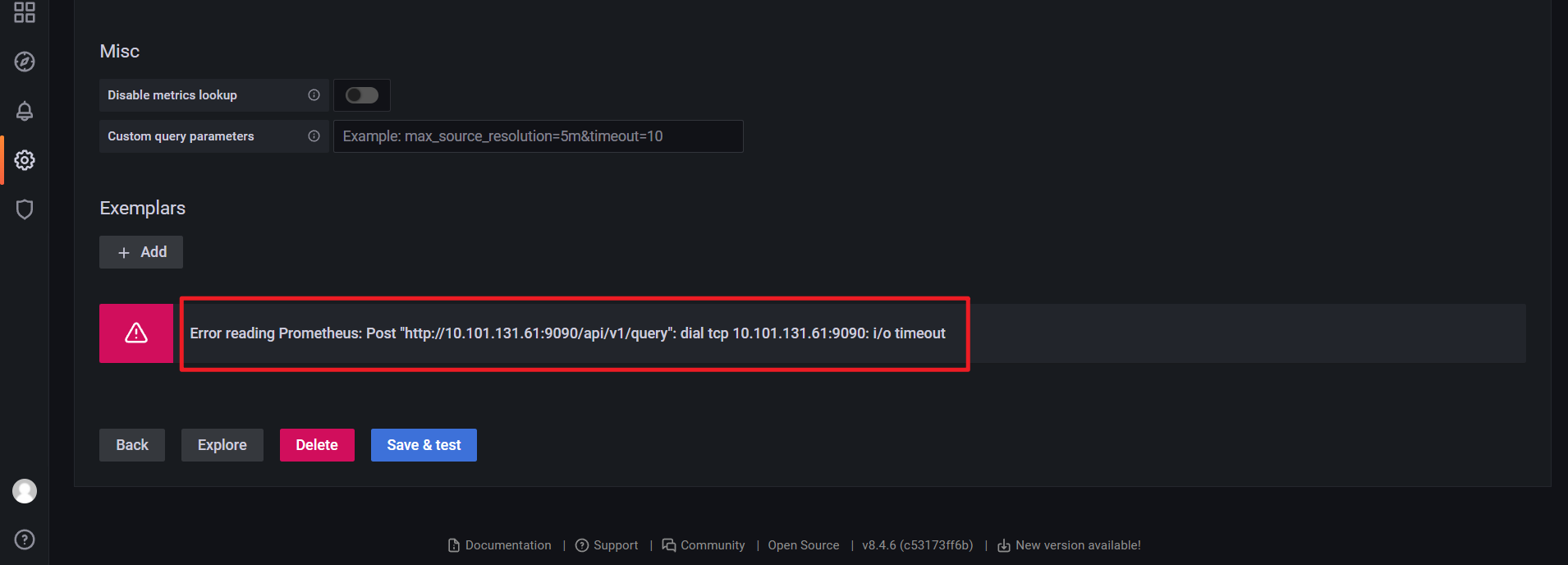
Error reading Prometheus: Post "http://prometheus:9090/api/v1/query": dial tcp 10.101.131.61:9090: i/o timeout
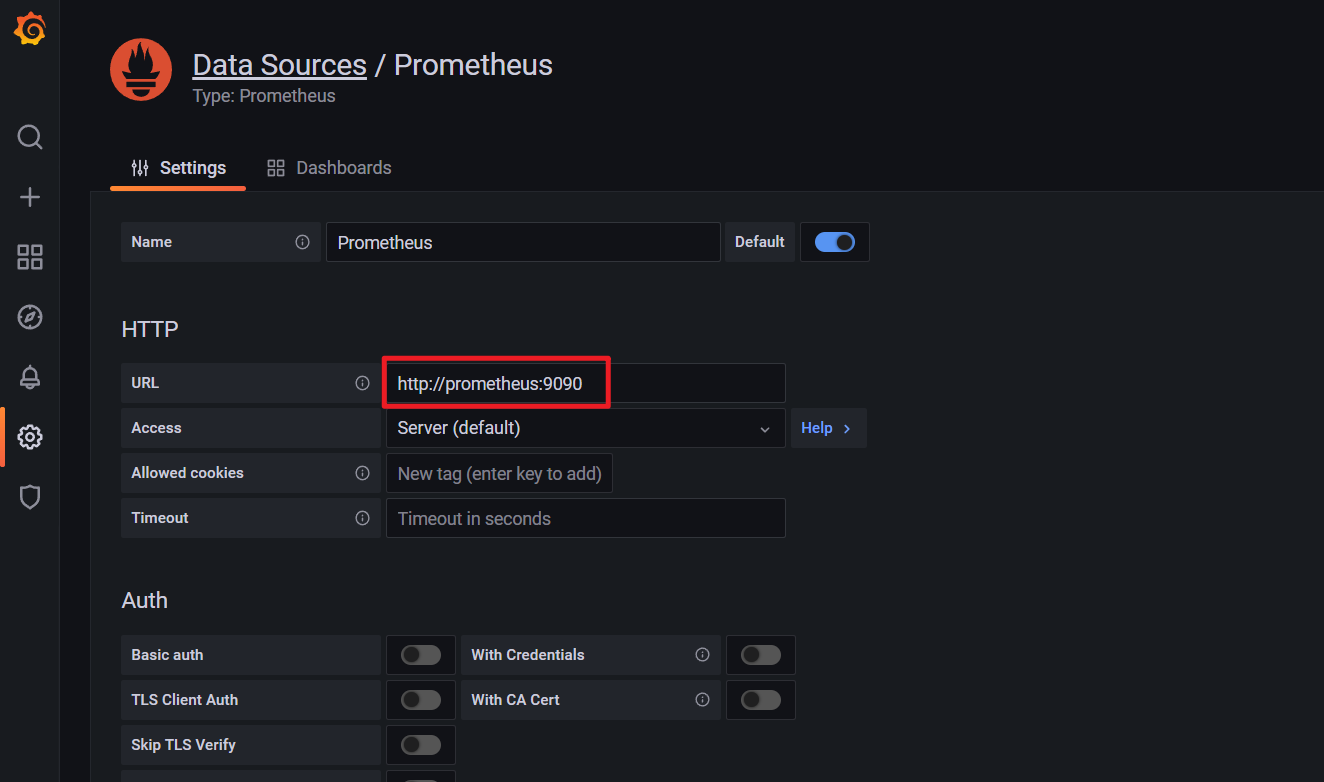
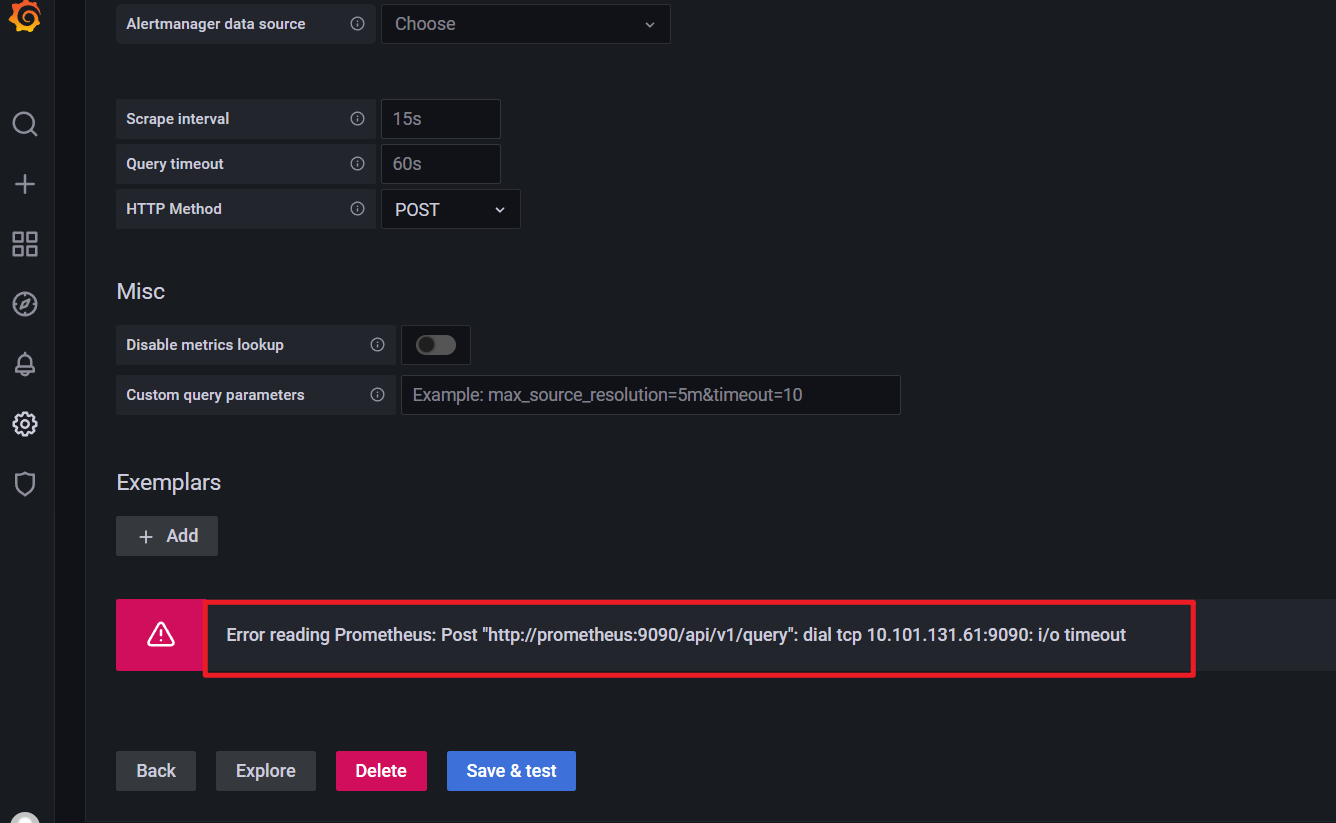
自己再次测试:
在grafana里不都是可以访问prometheus域名的吗,,,,,:
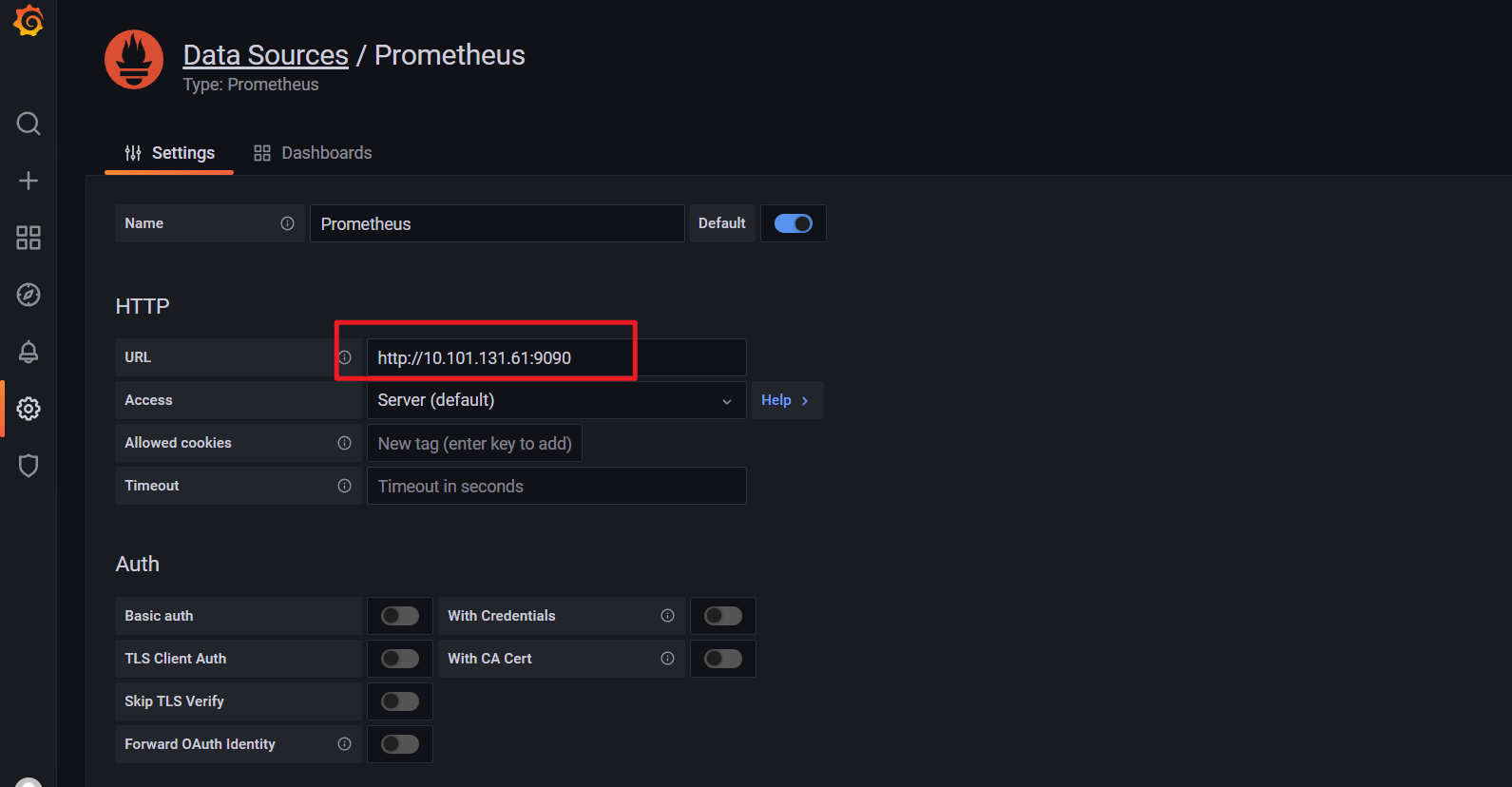
自己使用svc cluster ip也是有问题的:
ep信息:
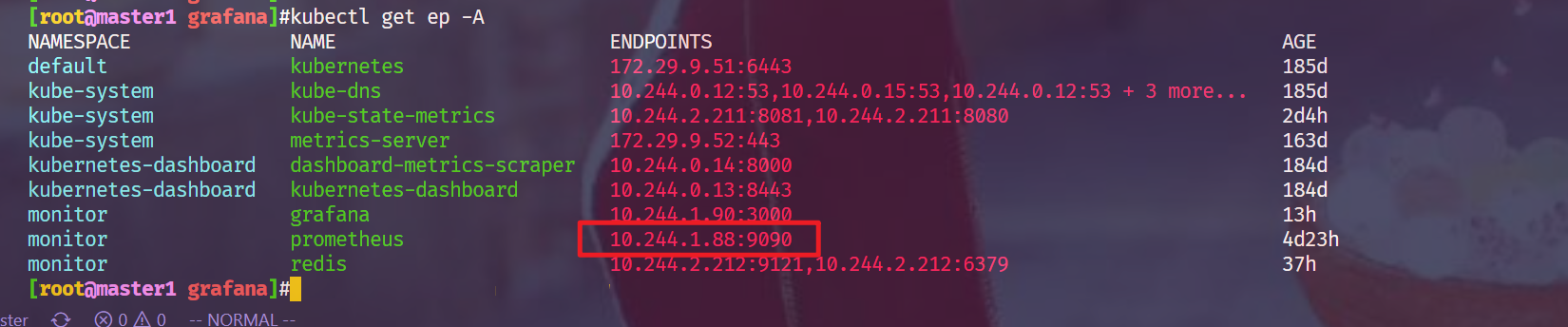
github链接:
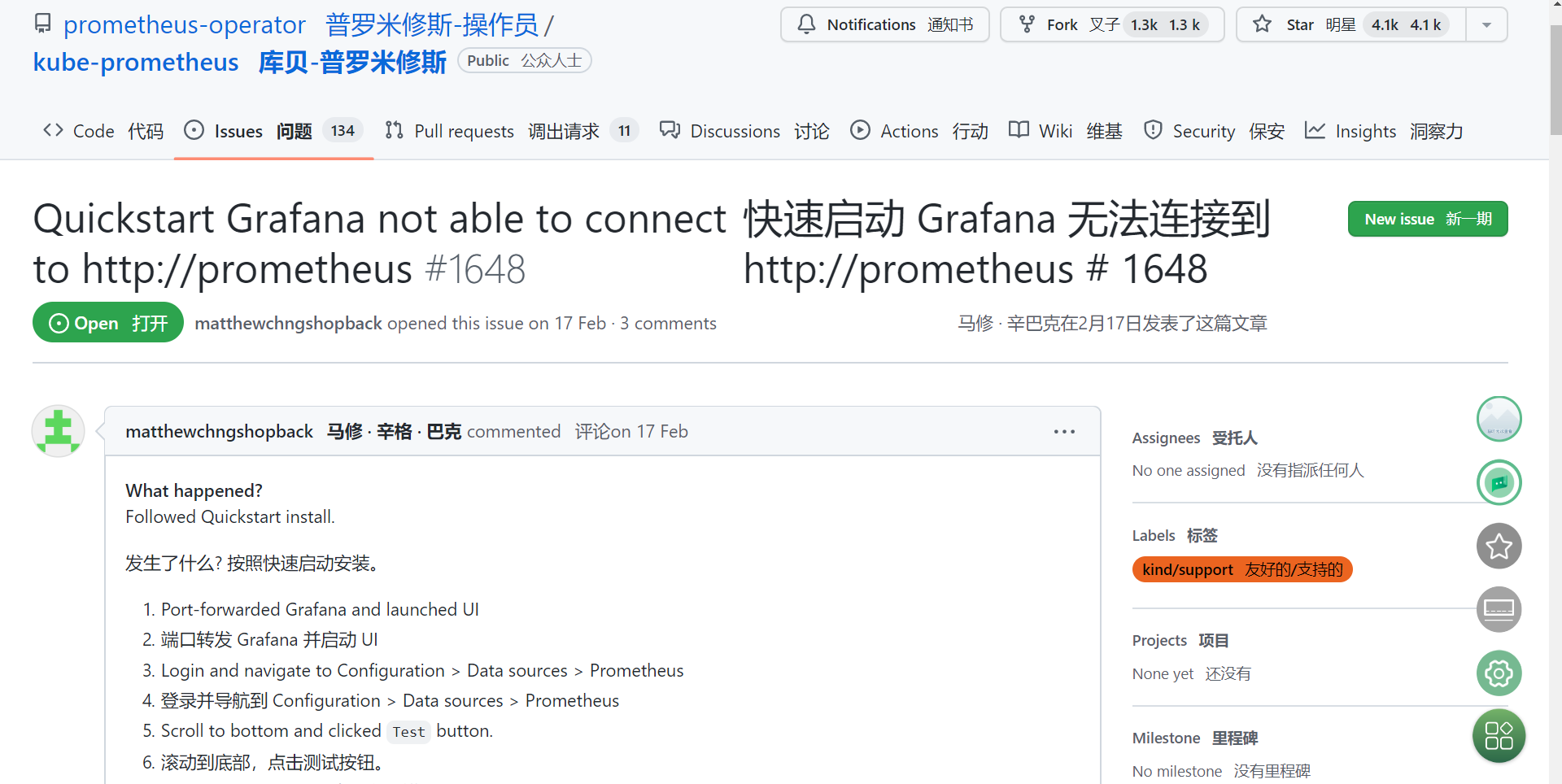
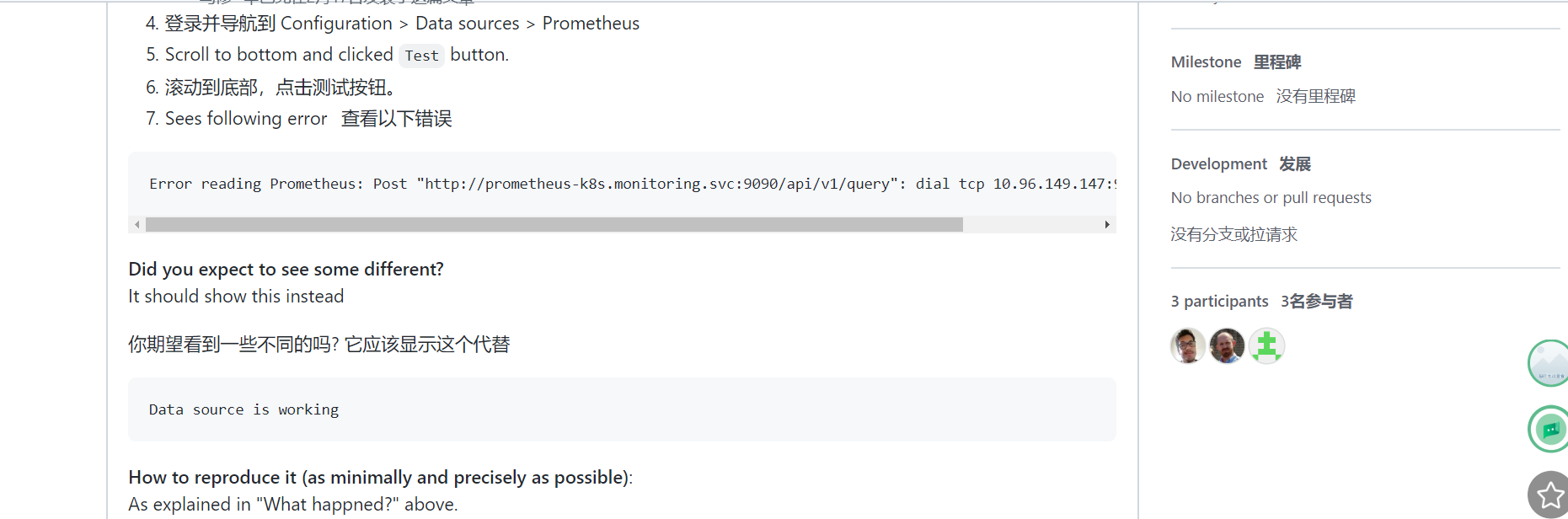
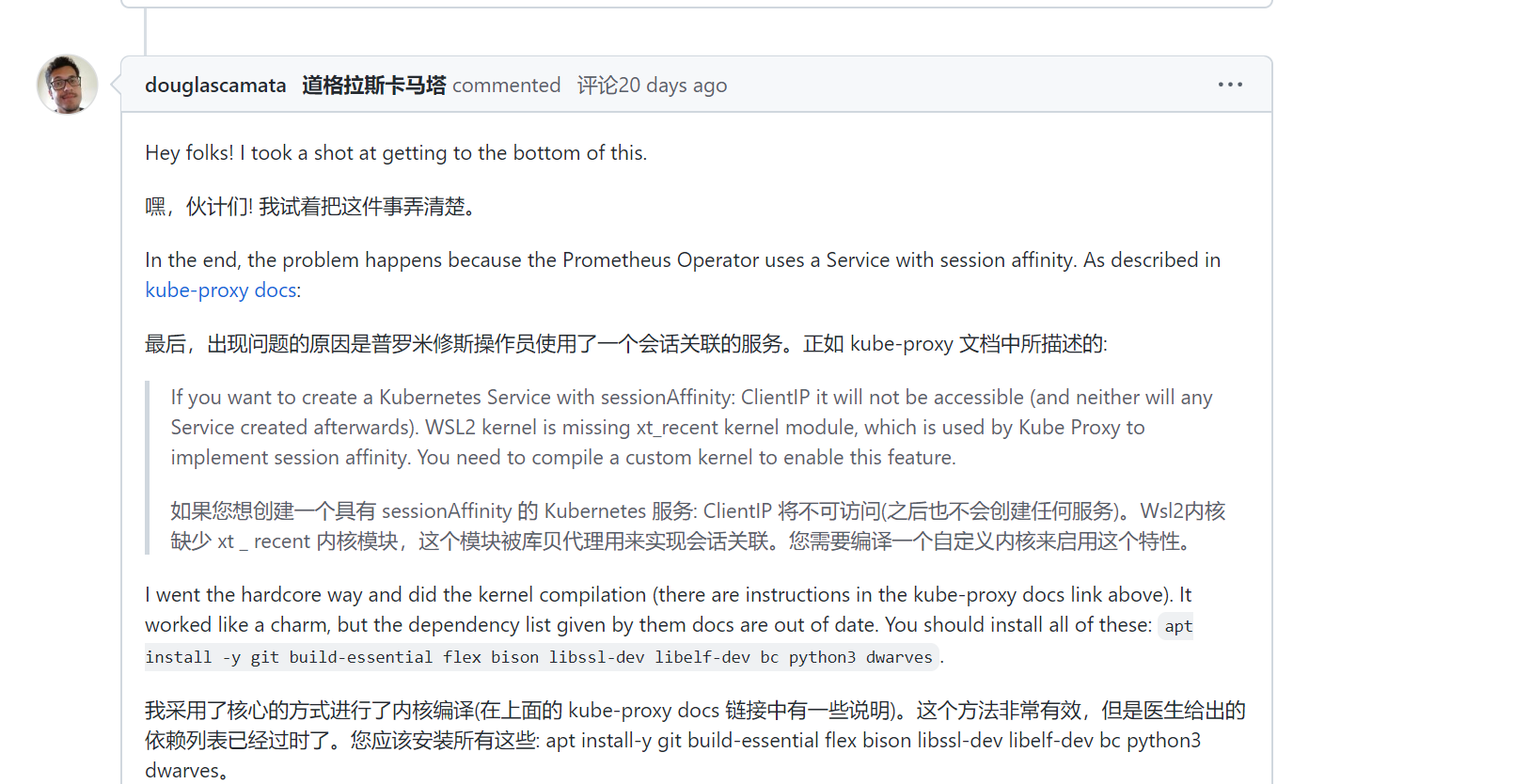
貌似找到了相同的issue,但是没发现有用的信息!!!😥 2022年5月4日20:57:44
https://github.com/prometheus-operator/kube-prometheus/issues/1648
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
- 个人微信二维码:x2675263825 (舍得), qq:2675263825。

- 个人微信公众号:《云原生架构师实战》

- 个人csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421
- 个人已开源干货😘
不服来怼:宇宙中最好用的云笔记 & 其他开源干货:https://www.yuque.com/go/doc/73723298?#
- 个人博客:(www.onlyyou520.com)
最后
好了,关于grafana实验就到这里了,感谢大家阅读,最后贴上我女神的photo,祝大家生活快乐,每天都过的有意义哦,我们下期见!

1