3、Istio流量管理
Istio流量管理

目录
[toc]
本节实战
| 实战名称 |
|---|
| 🚩 实战:路由到版本1-2023.11.11(测试成功) |
| 🚩 实战:基于用户身份的路由-2023.11.11(测试成功) |
| 🚩 实战:注入 HTTP 延迟故障-2023.11.12(测试成功) |
| 🚩 实战:注入 HTTP abort 故障-2023.11.12(测试成功) |
| 🚩 实战:流量拆分-2023.11.12(测试成功) |
| 🚩 实战:流量镜像-2023.11.12(测试成功) |
| 🚩 实战:熔断示例-2023.11.13(测试成功) |
| 🚩 实战:TCP 流量拆分-2023.11.15(测试成功) |
流量管理概述
上面我们了解了 Gateway 和 VirtualService 资源对象的作用,以及它们是如何影响 Envoy 的配置的,那么这些资源对象又是如何影响流量的呢?通过 Istio 如何实现流量管理的呢?
Istio 的流量路由规则可以很容易的控制服务之间的流量和 API 调用。Istio 简化了服务级别属性的配置,比如熔断器、超时和重试,并且能轻松的设置重要的任务,如 A/B 测试、金丝雀发布、基于流量百分比切分的分阶段发布等。它还提供了开箱即用的故障恢复特性, 有助于增强应用的健壮性,从而更好地应对被依赖的服务或网络发生故障的情况。
为了在网格中路由,Istio 需要知道所有的 endpoint 在哪以及它们属��于哪些服务。为了定位到 service registry(服务注册中心),Istio 会连接到一个服务发现系统。如果在 Kubernetes 集群上安装了 Istio,那么它将自动检测该集群中的服务和 endpoint。
使用此服务注册中心,Envoy 代理可以将流量定向到相关服务。大多数基于微服务的应用程序,每个服务的工作负载都有多个实例来处理流量,称为负载均衡池。默认情况下,Envoy 代理基于轮询调度模型在服务的负载均衡池内分发流量,按顺序将请求发送给池中每个成员, 一旦所有服务实例均接收过一次请求后,就重新回到第一个池成员。
Istio 基本的服务发现和负载均衡能力提供了一个可用的服务网格,但它能做到的远比这多的多。在许多情况下我们可能希望对网格的流量情况进行更细粒度的控制。作为 A/B 测试的一部分,可能想将特定百分比的流量定向到新版本的服务,或者为特定的服务实例子集应用不同的负载均衡策略。可能还想对进出网格的流量应用特殊的规则,或者将网格的外部依赖项添加到服务注册中心。通过使用 Istio 的流量管理 API 将流量配置添加到 Istio,就可以完成所有这些甚至更多的工作。
请求路由
首先我们来实现下最基本的流量请求路由的功能,这里我们将学习如何将请求动态路由到微服务的多个版本。
我们知道 Bookinfo 示例包含四个独立的微服务,每个微服务都有多个版本。其中 reviews 服务的三个不同版本已经部署并同时运行。我们可以在浏览器中访��问 Bookinfo 应用程序并刷新几次。正常会看到三种不同的 reviews 服务版本的输出,有时书评的输出包含星级评分,有时则不包含。这是因为没有明确的默认服务版本可路由,Istio 将以循环方式将请求路由到所有可用版本。
我们首先来将所有流量路由到微服务的 v1 版本,稍后,您将应用规则根据 HTTP 请求 header 的值路由流量。
1.路由到版本1
==🚩 实战:路由到版本1-2023.11.11(测试成功)==
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1pMnJxgL63oTlGFlhrfnXsA?pwd=7yqb
提取码:7yqb
2023.11.5-实战:BookInfo 示例应用-2023.11.5(测试成功) --本节测试yaml在此目录里

实验步骤:
graph LR
A[实战步骤] -->B(1️⃣ 部署VirtualService)
A[实战步骤] -->C(2️⃣ DestinationRule)
A[实战步骤] -->D(3️⃣ 验证)
要只路由到一个版本,则需要为微服务设置默认版本的 VirtualService。
🍀
应用规则
Istio 使用 VirtualService 来定义路由规则,只需要应用下面的资源对象即可:
$ kubectl apply -f samples/bookinfo/networking/virtual-service-all-v1.yaml
virtualservice.networking.istio.io/productpage created
virtualservice.networking.istio.io/reviews created
virtualservice.networking.istio.io/ratings created
virtualservice.networking.istio.io/details created
该资源清单中定义了四个 VirtualService 对象,分别是 productpage、reviews、ratings、details,它们分别对应着 Bookinfo 应用中的四个微服务,完整的清单如下所示:
# virtual-service-all-v1.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: productpage
spec:
hosts:
- productpage
http:
- route:
- destination:
host: productpage
subset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- route:
- destination:
host: ratings
subset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: details
spec:
hosts:
- details
http:
- route:
- destination:
host: details
subset: v1
---
我们可以看到这里的 VirtualService 对象中都定义了 subset 字段,这个字段就是用来指定微服务的版本的,这里我们将所有的微服务都指定为 v1 版本,这样所有的流量都会被路由到 v1 版本的微服务中,包括 reviews 服务,这样我们就不会再看到星级评分了。
🍀
但是如果我们现在直接去访问 Bookinfo 应用的话,是不能正常访问的,因为我们压根就还没指定这些 v1 版本的微服务到底在哪里。
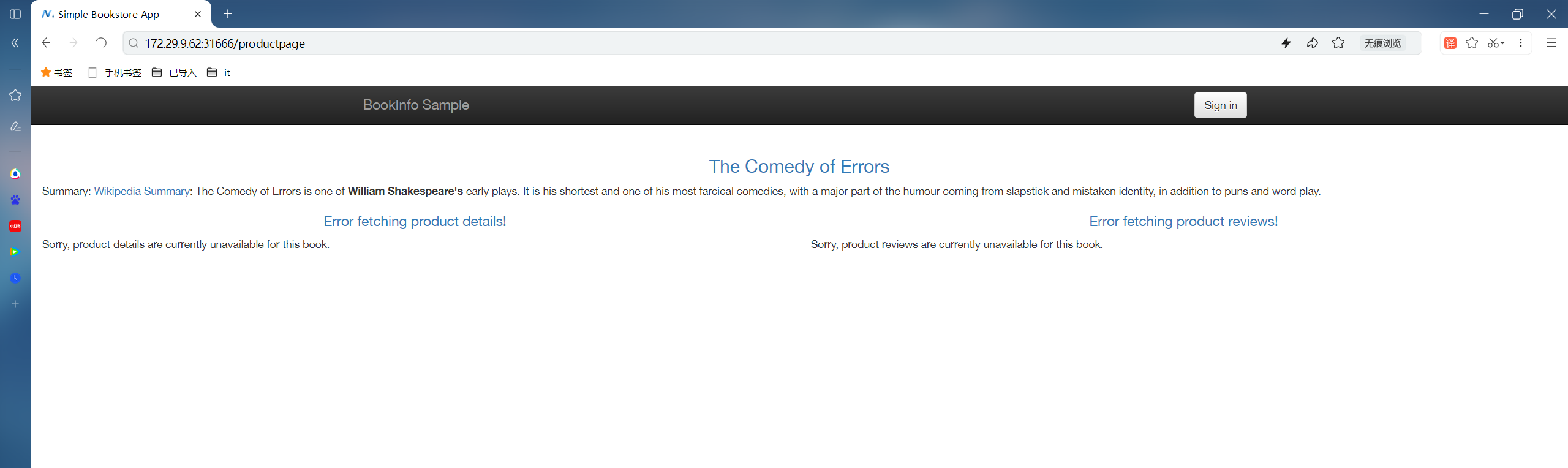
🍀
这个时候就需要用到另外一个资源对象 DestinationRule 了,我们需要为每个微服务创建一个 DestinationRule 对象,用来指定这些微服务的实际地址,这样 VirtualService 对象才能将流量路由到这些微服务中。Istio 在 DestinationRule 目标规则中使用 subsets 定义服务的版本,运行以下命令为 Bookinfo 服务创建默认的目标规则即可:
$ kubectl apply -f samples/bookinfo/networking/destination-rule-all.yaml
destinationrule.networking.istio.io/productpage created
destinationrule.networking.istio.io/reviews created
destinationrule.networking.istio.io/ratings created
destinationrule.networking.istio.io/details created
该资源清单中定义了四个 DestinationRule 对象,分别是 productpage、reviews、ratings、details 几个服务的目标规则,它们分别对应着 Bookinfo 应用中的四个微服务,完整的清单如下所示:
# destination-rule-all.yaml
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: productpage
spec:
host: productpage
subsets:
- name: v1
labels:
version: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: reviews
spec:
host: reviews
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
- name: v3
labels:
version: v3
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: ratings
spec:
host: ratings
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
- name: v2-mysql
labels:
version: v2-mysql
- name: v2-mysql-vm
labels:
version: v2-mysql-vm
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: details
spec:
host: details
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
---
🍀
现在我们就可以正常访问 Bookinfo 应用了,并且无论刷新多少次,页面的评论部分都不会显示评级星标,这是因为我们将 Istio 配置为将 reviews 服务的所有流量路由到版本 reviews:v1,而此版本的服务不访问星级评分服务。
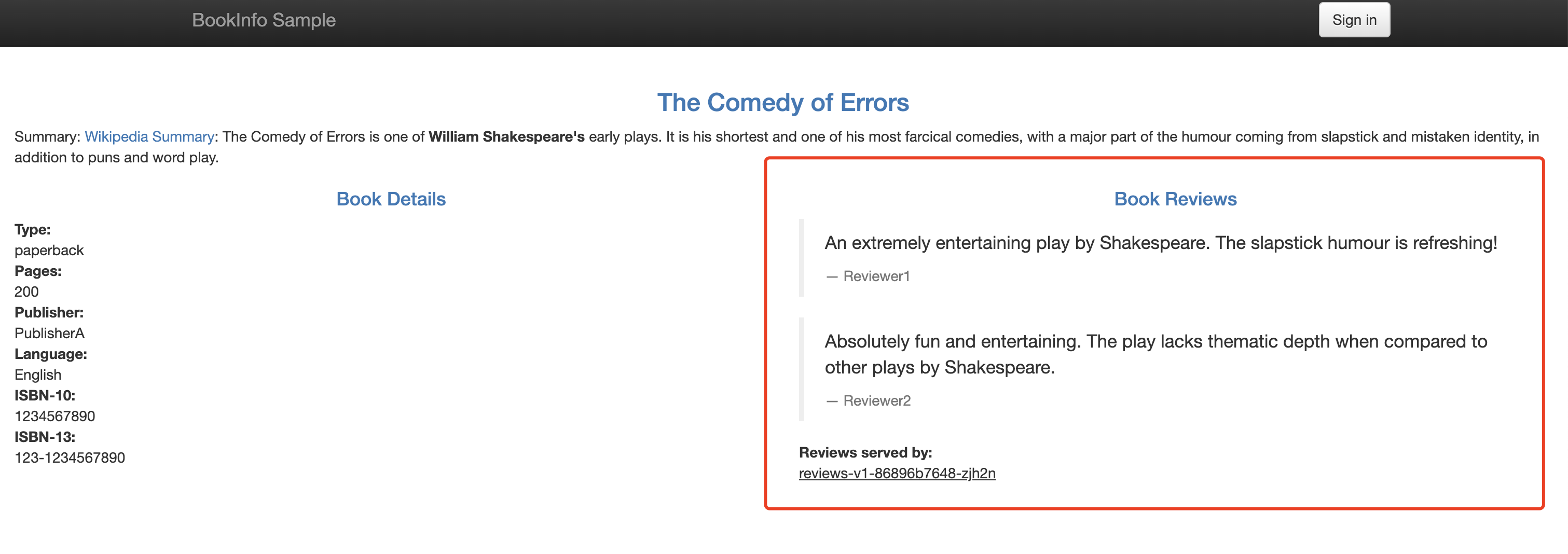
这样我们就成功将流量路由到服务的某一个版本上了。
原理分析
🍀
前面章节中我们只定义了一个名为 bookinfo 的 VirtualService 资源对象就可以正常访问了:
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: bookinfo
namespace: default
spec:
gateways:
- bookinfo-gateway
hosts:
- "*"
http:
- match:
- uri:
exact: /productpage
- uri:
prefix: /static
- uri:
exact: /login
- uri:
exact: /logout
- uri:
prefix: /api/v1/products
route:
- destination:
host: productpage
port:
number: 9080
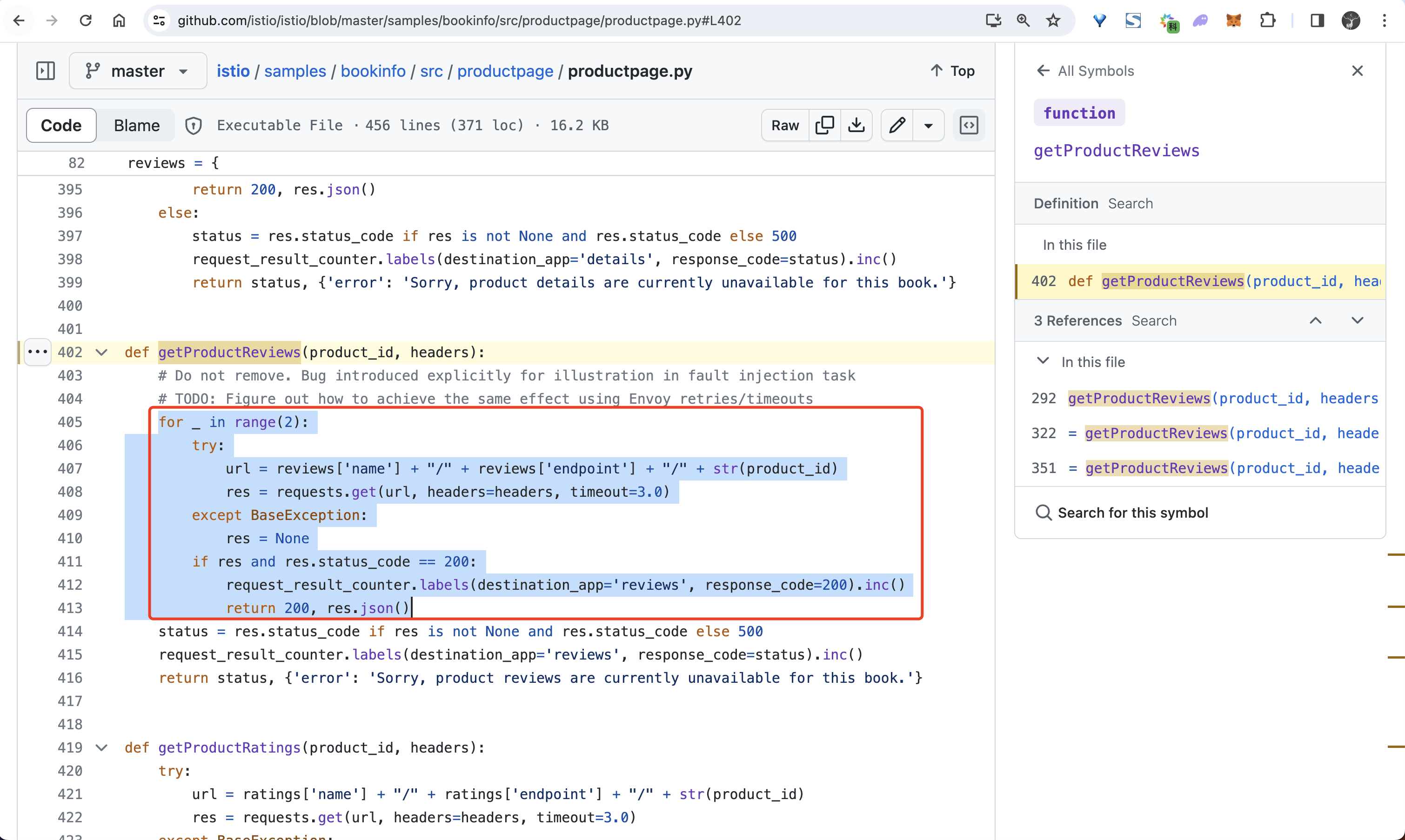
很明显上面这个虚拟服务对象是我们访问 Bookinfo 应用的入口路由规则,所以这个虚拟服务对象实际上是为 istio-ingressgateway 入口网关服务定义的。 它将所有的流量都路由到了 productpage 这个服务上,而 productpage 这个服务又会去调用其他的服务来获取数据,在 productpage 服务中调用其他微服务 其实就是直接通过服务名称来调用的,比如调用 reviews 服务就是直接通过 reviews:9080 这个服务来调用的,我们可以查看 productpage 的代码来验证这一点:
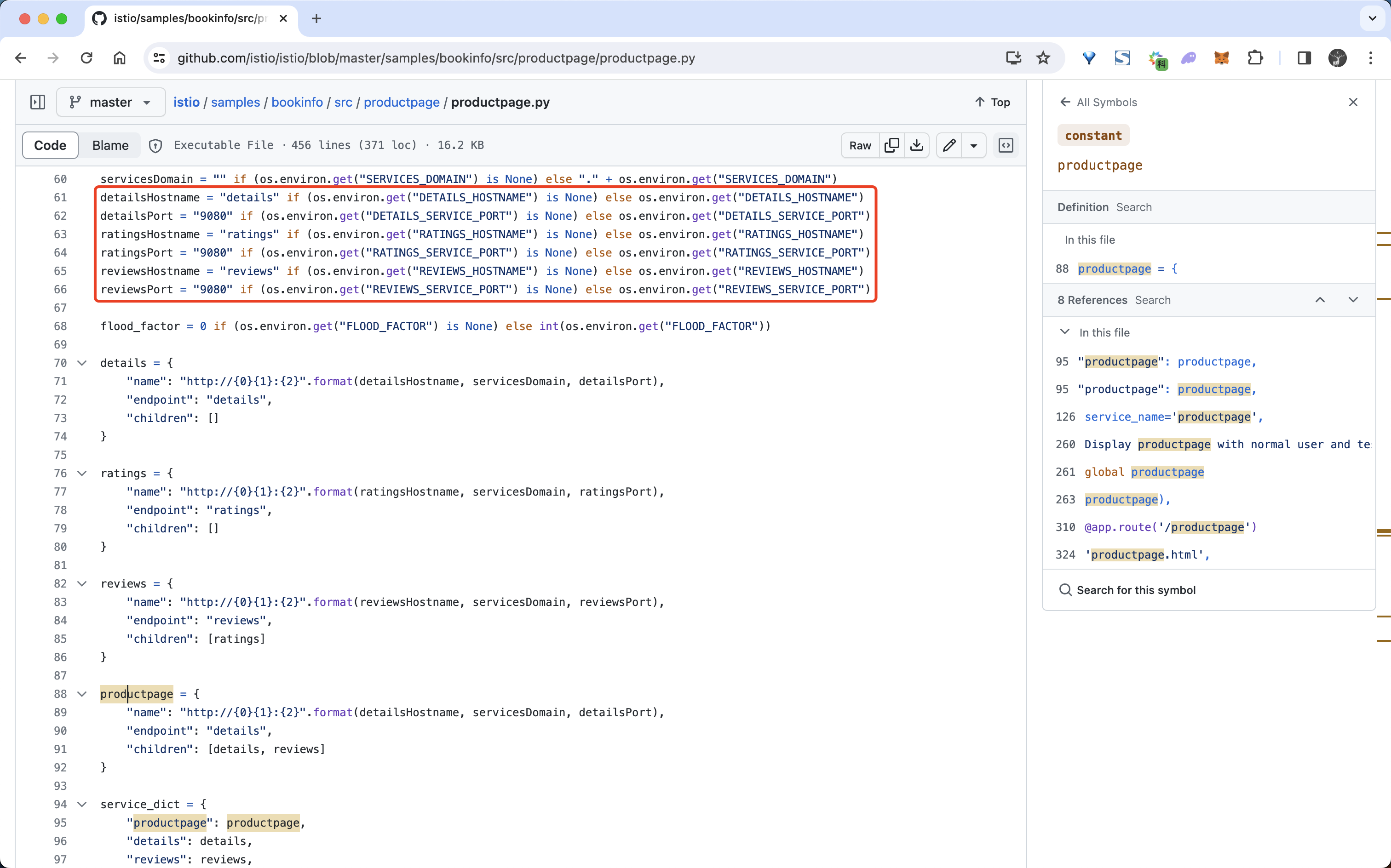
🍀
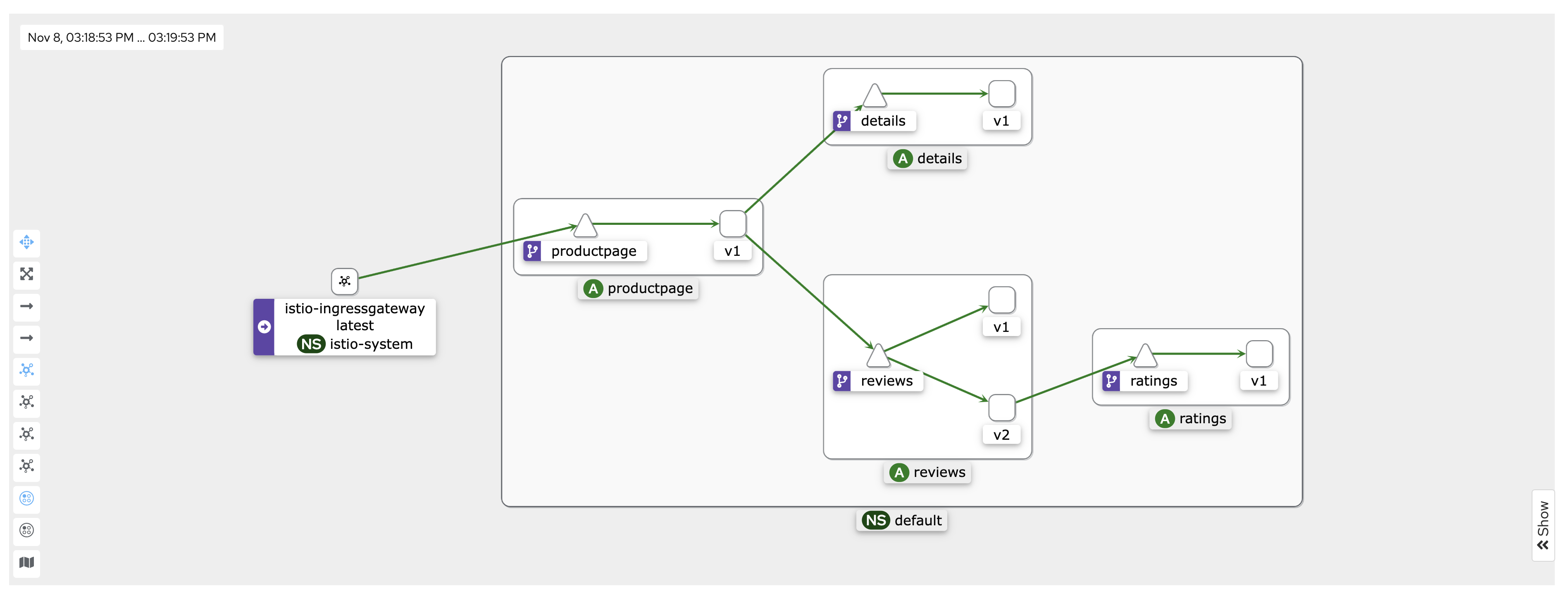
我们可以再次查看 Bookinfo 在网格内的请求架构图:
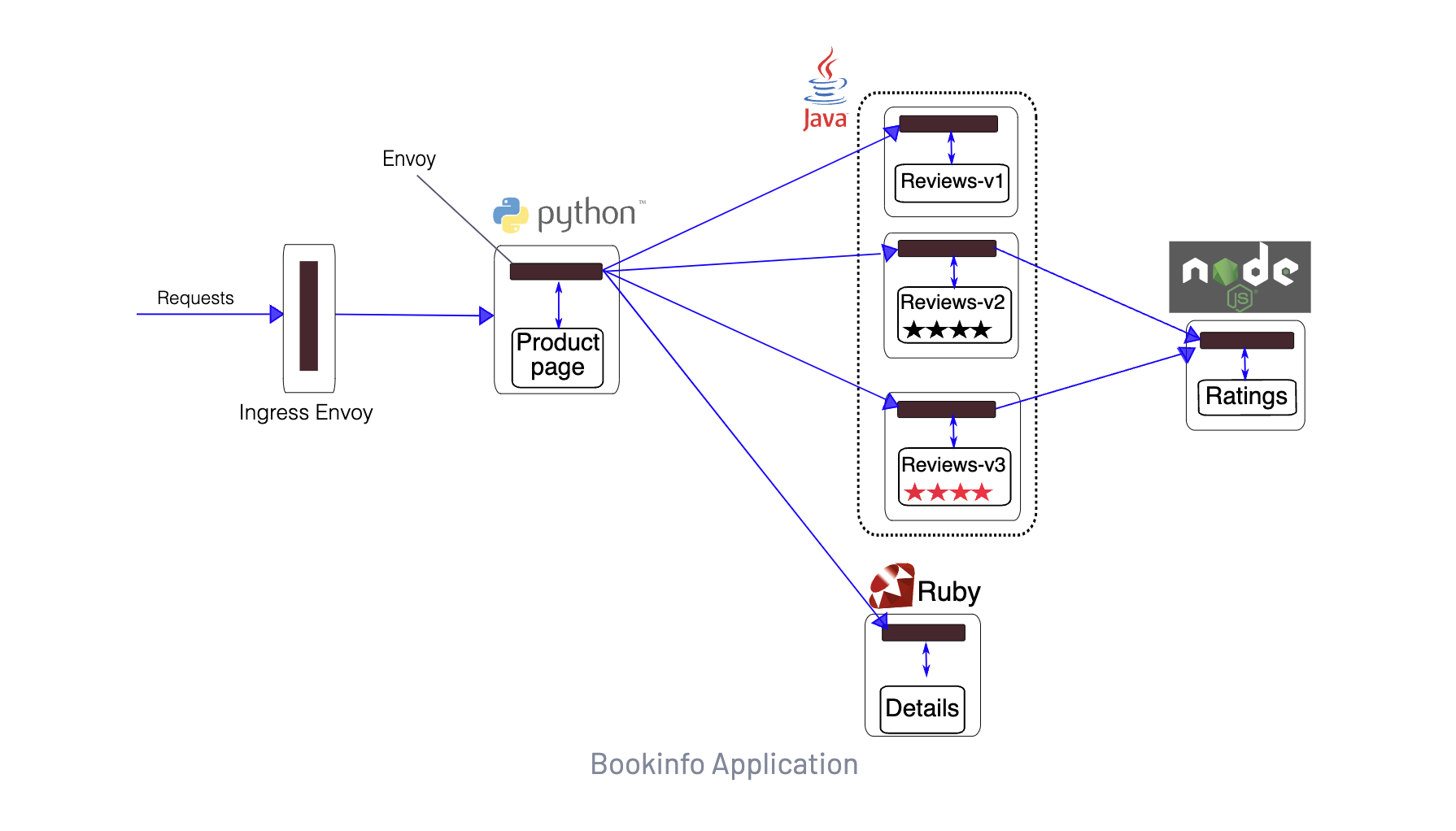
当我们在浏览器中访问 http://<gateway url>/productpage 时,请求将进入网格中的 istio-ingressgateway 服务,然后将请求转发到 productpage 服务。productpage 服务将调用 reviews 和 details 服务来填充页面的内容,然后将其返回给用户。(reviews 服务包括 3 个不同版本的应用,可以通过 version 标签区分)
🍀
现在我们只想将流量路由到 reviews:v1 版本去,按照传统的方法只需要将 reviews 的 Service 对象去强制关联 version: v1 这个标签即可,现在�我们所有的服务都被注入了一个 Envoy 的 Sidecar 代理,通过 Envoy 很容易就可以实现这个路由功能,而相应的在 Istio 中我们只需要通过 VirtualService 和 DestinationRule 这两个资源对象就可以来实现了。上面我们创建的关于 reviews 服务的这两个对象如下所示:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: reviews
spec:
host: reviews
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
- name: v3
labels:
version: v3
那么这两个对象是如何来影响 Envoy Sidecar 的呢?前面我们已�经分析了流量从 istio-ingressgateway 进来后被路由到了 productpage 服务,那么 productpage 又该如何去访问其他微服务呢?同样我们可以使用 istioctl proxy-config 来查看 productpage 服务的 Envoy 配置。
🍀
每个 Envoy Sidecar 都有一个绑定到 0.0.0.0:15001 的监听器,然后利用 IP tables 将 pod 的所有入站和出站流量路由到这里,此监听器会配置一个 useOriginalDst: true,这意味着它将请求交给最符合请求原始目标的监听器。如果找不到任何匹配的虚拟监听器,它会将请求发送给返回 404 的 BlackHoleCluster,我们可以查看下 15001 端口的监听器配置:
[root@master1 istio-1.19.3]#istioctl proxy-config listeners productpage-v1-564d4686f-7vhks --port 15001 -oyaml
- accessLog:
- filter:
responseFlagFilter:
flags:
- NR
name: envoy.access_loggers.file
typedConfig:
'@type': type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
logFormat:
textFormatSource:
inlineString: |
[%START_TIME%] "%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%" %RESPONSE_CODE% %RESPONSE_FLAGS% %RESPONSE_CODE_DETAILS% %CONNECTION_TERMINATION_DETAILS% "%UPSTREAM_TRANSPORT_FAILURE_REASON%" %BYTES_RECEIVED% %BYTES_SENT% %DURATION% %RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)% "%REQ(X-FORWARDED-FOR)%" "%REQ(USER-AGENT)%" "%REQ(X-REQUEST-ID)%" "%REQ(:AUTHORITY)%" "%UPSTREAM_HOST%" %UPSTREAM_CLUSTER% %UPSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_REMOTE_ADDRESS% %REQUESTED_SERVER_NAME% %ROUTE_NAME%
path: /dev/stdout
address:
socketAddress:
address: 0.0.0.0
portValue: 15001
filterChains:
- filterChainMatch:
destinationPort: 15001
filters:
- name: istio.stats
typedConfig:
'@type': type.googleapis.com/stats.PluginConfig
- name: envoy.filters.network.tcp_proxy
typedConfig:
'@type': type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
cluster: BlackHoleCluster
statPrefix: BlackHoleCluster
name: virtualOutbound-blackhole
- filters:
- name: istio.stats
typedConfig:
'@type': type.googleapis.com/stats.PluginConfig
- name: envoy.filters.network.tcp_proxy
typedConfig:
'@type': type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
accessLog:
- name: envoy.access_loggers.file
typedConfig:
'@type': type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog
logFormat:
textFormatSource:
inlineString: |
[%START_TIME%] "%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%" %RESPONSE_CODE% %RESPONSE_FLAGS% %RESPONSE_CODE_DETAILS% %CONNECTION_TERMINATION_DETAILS% "%UPSTREAM_TRANSPORT_FAILURE_REASON%" %BYTES_RECEIVED% %BYTES_SENT% %DURATION% %RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)% "%REQ(X-FORWARDED-FOR)%" "%REQ(USER-AGENT)%" "%REQ(X-REQUEST-ID)%" "%REQ(:AUTHORITY)%" "%UPSTREAM_HOST%" %UPSTREAM_CLUSTER% %UPSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_LOCAL_ADDRESS% %DOWNSTREAM_REMOTE_ADDRESS% %REQUESTED_SERVER_NAME% %ROUTE_NAME%
path: /dev/stdout
cluster: PassthroughCluster
statPrefix: PassthroughCluster
name: virtualOutbound-catchall-tcp
name: virtualOutbound
trafficDirection: OUTBOUND
useOriginalDst: true
[root@master1 istio-1.19.3]#
🍀
实际上我们的请求是到 9080 端口(productpage 服务绑定 9080 端口)的 HTTP 出站请求,这意味着它被切换到 0.0.0.0:9080 虚拟监听器。所以我们查看下 9080 端口的监听器配置:
# productpage 默认访问其他服务的 9080 端口
$ istioctl proxy-config listeners productpage-v1-564d4686f-wwqqf --port 9080 -oyaml
- address:
socketAddress:
address: 0.0.0.0
portValue: 9080
# ......
rds:
configSource:
ads: {}
initialFetchTimeout: 0s
resourceApiVersion: V3
routeConfigName: "9080" # RDS的路由配置名称
# ......
name: 0.0.0.0_9080
trafficDirection: OUTBOUND # 出流量
可以看到此监听器在其配置的 RDS 中查找名为 9080 的路由配置,我们可以使用 istioctl proxy-config routes 命令来查看这个路由配置的详�细信息:
# 查看 9080 这个路由配置
$ istioctl proxy-config routes productpage-v1-564d4686f-wwqqf --name 9080 -oyaml
- name: "9080"
virtualHosts:
- domains:
- details.default.svc.cluster.local
- details
- details.default.svc
- details.default
- 10.111.83.224
name: details.default.svc.cluster.local:9080
routes:
- decorator:
operation: details.default.svc.cluster.local:9080/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/details
route:
cluster: outbound|9080|v1|details.default.svc.cluster.local
# ......
- domains:
- productpage.default.svc.cluster.local
- productpage
- productpage.default.svc
- productpage.default
- 10.97.120.23
name: productpage.default.svc.cluster.local:9080
routes:
- decorator:
operation: productpage.default.svc.cluster.local:9080/*
match:
prefix: /
name: default
route:
cluster: outbound|9080||productpage.default.svc.cluster.local
# ......
- domains:
- ratings.default.svc.cluster.local
- ratings
- ratings.default.svc
- ratings.default
- 10.101.184.235
name: ratings.default.svc.cluster.local:9080
routes:
- decorator:
operation: ratings.default.svc.cluster.local:9080/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/ratings
route:
cluster: outbound|9080|v1|ratings.default.svc.cluster.local
# ......
- domains:
- reviews.default.svc.cluster.local
- reviews
- reviews.default.svc
- reviews.default
- 10.97.120.56
name: reviews.default.svc.cluster.local:9080
routes:
- decorator:
operation: reviews.default.svc.cluster.local:9080/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/reviews
route:
cluster: outbound|9080|v1|reviews.default.svc.cluster.local
# ......
- domains:
- '*'
name: allow_any
routes:
- match:
prefix: /
name: allow_any
route:
cluster: PassthroughCluster
# ......
这个路由配置中其实包含了 K8s Service 对象中监听 9080 端口的所有服务,如果没有创建对应的 VirtualService 对象,对应的路由配置就没有 metadata.filterMetadata.istio.config 这个属性。比如现在我们正在通过 productpage 请求前往 reviews 服务,因此 Envoy 将选择我们的请求与域匹配的虚拟主机。一旦在域上匹配,Envoy 会查找与请求匹配的第一条路径,我们这里没有任何高级路由,因此只有一条路由匹配所有内容。这条路由告诉 Envoy 将请求发送到 outbound|9080|v1|reviews.default.svc.cluster.local 集群,因为前面我们创建的 reviews 这个 VirtualService 对象配置了的 destination.subset: v1,所以这里的集群命名上多了一个 subset。
需要注意的是我们在 VirtualService 对象里面配置了 destination.subset: v1,那么必须要有对应的 subset 存在才行,否则不会生成对应的 Envoy 集群配置,那么就不能正常访问该服务了,而该 subset 就是通过前面的 DestinationRule 对象来定义的,现在我们就可以来查看这个集群配置了:
$ istioctl proxy-config cluster productpage-v1-564d4686f-wwqqf --fqdn reviews.default.svc.cluster.local -o yaml
- edsClusterConfig:
edsConfig:
ads: {}
initialFetchTimeout: 0s
resourceApiVersion: V3
serviceName: outbound|9080||reviews.default.svc.cluster.local
lbPolicy: LEAST_REQUEST
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/destination-rule/reviews
services:
- host: reviews.default.svc.cluster.local
name: reviews
namespace: default
# ......
name: outbound|9080||reviews.default.svc.cluster.local
type: EDS
- edsClusterConfig:
edsConfig:
ads: {}
initialFetchTimeout: 0s
resourceApiVersion: V3
serviceName: outbound|9080|v1|reviews.default.svc.cluster.local
lbPolicy: LEAST_REQUEST
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/destination-rule/reviews
services:
- host: reviews.default.svc.cluster.local
name: reviews
namespace: default
subset: v1
name: outbound|9080|v1|reviews.default.svc.cluster.local
# ......
type: EDS
- edsClusterConfig:
edsConfig:
ads: {}
initialFetchTimeout: 0s
resourceApiVersion: V3
serviceName: outbound|9080|v2|reviews.default.svc.cluster.local
filters:
- name: istio.metadata_exchange
typedConfig:
'@type': type.googleapis.com/envoy.tcp.metadataexchange.config.MetadataExchange
protocol: istio-peer-exchange
lbPolicy: LEAST_REQUEST
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/destination-rule/reviews
services:
- host: reviews.default.svc.cluster.local
name: reviews
namespace: default
subset: v2
name: outbound|9080|v2|reviews.default.svc.cluster.local
# ......
type: EDS
- edsClusterConfig:
edsConfig:
ads: {}
initialFetchTimeout: 0s
resourceApiVersion: V3
serviceName: outbound|9080|v3|reviews.default.svc.cluster.local
filters:
- name: istio.metadata_exchange
typedConfig:
'@type': type.googleapis.com/envoy.tcp.metadataexchange.config.MetadataExchange
protocol: istio-peer-exchange
lbPolicy: LEAST_REQUEST
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/destination-rule/reviews
services:
- host: reviews.default.svc.cluster.local
name: reviews
namespace: default
subset: v3
name: outbound|9080|v3|reviews.default.svc.cluster.local
# ......
type: EDS
从上面配置可以看到里面一共包含了 4 个 reviews 相关的集群,一个是原始的不包含 subset 的,而另外三个就是前面我们在 DestinationRule 对象中配置的 3 个 subset,所以其实 DestinationRule 映射到 Envoy 的配置文件中就是 Cluster。
🍀
最后我们同样还可以查看每个集群下面包含的 endpoint 有哪些:
$ istioctl proxy-config endpoint productpage-v1-564d4686f-wwqqf --cluster "outbound|9080||reviews.default.svc.cluster.local" -o yaml
- edsServiceName: outbound|9080||reviews.default.svc.cluster.local
- address:
socketAddress:
address: 10.244.2.84
portValue: 9080
# ......
weight: 1
- address:
socketAddress:
address: 10.244.2.83
portValue: 9080
# ......
weight: 1
- address:
socketAddress:
address: 10.244.2.88
portValue: 9080
# ......
weight: 1
name: outbound|9080||reviews.default.svc.cluster.local
observabilityName: outbound|9080||reviews.default.svc.cluster.local
$ istioctl proxy-config endpoint productpage-v1-564d4686f-wwqqf --cluster "outbound|9080|v1|reviews.default.svc.cluster.local" -o yaml
- edsServiceName: outbound|9080|v1|reviews.default.svc.cluster.local
hostStatuses:
- address:
socketAddress:
address: 10.244.2.84
portValue: 9080
weight: 1
name: outbound|9080|v1|reviews.default.svc.cluster.local
observabilityName: outbound|9080|v1|reviews.default.svc.cluster.local
# 过滤 version=v1 的 reviews pod
$ kubectl get pod -l app=reviews,version=v1 -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
reviews-v1-86896b7648-zjh2n 2/2 Running 4 (5h18m ago) 6d17h 10.244.2.84 node2 <none> <none>
可以看到不包含 subset 的集群下面的 endpoint 其实就是 reviews 这个 Service 对象的 endpoint 集合,包含 subset 就只有和该子集匹配的后端实例了。到了这一步,一切皆明了,后面的事情就跟之前的套路一样了,具体的 Endpoint 对应打了标签 version=v1 的 Pod。
🍀
到这里我们是不是就实现了通过 VirtualService 和 DestinationRule 对象将流量路由到了指定的版本上面了,上面的整个过程就是请求从 productpage 到 reviews 的过程,从 reviews 到网格内其他应用的流量与上面类似,就不展开讨论了。
2.基于用户身份的路由
==🚩 实战:基于用户身份的路由-2023.11.11(测试成功)==
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1pMnJxgL63oTlGFlhrfnXsA?pwd=7yqb
提取码:7yqb
2023.11.5-实战:BookInfo 示例应用-2023.11.5(测试成功) --本节测试yaml在此目录里
实验步骤:
graph LR
A[实战步骤] -->B(1️⃣ 更新VirtualService)
A[实战步骤] -->C(2️⃣ 测试)
接下来我们继续更改路由配置,将来自特定用户的所有流量路由到特定服务版本。我们这里将配置来自名为 Jason 的用户的所有流量被路由到服务 reviews:v2。
注意 Istio 对用户身份没有任何特殊的内置机制,productpage 服务在所有到 reviews 服务的 HTTP 请求中都增加了一个自定义的 end-user 请求头来实现该效果:headers['end-user'] = session['user']。
🍀
要实现该功能,只需要创建下面的资源对象即可:
$ kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-test-v2.yaml
virtualservice.networking.istio.io/reviews configured
该资源清单文件创建了一个如下所示的 VirtualService 资源对象:
# virtual-service-reviews-test-v2.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- match:
- headers:
end-user:
exact: jason
route:
- destination:
host: reviews
subset: v2
- route:
- destination:
host: reviews
subset: v1
该对象设置了一条路由规则,它会根据 productpage 服务发起的请求的 end-user 自定义请求头内容进行匹配,如果有该内容且为 jason 则会将流量路由到 reviews 服务的 v2 版本,其余的还是被路由到 v1 版本去。
🍀
现在我们可以前往浏览器访问 Bookinfo 应用,多刷新几次可以看到评论始终访问到的是 v1 版本的服务,即没有星标的:
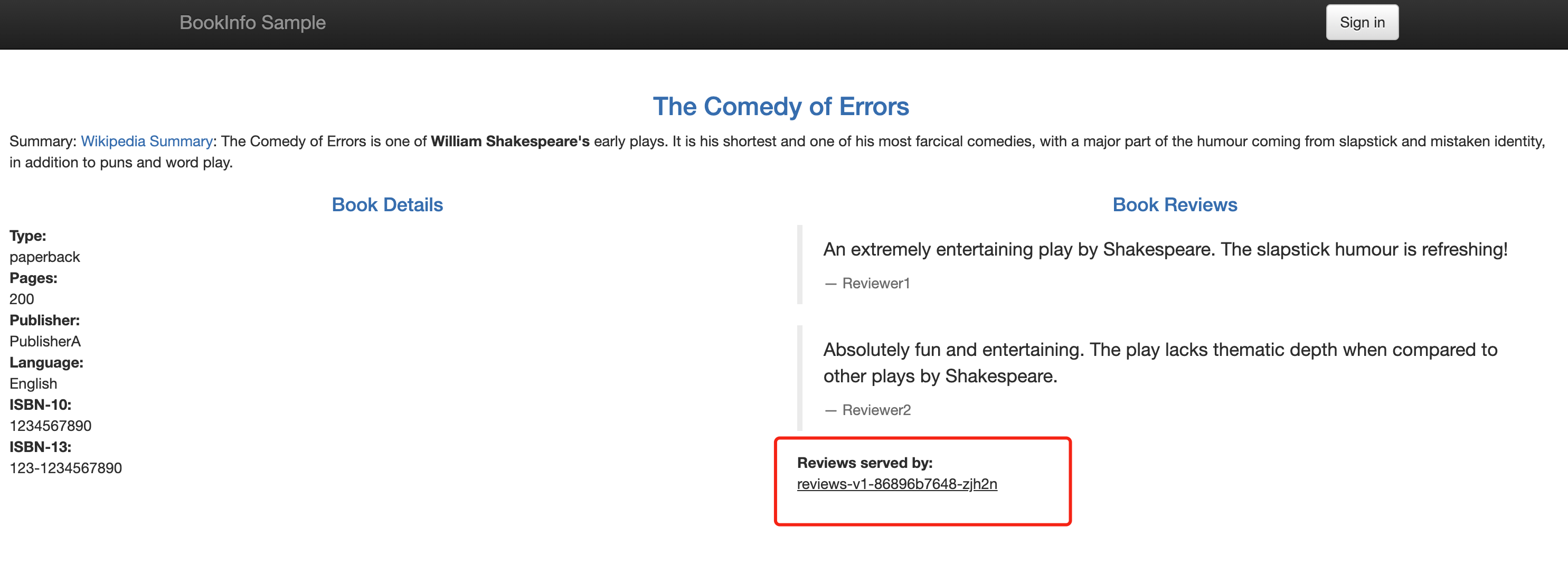
🍀
然后我们点击页面右上角的 Sign in 按钮,使用 jason 进行登录,登录后页面就会出现带有黑色星标的 v2 版本的评论服务,即使多刷新几次依然如此:
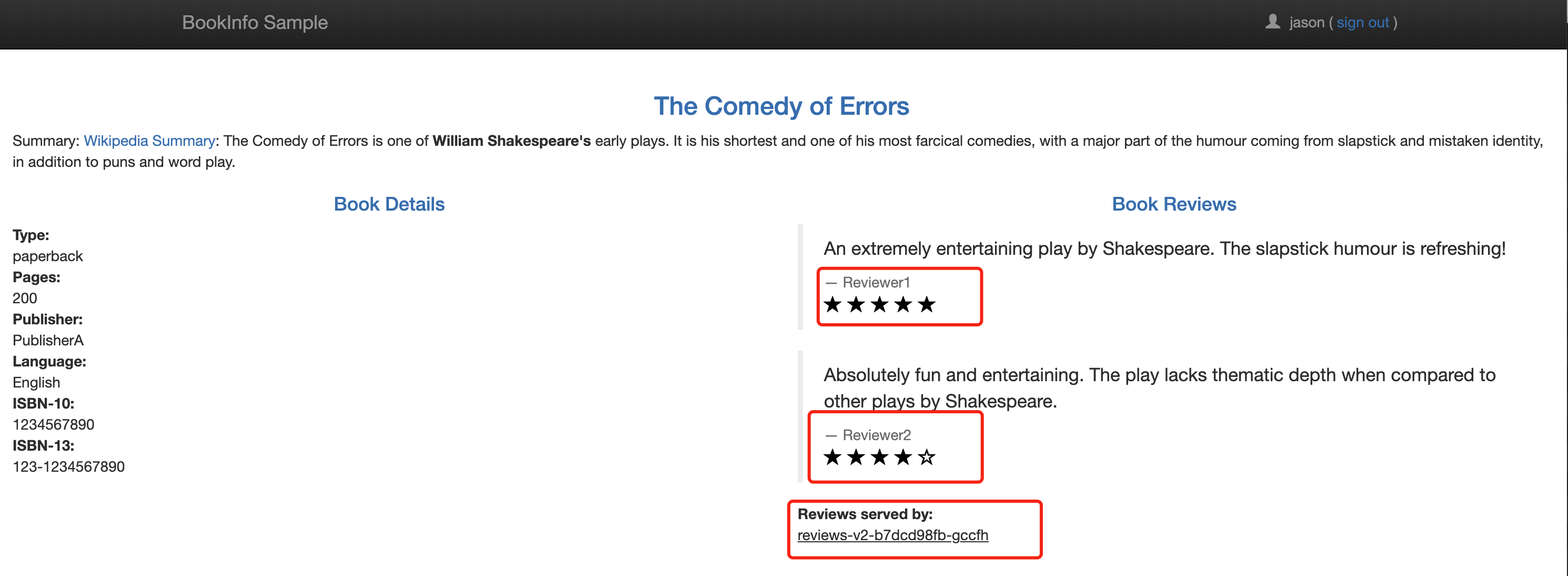
如果我们选择使用其他用户进行登录或者注销则星标就会消失,这是因为除了 Jason 之外,所有用户的流量都被路由到 reviews:v1。
🍀
同样的我们可以去查看下对应的 Envoy Sidecar 配置的变化,因为这里我们只更新了一个 VirtualService 对象,所以只会对 Envoy 的路由表产生影响,查看对应的路由配置即可:
$ istioctl proxy-config routes productpage-v1-564d4686f-wwqqf --name 9080 -oyaml
- name: "9080"
validateClusters: false
virtualHosts:
# ......
- domains:
- reviews.default.svc.cluster.local
- reviews
- reviews.default.svc
- reviews.default
- 10.97.120.56
includeRequestAttemptCount: true
name: reviews.default.svc.cluster.local:9080
routes:
- decorator:
operation: reviews.default.svc.cluster.local:9080/*
match:
caseSensitive: true
headers:
- name: end-user
stringMatch:
exact: jason
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/reviews
route:
cluster: outbound|9080|v2|reviews.default.svc.cluster.local
maxGrpcTimeout: 0s
# ......
- decorator:
operation: reviews.default.svc.cluster.local:9080/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/reviews
route:
cluster: outbound|9080|v1|reviews.default.svc.cluster.local
maxGrpcTimeout: 0s
# ......
从配置上我们可以看到现在的 Envoy 配置中新增了一条路由规则,如下所示:
match:
caseSensitive: true
headers:
- name: end-user
stringMatch:
exact: jason
prefix: /
route:
cluster: outbound|9080|v2|reviews.default.svc.cluster.local
当请求头中包含 end-user:jason 的时候请求会被路由到 outbound|9080|v2|reviews.default.svc.cluster.local 这个 Envoy Cluster 集群,这个集群就是前面我们通过 DestinationRule 创建的 v2 这个子集,所以最后请求会被路由到带有黑色星标的评论服务去。
🍀
到这里我们就明白了要通过 Istio 实现服务的流量管理,需要用到 Gateway、VirtualService、DestinationRule 三个 CRD 对象,这些对象其实最终都是去拼凑 Envoy 的配置,每个对象管理 Envoy 配置的一部分,把这个关系搞清楚我们就能更好的掌握 Istio 的使用了。
故障注入
前面我们讲解了在 Istio 中如何进行请求路由管理,这里我们来讲解下如何在 Istio 中进行故障注入,故障注入是指在服务调用过程中,故意制造一些故障,来验证服务的容错能力。
1.注入 HTTP 延迟故障
==🚩 实战:注入 HTTP 延迟故障-2023.11.12(测试成功)==
测试环境:
本次测试是在前面几次环境基础上传测试的,因此需要先具备前几次测试环境。
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1pMnJxgL63oTlGFlhrfnXsA?pwd=7yqb
提取码:7yqb
2023.11.5-实战:BookInfo 示例应用-2023.11.5(测试成功) --本节测试yaml在此目录里

实验步骤:
graph LR
A[实战步骤] -->B(1️⃣ 更新VirtualService)
A[实战步骤] -->C(2️⃣ 验证)
首先保留前面的请求路由规则,即 jason 用户的流量被路由到 reviews:v2,其他用户的流量被路由到 reviews:v1。然后我们将为用户 jason 在 reviews:v2 和 ratings 服务之间注入一个 7 秒的延迟。这个测试可以发现一个故意引入 Bookinfo 应用程序中的 bug。
reviews:v2服务对ratings服务的调用具有 10 秒的硬编码连接超时。所以尽管引入了 7 秒的延迟,我们仍然期望端到端的流程是没有任何错误的。
🍀
创建故障注入规则以延迟来自测试用户 jason 的流量,应用下面的资源对象即可:
kubectl apply -f samples/bookinfo/networking/virtual-service-ratings-test-delay.yaml
该资源对象的完整清单如下所示:
piVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- match:
- headers:
end-user:
exact: jason
fault:
delay:
percentage:
value: 100.0
fixedDelay: 7s
route:
- destination:
host: ratings
subset: v1
- route:
- destination:
host: ratings
subset: v1
其实就是在 ratings 这个服务的 VirtualService 对象中增加了一个 fault 字段,用来指定故障注入的规则,这里我们指定了 delay 故障注入规则,即延迟 100% 的流量 7 秒钟,这样我们就可以在 jason 用户的流量中看到延迟的效果了。
🍀
应用上面的规则后,我们可以通过浏览器打开 Bookinfo 应用,以用户 jason 登录到 /productpage 页面。
我们的期望是 Bookinfo 主页在大约 7 秒钟加载完成并且没有错误(因为硬编码是 10s 超时),但是会出现如下所示的问题:
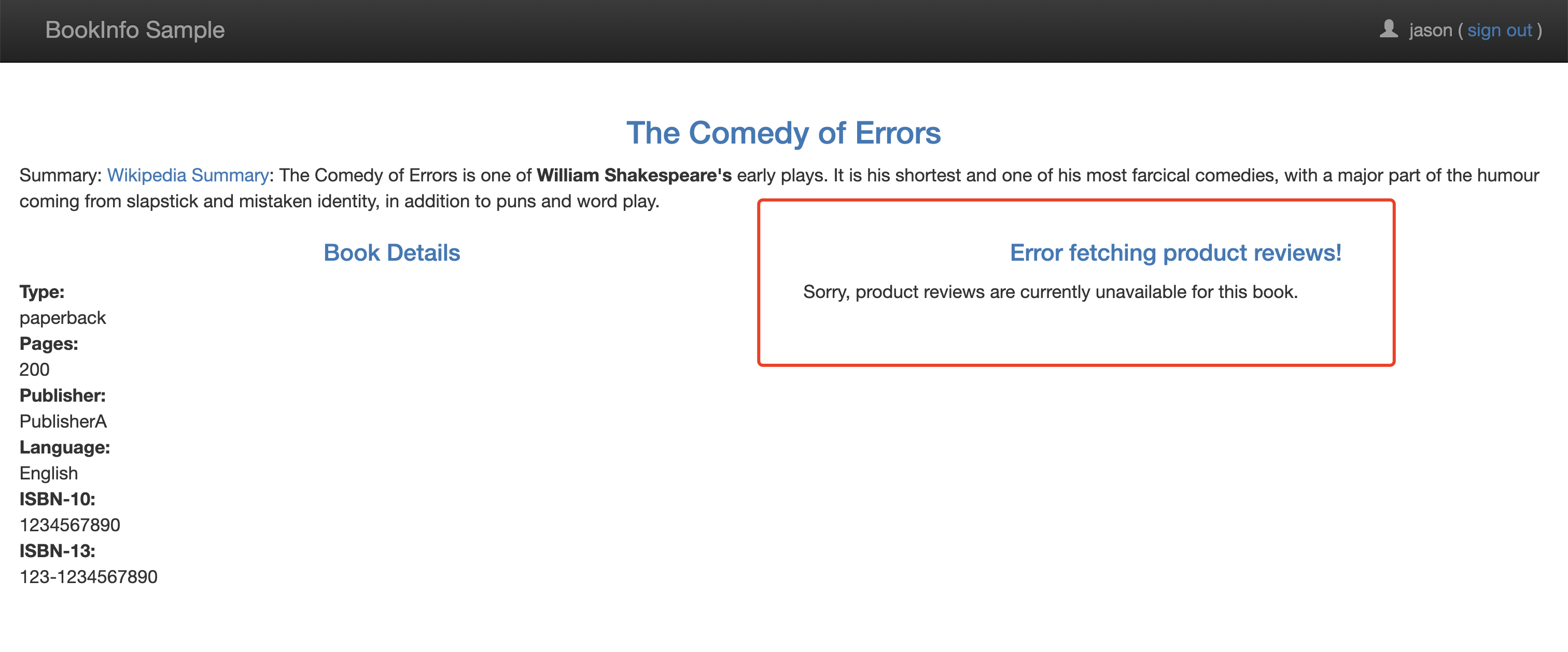
在 Chrome 浏览器中我们可以右键打开审查元素,打开网络标签,重新加载页面,我们会看到页面加载实际上用了大约 6 秒。
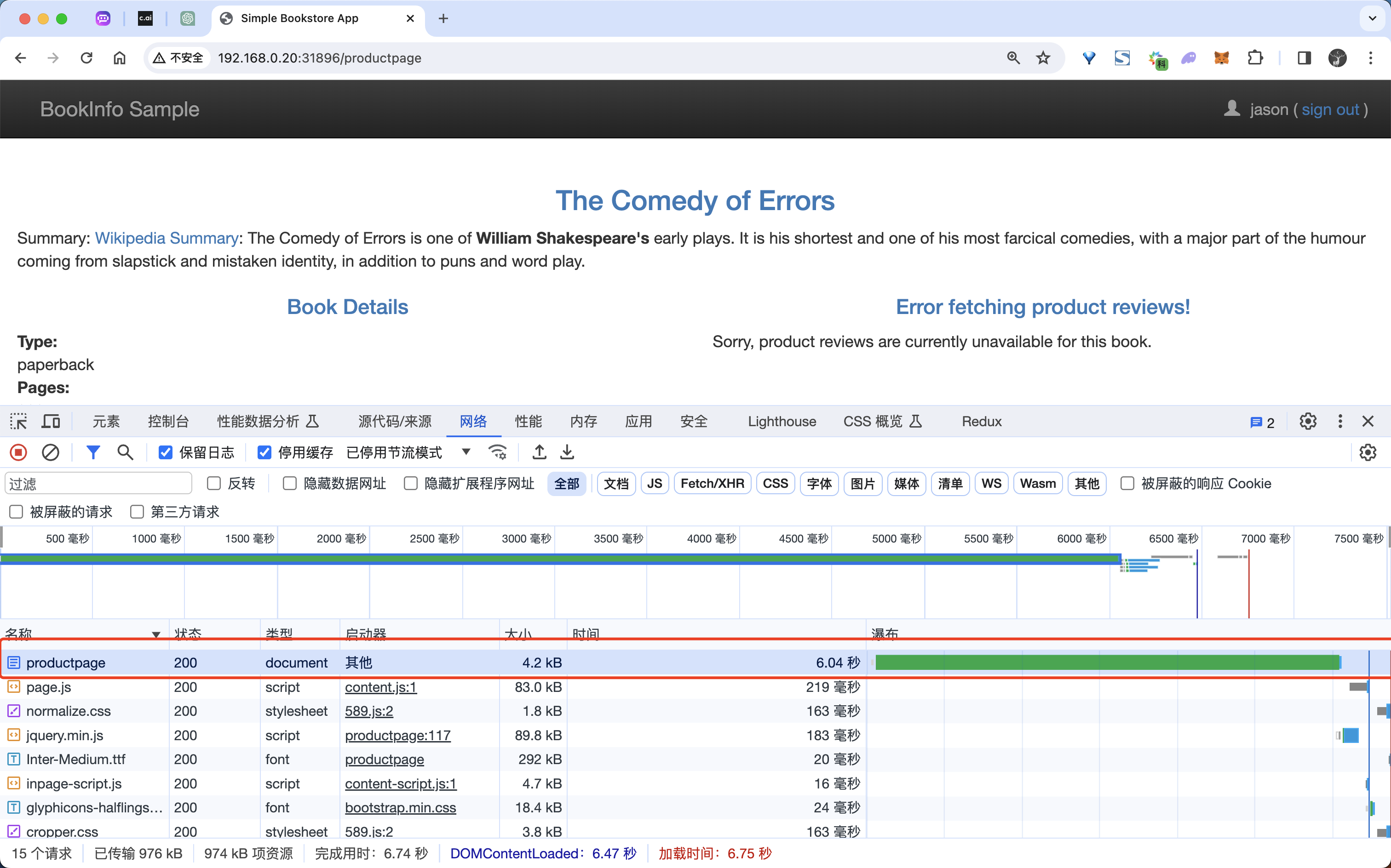
按照预期,我们引入的 7 秒延迟不会影响到 reviews 服务,因为 reviews 和 ratings 服务间的超时被硬编码为 10 秒。但实际上在 productpage 和 reviews 服务之间也有一个 3 秒的硬编码的超时,再加 1 次重试,一共 6 秒。结果 productpage 对 reviews 的调用在 6 秒后提前超时并抛出错误了。
这种类型的错误可能发生在由不同的团队独立开发不同的微服务的场景中。Istio 的故障注入规则可以帮助识别此类异常,而不会影响最终用户。
🍀
那么我们应该如何来修复这个问题呢?这种问题通常可以这样来解决:
- 增加
productpage与reviews服务之间的超时或降低reviews与ratings的超时 - 终止并重启修复后的微服务
- 确认
/productpage页面正常响应且没有任何错误
reviews 服务的 v3 版本实际上已经修复了这个问题。reviews:v3 服务已将 reviews 与 ratings 的超时时间从 10 秒降低为 2.5 秒,因此它可以兼容(小于)下游 productpage 请求的超时时间。
如果您按照流量转移任务所述将所有流量转移到 reviews:v3,可以尝试修改延迟规则为任何低于 2.5 秒的数值,例如 2 秒,然后确认端到端的流程没有任何错误。
🍀
我们这里是为 ratings 服务配置的 VirtualService 规则,而且是 reviews:v2 服务去请求这个服务的,所以我们可以通过 istioctl proxy-config routes 命令来查看 reviews:v2 版本服务对应的 Envoy 路由表配置信息来验证下这个延迟故障:
$ istioctl proxy-config routes reviews-v2-b7dcd98fb-gccfh --name 9080 -oyaml
- name: "9080"
virtualHosts:
# ......
- domains:
- ratings.default.svc.cluster.local
- ratings
- ratings.default.svc
- ratings.default
- 10.101.184.235
includeRequestAttemptCount: true
name: ratings.default.svc.cluster.local:9080
routes:
- decorator:
operation: ratings.default.svc.cluster.local:9080/*
match:
caseSensitive: true
headers:
- name: end-user
stringMatch:
exact: jason
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/ratings
route:
cluster: outbound|9080|v1|ratings.default.svc.cluster.local
# ......
typedPerFilterConfig:
envoy.filters.http.fault:
'@type': type.googleapis.com/envoy.extensions.filters.http.fault.v3.HTTPFault
delay:
fixedDelay: 7s
percentage:
denominator: MILLION
numerator: 1000000
- decorator:
operation: ratings.default.svc.cluster.local:9080/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/ratings
route:
cluster: outbound|9080|v1|ratings.default.svc.cluster.local
# ......
可以看到上面的路由规则中有一个匹配头为 end-user 的规则:
match:
caseSensitive: true
headers:
- name: end-user
stringMatch:
exact: jason
prefix: /
可以看到这个规则中还包含了一个 envoy.filters.http.fault 的配置,这个就是我们前面配置的故障注入规则,可以看到这个规则中的延迟时间为 7 秒,这就是我们前面配置的故障注入规则。
envoy.filters.http.fault:
"@type": type.googleapis.com/envoy.extensions.filters.http.fault.v3.HTTPFault
delay:
fixedDelay: 7s
percentage:
denominator: MILLION
numerator: 1000000
🍀
reviews 服务的 v3 版本实际上已经修复了这个问题。reviews:v3 服务已将 reviews 与 ratings 的超时时间从 10 秒降低为 2.5 秒,因此它可以兼容(小于)下游 productpage 请求的超时时间。
如果您按照流量转移任务所述将所有流量转移到 reviews:v3,可以尝试修改延迟规则为任何低于 2.5 秒的数值,例如 2 秒,然后确认端到端的流程没有任何错误。
编辑文件:
[root@master1 istio-1.19.3]#kubectl get vs
NAME GATEWAYS HOSTS AGE
bookinfo ["bookinfo-gateway"] ["*"] 42m
details ["details"] 40m
productpage ["productpage"] 40m
ratings ["ratings"] 40m
reviews ["reviews"] 40m
[root@master1 istio-1.19.3]#kubectl edit vs reviews
[root@master1 istio-1.19.3]#kubectl edit vs ratings
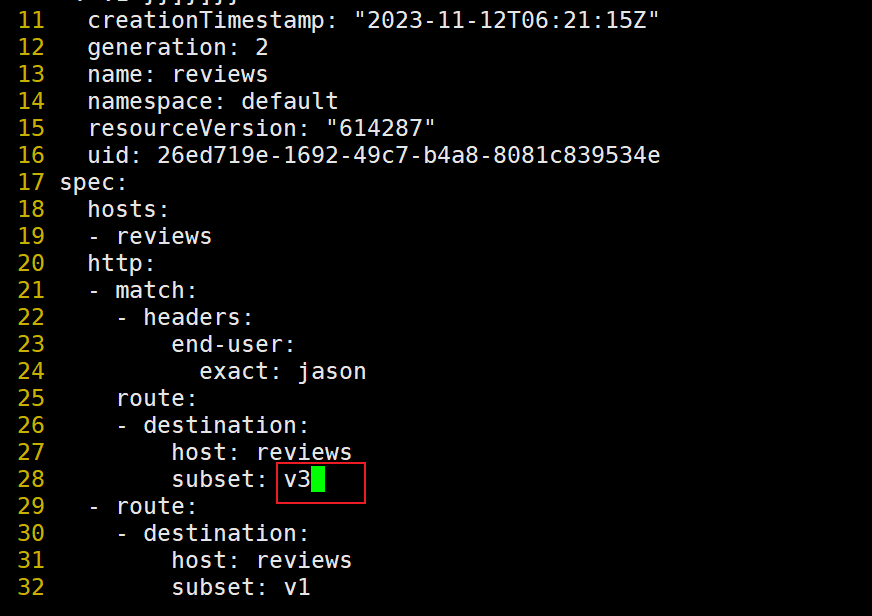
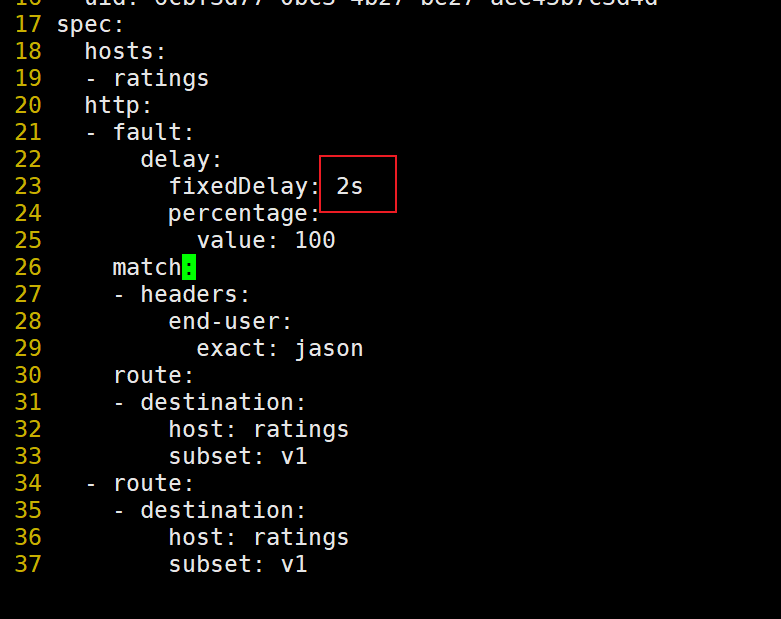
验证:
符合预期,可以看到有2s的延迟。
测试结束。😘
2.注入 HTTP abort 故障
==🚩 实战:注入 HTTP abort 故障-2023.11.12(测试成功)==
测试环境:
本次测试是在前面几次环境基础上传测试的,因此需要先具备前几次测试环境。
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1pMnJxgL63oTlGFlhrfnXsA?pwd=7yqb
提取码:7yqb
2023.11.5-实战:BookInfo 示例应用-2023.11.5(测试成功) --本节测试yaml在此目录里
实验步骤:
graph LR
A[实战步骤] -->B(1️⃣ 更新VirtualService)
A[实战步骤] -->C(2️⃣ 验证)
测试微服务弹性的另一种方法是引入 HTTP abort 故障。这里同样我们针对测试用户 jason,将给 ratings 微服务引入一个 HTTP abort。在这种情况下,我们希望页面能够立即加载,同时显示 Ratings service is currently unavailable 这样的消息。
🍀
为用户 jason 创建一个发送 HTTP abort 的故障注入规则,执行下面的命令即可:
$ kubectl apply -f samples/bookinfo/networking/virtual-service-ratings-test-abort.yaml
这里创建的资源对象如下所示:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: ratings
spec:
hosts:
- ratings
http:
- match:
- headers:
end-user:
exact: jason
fault:
abort:
percentage:
value: 100.0
httpStatus: 500
route:
- destination:
host: ratings
subset: v1
- route:
- destination:
host: ratings
subset: v1
可以看到这里我们是将 fault 下面的 delay 延迟更改成了 abort,并且将 httpStatus 设置为 500,percentage 也设置为了 100,也就是 jason 用户访问 ratings 服务的所有请求都会变成 500 状态码的错误请求,这样我们就可以在页面上看到 Ratings service is currently unavailable 这样的消息了。
🍀
应用上面的规则后,我们可以通过浏览器打开 Bookinfo 应用,以用户 jason 登录到 /productpage 页面,正常就可以看到如下所示的页面:
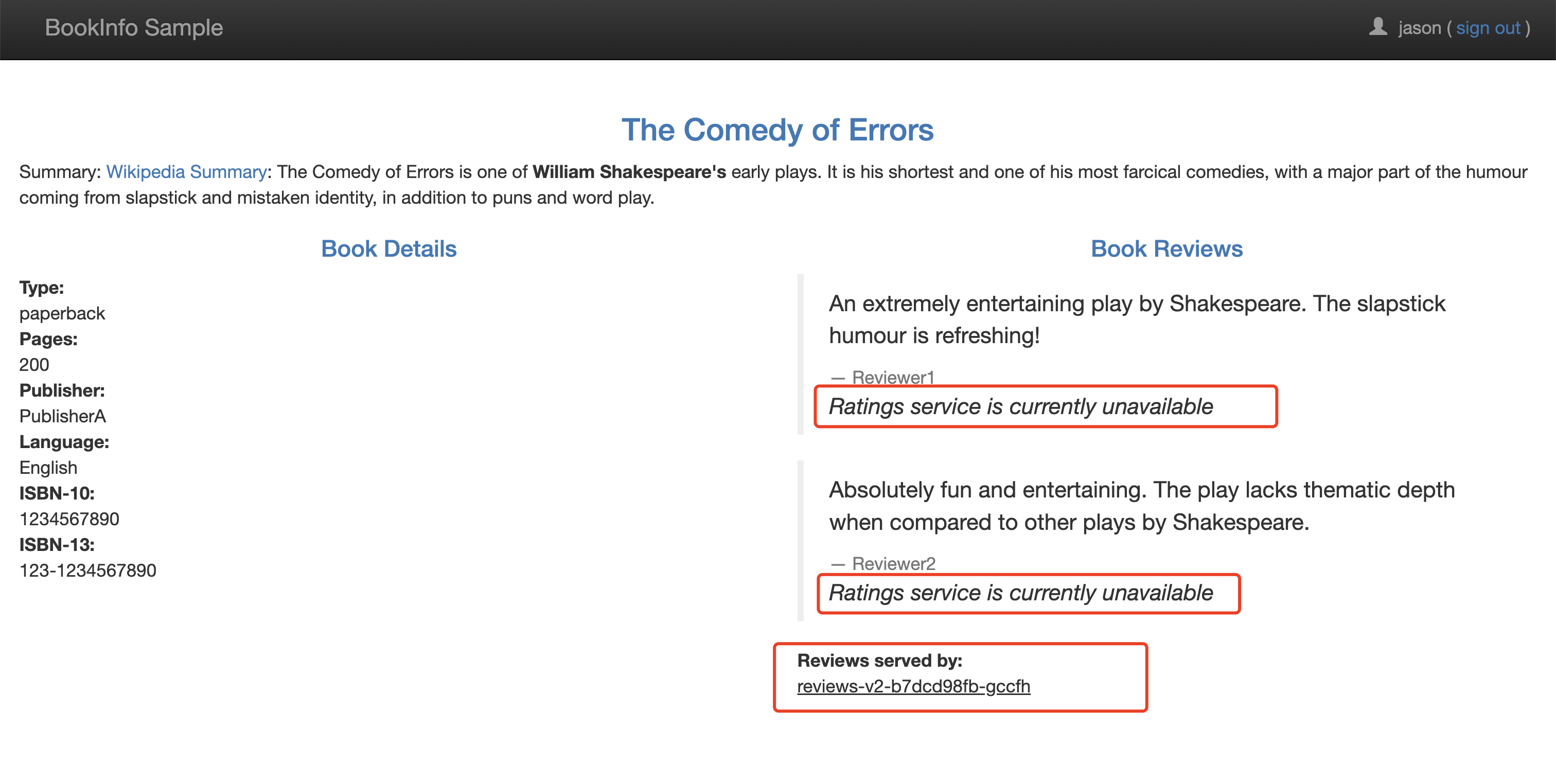
🍀
当然如果注销用户 jason打开 Bookinfo 应用程序,我们会看到 /productpage 为除 jason 以外的其他用户调用了 reviews:v1(完全不调用 ratings),因此不会看到任何错误消息。
同样我们可以去查看下 Envoy 的路由配置,看下这个故障注入规则是如何映射到 Envoy 的路由配置中的:
$ istioctl proxy-config routes reviews-v2-b7dcd98fb-gccfh --name 9080 -oyaml
- name: "9080"
virtualHosts:
# ......
- domains:
- ratings.default.svc.cluster.local
- ratings
- ratings.default.svc
- ratings.default
- 10.101.184.235
includeRequestAttemptCount: true
name: ratings.default.svc.cluster.local:9080
routes:
- decorator:
operation: ratings.default.svc.cluster.local:9080/*
match:
caseSensitive: true
headers:
- name: end-user
stringMatch:
exact: jason
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/ratings
route:
cluster: outbound|9080|v1|ratings.default.svc.cluster.local
# ......
typedPerFilterConfig:
envoy.filters.http.fault:
'@type': type.googleapis.com/envoy.extensions.filters.http.fault.v3.HTTPFault
abort:
httpStatus: 500
percentage:
denominator: MILLION
numerator: 1000000
- decorator:
operation: ratings.default.svc.cluster.local:9080/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/ratings
route:
cluster: outbound|9080|v1|ratings.default.svc.cluster.local
# ......
可以看到上面的路由表中也包含了一个匹配头为 end-user 的规则,同时也包含了一个 envoy.filters.http.fault 的配置,这个就是我们前面配置的故障注入规则,现在这个故障注入配置下面是 abort 了,httpStatus 为 500,这就是我们前面配置的故障注入规则。
🍀
到这里我们就学习了如何通过 VirtualService 对象来实现故障注入的功能,包括延迟请求和请求中断,当然本质上这个功能是通过 Envoy 的 fault 过滤器来实现的。此外我们还可以为 HTTP 请求配置超时,只需要通过路由规则中的 timeout 字段来指定即可,如下所示:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v2
timeout: 0.5s
测试结束。😘
流量拆分
==🚩 实战:流量拆分-2023.11.12(测试成功)==
测试环境:
本次测试是在前面几次环境基础上传测试的,因此需要先具备前几次测试环境。
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1pMnJxgL63oTlGFlhrfnXsA?pwd=7yqb
提取码:7yqb
2023.11.5-实战:BookInfo 示例应用-2023.11.5(测试成功) --本节测试yaml在此目录里
实验步骤:
graph LR
A[实战步骤] -->B(1️⃣ 更新VirtualService)
A[实战步骤] -->C(2️⃣ 验证)
本节我们将了解如何将流量从微�服务的一个版本逐步迁移到另一个版本,比如在 A/B 测试、金丝雀发布等场景中,我们需要将流量从一个版本逐步迁移到另一个版本,这个时候就需要用到流量拆分功能。
这里我们将会把 50% 的流量发送到 reviews:v1,另外,50% 的流量发送到 reviews:v3,接着,再把 100% 的流量发送到 reviews:v3 来完成流量转移。
🍀
首先运行下面的命令将所有流量路由到各个微服务的 v1 版本。
kubectl apply -f samples/bookinfo/networking/virtual-service-all-v1.yaml
kubectl apply -f samples/bookinfo/networking/destination-rule-all.yaml
这是因为前面我们做了其他测试,所以我们需要将流量转移的状态重置一下,这样才能保证我们的测试是正确的。
现在当我们在浏览器中访问 Bookinfo 应用的时候,不管刷新多少次,页面的 Reviews 部分都不会显示带评价星级的内容。这是因为 Istio 被配置为将星级评价的服务的所有流量都路由到了 reviews:v1 版本,而该版本的服务不访问带评价星级的服务,也就是最初的版本。
🍀
接下来我们使用下面的命令把 50% 的流量路由到 reviews:v1,50% 的流量路由到 reviews:v3:
$ kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-50-v3.yaml
该资源清单文件的内容如下所示:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
weight: 50
- destination:
host: reviews
subset: v3
weight: 50
在这个 VirtualService 对象中我们为 reviews 服务的路由规则增加了一个 weight 字段,这个字段的值为 50,表示将 50% 的流量路由到 reviews:v1,另外 50% 的流量路由到 reviews:v3。
🍀
应用该规则后我们可以前往浏览器访问 Bookinfo 应用,刷新 /productpage 页面,大约有 50% 的几率会看到页面中带红色星级的评价内容。
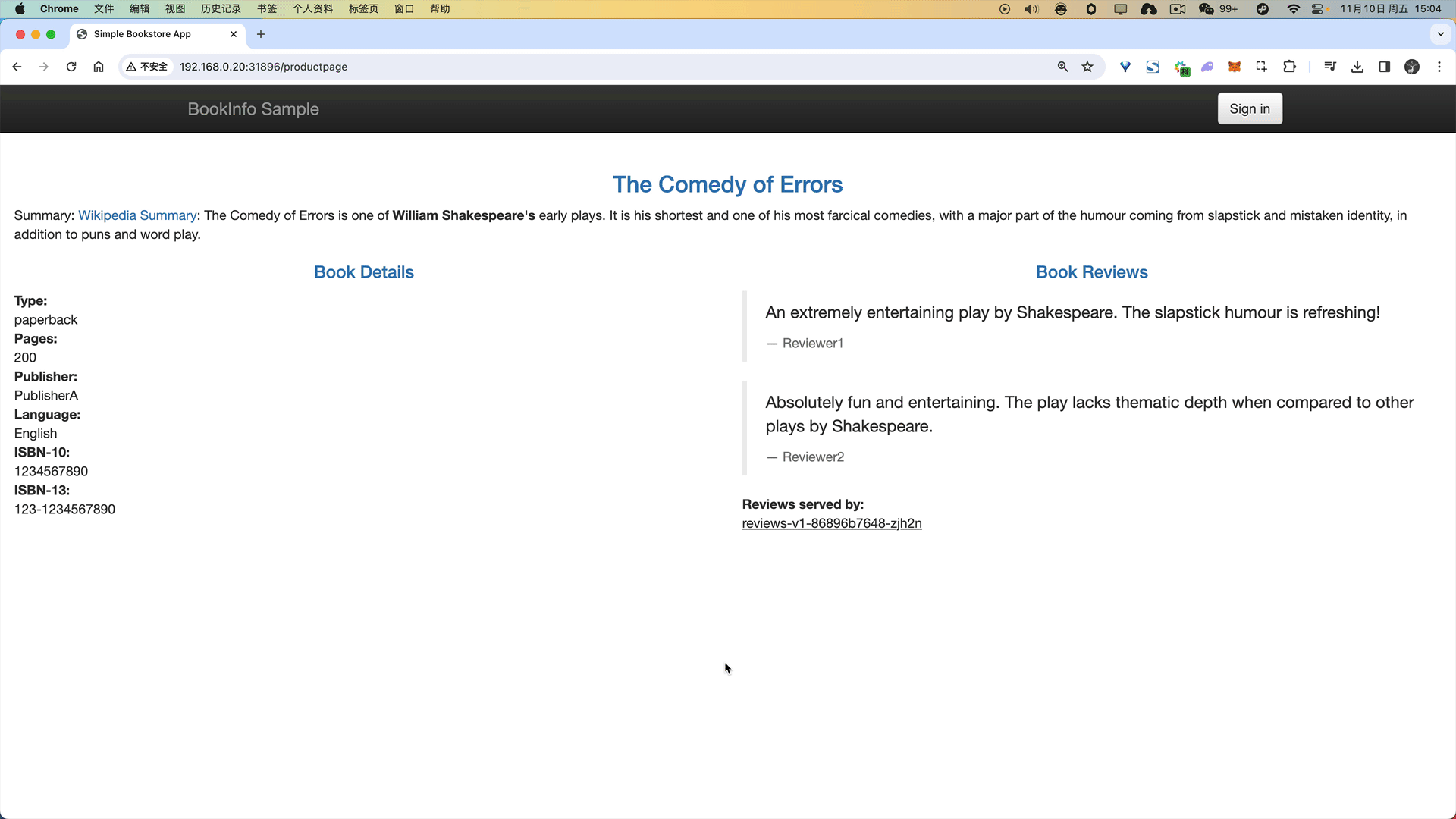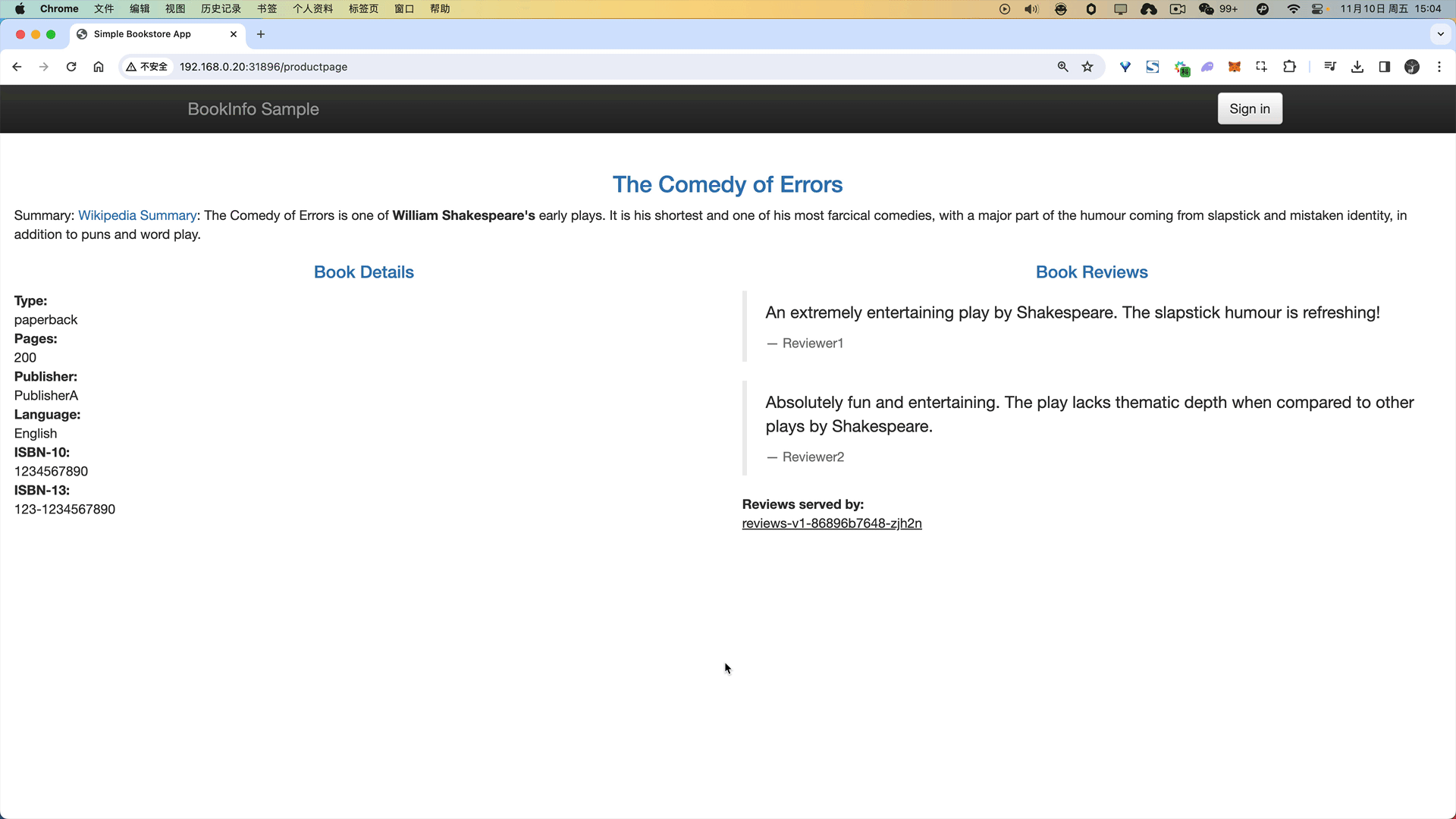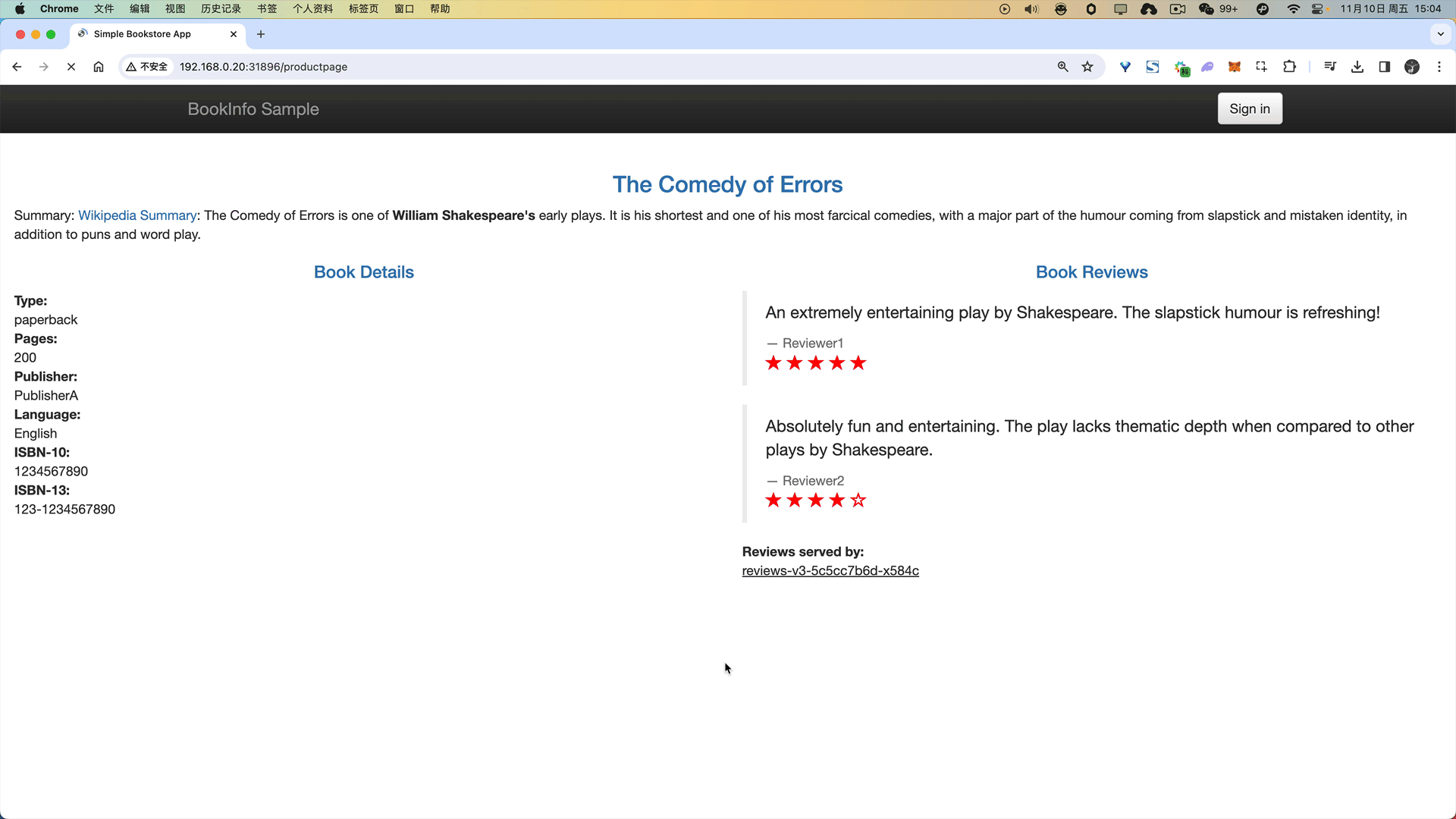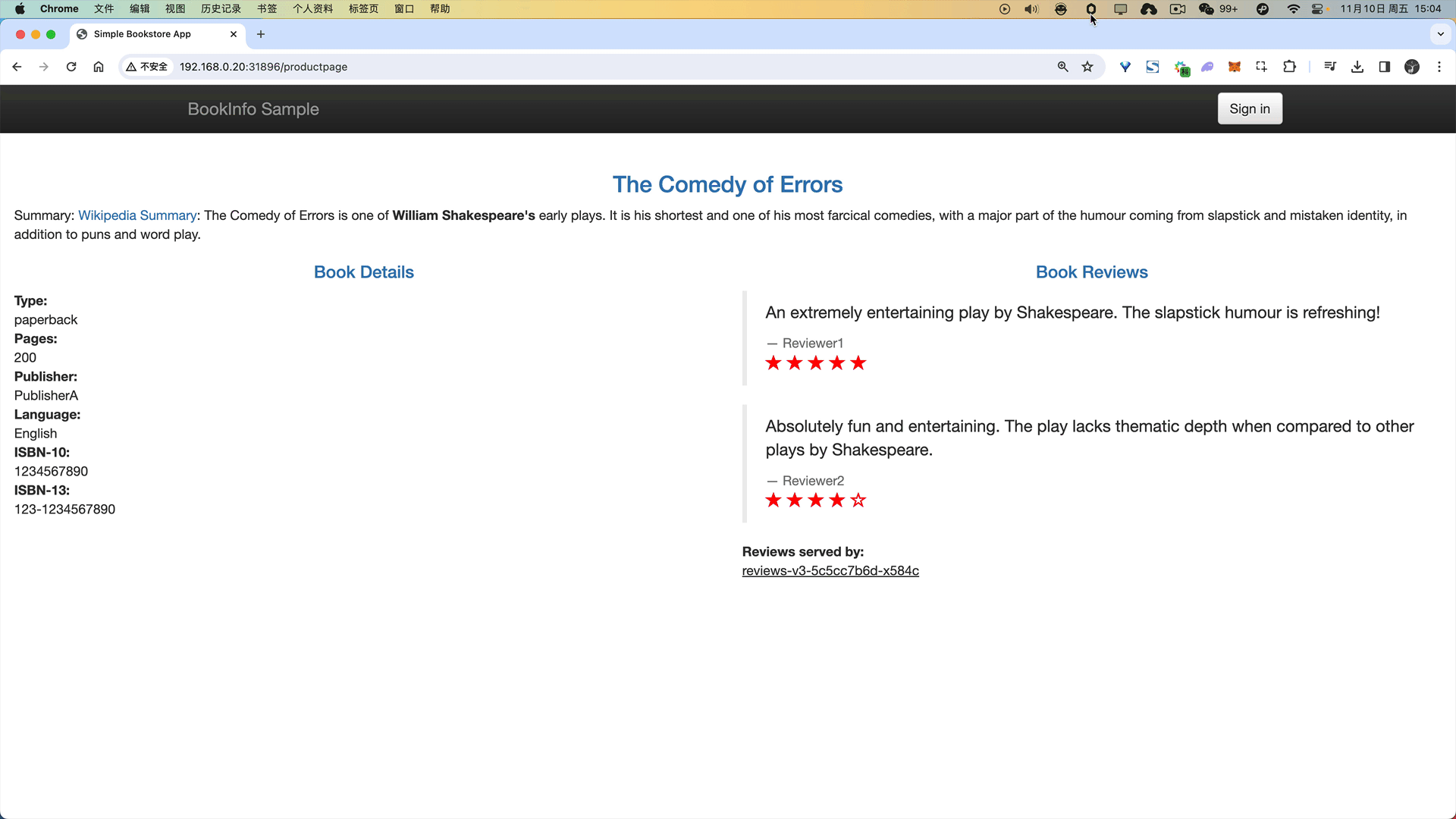
🍀
同样我们可以去查看下 Envoy 的路由配置,看下这个流量转移规则是如何映射到 Envoy 的路由配置中的:
$ istioctl proxy-config routes productpage-v1-564d4686f-wwqqf --name 9080 -oyaml
- name: "9080"
virtualHosts:
- domains:
- reviews.default.svc.cluster.local
- reviews
- reviews.default.svc
- reviews.default
- 10.97.120.56
name: reviews.default.svc.cluster.local:9080
routes:
- decorator:
operation: reviews:9080/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/reviews
route:
weightedClusters:
clusters:
- name: outbound|9080|v1|reviews.default.svc.cluster.local
weight: 50
- name: outbound|9080|v3|reviews.default.svc.cluster.local
weight: 50
# ......
可以看到在 Envoy 的配置路由表中,reviews 服务的路由规则中多了一个 weightedClusters 字段,这个字段就是我们前面配置的基于权重的流量转移规则,其中包含了两个集群,一个是 outbound|9080|v1|reviews.default.svc.cluster.local,另外一个是 outbound|9080|v3|reviews.default.svc.cluster.local,并且两个集群的权重都是 50,这样就实现了将 50% 的流量路由到 reviews:v1,另外 50% 的流量路由到 reviews:v3。
而且这里我们通过 Istio 来实现的流量拆分功能和直接使用 K8s 的部署功能来进行版本迁移完全不同,后者使用了实例扩容来对流量进行管理。使用 Istio,两个版本的
reviews服务可以独立地进行扩容和缩容,而不会影响这两个服务版本之间的流量分发。
🍀
如果 reviews:v3 微服务已经稳定了,那么可以通过应用 VirtualService 规则将 100% 的流量路由到 reviews:v3:
$ cat samples/bookinfo/networking/virtual-service-reviews-v3.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v3
$ kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-v3.yaml
现在,当刷新 /productpage 时,将始终看到带有红色星级评分的评论。
测试结束。😘
流量镜像
流量镜像,也称为影子流量,是一个以尽可能低的风险为生产带来变化的强大的功能,镜像会将实时流量的副本发送到镜像服务,不会对主流量产生影响,这样就可以在不影响生产流量的情况下,对新版本的服务进行测试。
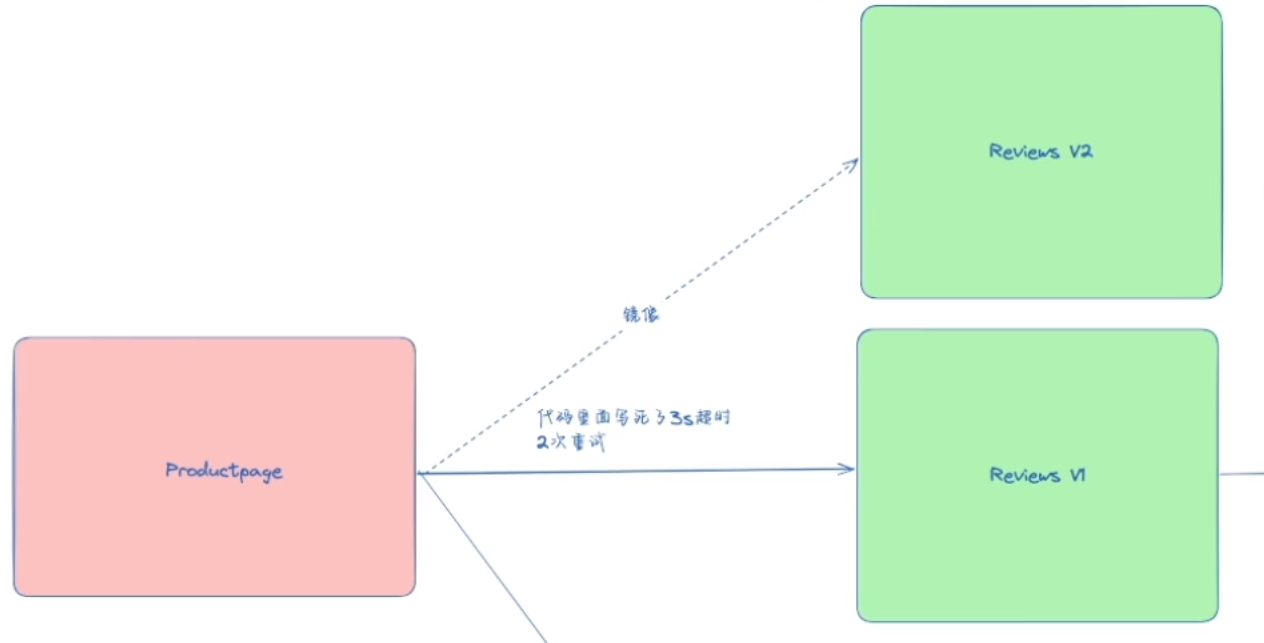
==🚩 实战:流量镜像-2023.11.12(测试成功)==
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1TvCU9yymMXSjVHNQnXnBYw?pwd=uns1
提取码:uns1
2023.11.12-实战:流量镜像-2023.11.12(测试成功)

实验步骤:
graph LR
A[实战步骤] -->B(1️⃣ 部署应用)
A[实战步骤] -->C(2️⃣ 配置VirtualService和DestinationRule)
A[实战步骤] -->D(3️⃣ 验证)
🍀
这里我们将首先把流量全部路由到测试服务的 v1 版本,然后执行规则将一部分流量镜像到 v2 版本。
首先部署两个版本的 Httpbin 服务,并开启访问日志功能:
httpbin-v1:
$ cat <<EOF | istioctl kube-inject -f - | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpbin-v1
spec:
selector:
matchLabels:
app: httpbin
version: v1
template:
metadata:
labels:
app: httpbin
version: v1
spec:
containers:
- image: docker.io/kennethreitz/httpbin
imagePullPolicy: IfNotPresent
name: httpbin
command: ["gunicorn", "--access-logfile", "-", "-b", "0.0.0.0:80", "httpbin:app"]
ports:
- containerPort: 80
EOF
httpbin-v2:
$ cat <<EOF | istioctl kube-inject -f - | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpbin-v2
spec:
selector:
matchLabels:
app: httpbin
version: v2
template:
metadata:
labels:
app: httpbin
version: v2
spec:
containers:
- image: docker.io/kennethreitz/httpbin
imagePullPolicy: IfNotPresent
name: httpbin
command: ["gunicorn", "--access-logfile", "-", "-b", "0.0.0.0:80", "httpbin:app"]
ports:
- containerPort: 80
EOF
httpbin Kubernetes 服务:
$ kubectl create -f - <<EOF
apiVersion: v1
kind: Service
metadata:
name: httpbin
labels:
app: httpbin
spec:
ports:
- name: http
port: 8000
targetPort: 80
selector:
app: httpbin
EOF
🍀
然后启动一个如下所示的 sleep 服务,用来提供 curl 工具进行负载:
$ cat <<EOF | istioctl kube-inject -f - | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep","3650d"]
imagePullPolicy: IfNotPresent
EOF
🍀
创建后的资源对象如下所示:
$ kubectl get pod -l app=sleep
NAME READY STATUS RESTARTS AGE
sleep-6b56495b4c-rxf7j 2/2 Running 0 9s
$ kubectl get pod -l app=httpbin
NAME READY STATUS RESTARTS AGE
httpbin-v1-65665cdc46-l8wfw 2/2 Running 0 2m
httpbin-v2-66f744d46d-l52mb 2/2 Running 0 92s
$ kubectl get svc httpbin
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
httpbin ClusterIP 10.96.247.77 <none> 8000/TCP 102s
🍀
默认情况下,Kubernetes 在 httpbin 服务的两个版本之间进行负载均衡,接下来我们将创建如下所示的规则,把所有流量都路由到 v1 版本。
#mirror.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- httpbin
http:
- route:
- destination:
host: httpbin
subset: v1
weight: 100
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
这里我们先创建一个 DestinationRule 对象,将 httpbin 服务分成 v1 和 v2 两个子集,分别匹配 version=v1 和 version=v2 的 Pod,然后再创建一个 VirtualService 对象,将所有流量都路由到 v1 子集。
[root@master1 ~]#kubectl apply -f mirror.yaml
virtualservice.networking.istio.io/httpbin created
destinationrule.networking.istio.io/httpbin created
🍀
应用上面的资源对象后,现在所有流量都被转到 httpbin:v1 服务,我们可以向此服务发送请求来验证:
$ export SLEEP_POD=$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})
$ kubectl exec "${SLEEP_POD}" -c sleep -- curl -sS http://httpbin:8000/headers
{
"headers": {
"Accept": "*/*",
"Host": "httpbin:8000",
"User-Agent": "curl/7.81.0-DEV",
"X-B3-Parentspanid": "623917d026166bc1",
"X-B3-Sampled": "1",
"X-B3-Spanid": "8ef9bb2eceeceec5",
"X-B3-Traceid": "b586a087a8c2219a623917d026166bc1",
"X-Envoy-Attempt-Count": "1",
"X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/default/sa/default;Hash=4252b9bc6aa8f29690137269e51cd45b9441078c918e30f1380537bc77402b4d;Subject=\"\";URI=spiffe://cluster.local/ns/default/sa/default"
}
}
🍀
然后分别查看 httpbin Pod 的 v1 和 v2 两个版本的日志,可以看到 v1 版本的访问日志条目,而 v2 版本没有日志:
$ export V1_POD=$(kubectl get pod -l app=httpbin,version=v1 -o jsonpath={.items..metadata.name})
$ kubectl logs "$V1_POD" -c httpbin
127.0.0.6 - - [10/Nov/2023:07:38:53 +0000] "GET /headers HTTP/1.1" 200 529 "-" "curl/7.81.0-DEV"
$ export V2_POD=$(kubectl get pod -l app=httpbin,version=v2 -o jsonpath={.items..metadata.name})
$ kubectl logs "$V2_POD" -c httpbin
🍀
接下来我们将创建一个新的规则,将 100% 的流量发送到 v1 版本,但是同样将 100% 的相同流量镜像到 httpbin:v2 服务去:
#mirror2.yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: httpbin
spec:
hosts:
- httpbin
http:
- route:
- destination:
host: httpbin
subset: v1
weight: 100
mirror:
host: httpbin
subset: v2
mirrorPercentage:
value: 100.0
当流量被镜像时,请求将发送到镜像服务中,并在 headers 中的 Host/Authority 属性值上追加 -shadow,例如 cluster-1 变为 cluster-1-shadow。
此外这些被镜像的流量是**『即发即弃』**的,就是说镜像请求的响应会被丢弃,前面在 Envoy 中我们也实验过该特性。
当然我们也可以使用 mirrorPercentage 属性下的 value 字段来设置镜像流量的百分比,而不是镜像所有请求。如果没有这个属性,将镜像所有流量。
🍀
[root@master1 ~]#kubectl apply -f mirror2.yaml
virtualservice.networking.istio.io/httpbin configured
直接应用该规则后,我们可以向 httpbin 服务发送请求来验证:
$ kubectl exec "${SLEEP_POD}" -c sleep -- curl -sS http://httpbin:8000/headers
{
"headers": {
"Accept": "*/*",
"Host": "httpbin:8000",
"User-Agent": "curl/7.81.0-DEV",
"X-B3-Parentspanid": "6bab21955204ba63",
"X-B3-Sampled": "1",
"X-B3-Spanid": "ff009be6e25704dc",
"X-B3-Traceid": "2b52f289d76c3dbc6bab21955204ba63",
"X-Envoy-Attempt-Count": "1",
"X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/default/sa/default;Hash=4252b9bc6aa8f29690137269e51cd45b9441078c918e30f1380537bc77402b4d;Subject=\"\";URI=spiffe://cluster.local/ns/default/sa/default"
}
}
🍀
现在就可以看到 v1 和 v2 版本中都有了访问日志。v2 版本中的访问日志就是由镜像流量产生的,这些请求的实际目标是 v1 版本。
$ kubectl logs "$V1_POD" -c httpbin
127.0.0.6 - - [10/Nov/2023:07:38:53 +0000] "GET /headers HTTP/1.1" 200 529 "-" "curl/7.81.0-DEV"
127.0.0.6 - - [10/Nov/2023:07:52:31 +0000] "GET /headers HTTP/1.1" 200 529 "-" "curl/7.81.0-DEV"
$ kubectl logs "$V2_POD" -c httpbin
127.0.0.6 - - [10/Nov/2023:07:52:31 +0000] "GET /headers HTTP/1.1" 200 569 "-" "curl/7.81.0-DEV"
🍀
同样我们可以去查看下 Envoy 里面的路由表配置来验证下这个流量镜像规则是如何映射到 Envoy 的路由配置中的:
# 8000 端口
$ istioctl proxy-config routes $SLEEP_POD --name 8000 -oyaml
- name: "8000"
virtualHosts:
- domains:
- httpbin.default.svc.cluster.local
- httpbin
- httpbin.default.svc
- httpbin.default
- 10.96.247.77
name: httpbin.default.svc.cluster.local:8000
routes:
- decorator:
operation: httpbin.default.svc.cluster.local:8000/*
match:
prefix: /
metadata:
filterMetadata:
istio:
config: /apis/networking.istio.io/v1alpha3/namespaces/default/virtual-service/httpbin
route:
cluster: outbound|8000|v1|httpbin.default.svc.cluster.local
requestMirrorPolicies:
- cluster: outbound|8000|v2|httpbin.default.svc.cluster.local
runtimeFraction:
defaultValue:
denominator: MILLION
numerator: 1000000
traceSampled: false
# ......
可以看到在 Envoy 的路由表中,httpbin 服务的路由规则中多了一个 requestMirrorPolicies 字段,这个字段就是我们前面配置的流量镜像规则,其中包含了一个集群,就是 outbound|8000|v2|httpbin.default.svc.cluster.local,并且配置的是 100%比例,这样就实现了将 100% 的流量镜像到 httpbin:v2,这其实和前面我们在 Envoy 中去实现的流量镜像功能是一致的。
🍀
最后如果测试后不再需要这些服务可以将其清理:
kubectl delete virtualservice httpbin
kubectl delete destinationrule httpbin
关闭 Httpbin 服务和客户端:
kubectl delete deploy httpbin-v1 httpbin-v2 sleep
kubectl delete svc httpbin
测试结束。😘
熔断
熔断是创建弹性微服务应用程序的重要模式,熔断能够使应用程序具备应对来自故障、潜在峰值和其他未知网络因素影响的能力。服务熔断是应对微服务雪崩效应的一种链路保护机制,类似股市�、保险丝。微服务之间的数据交互是通过远程调用来完成的,服务 A 调用服务 B,服务 B 调用服务 C,某一时间链路上对服务 C 的调用响应时间过长或者服务 C 不可用,随着时间的增长,对服务 C 的调用也越来越多,然后服务 C 崩溃了,但是链路调用还在,对服务 B 的调用也在持续增多,然后服务 B 崩溃,随之 A 也崩溃,导致雪崩效应。
1.熔断概述
服务熔断是应对雪崩效应的一种微服务链路保护机制。例如在高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。同样,在微服务架构中,熔断机制也是起着类似的作用。当调用链路的某个微服务不可用或者响应时间太长时,会进行服务熔断,不再有该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。在 Spring Cloud 框架里,熔断机制通过 Hystrix实现,Hystrix 会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是 5 秒内 20 次调用失败,就会启动熔断机制。
Istio 也有对熔断的支持,无需对代码进行任何更改就可以为应用增加熔断和限流功能。Istio 中熔断和限流在 DestinationRule 的 CRD 资源的 TrafficPolicy 中设置,一般设置连接池(ConnectionPool)限流方式和异常检测(outlierDetection)熔断方式。两者各自配置部分参数,其中参数有可能存在对方的功能,并没有很严格的区分出来,如主要进行限流设置的 ConnectionPool 中的 maxPendingRequests 参数,最大等待请求数,如果超过则也会暂时的熔断。
连接池(ConnectionPool)设置
ConnectionPool 可以对上游服务的并发连接数和请求数进行限制,适用于 TCP 和 HTTP,所以 ConnectionPool 又称之为限流。

我们可以在 DestinationRule 中配置连接池:
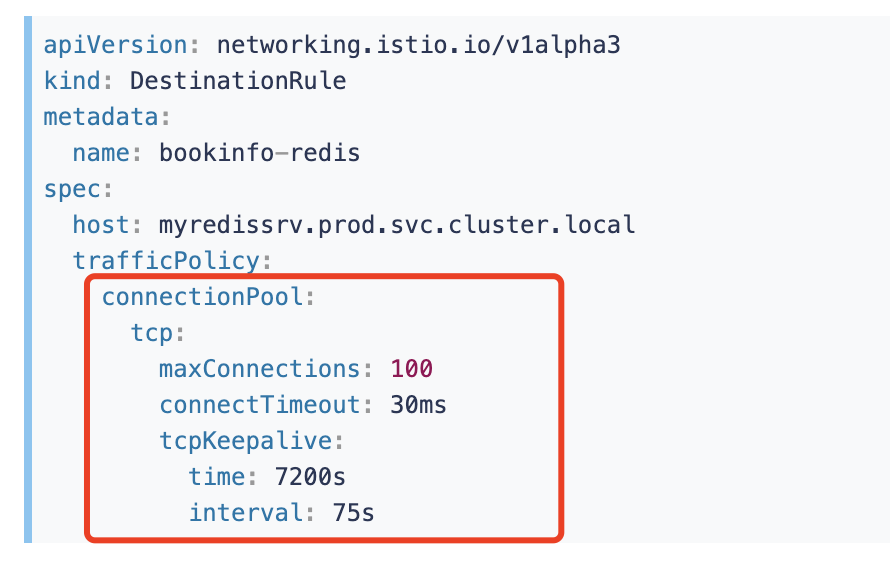
TCP 连接池设置 http 和 tcp 上游连接的设置。
tcp 相关参数设置如下:

-
maxConnections:到目标主机的 HTTP1/TCP 最大连接数量,只作用于 http1.1,不作用于 http2,因为后者只建立一次连接。 -
connectTimeout:TCP 连接超时时间,默认单位秒。也可以写其他单位,如 ms。 -
tcpKeepalive:如果在套接字上设置SO_KEEPALIVE可以确保 TCP Keepalive。TCP 的 TcpKeepalive 设置: -
Probes:在确定连接已死之前,在没有响应的情况下发送的 keepalive 探测的最大数量。默认值是使用系统级别的配置(Linux 默认值为 9)。 -
Time:发送 keep-alive 探测前连接存在的空闲时间。默认值是使用系统的配置(Linux 默认值为 7200s,即 2 小�时。 -
interval:探测活动之间的时间间隔。默认值是使用系统的配置(Linux 默认值为 75 秒)。
http 相关参数配置如下:
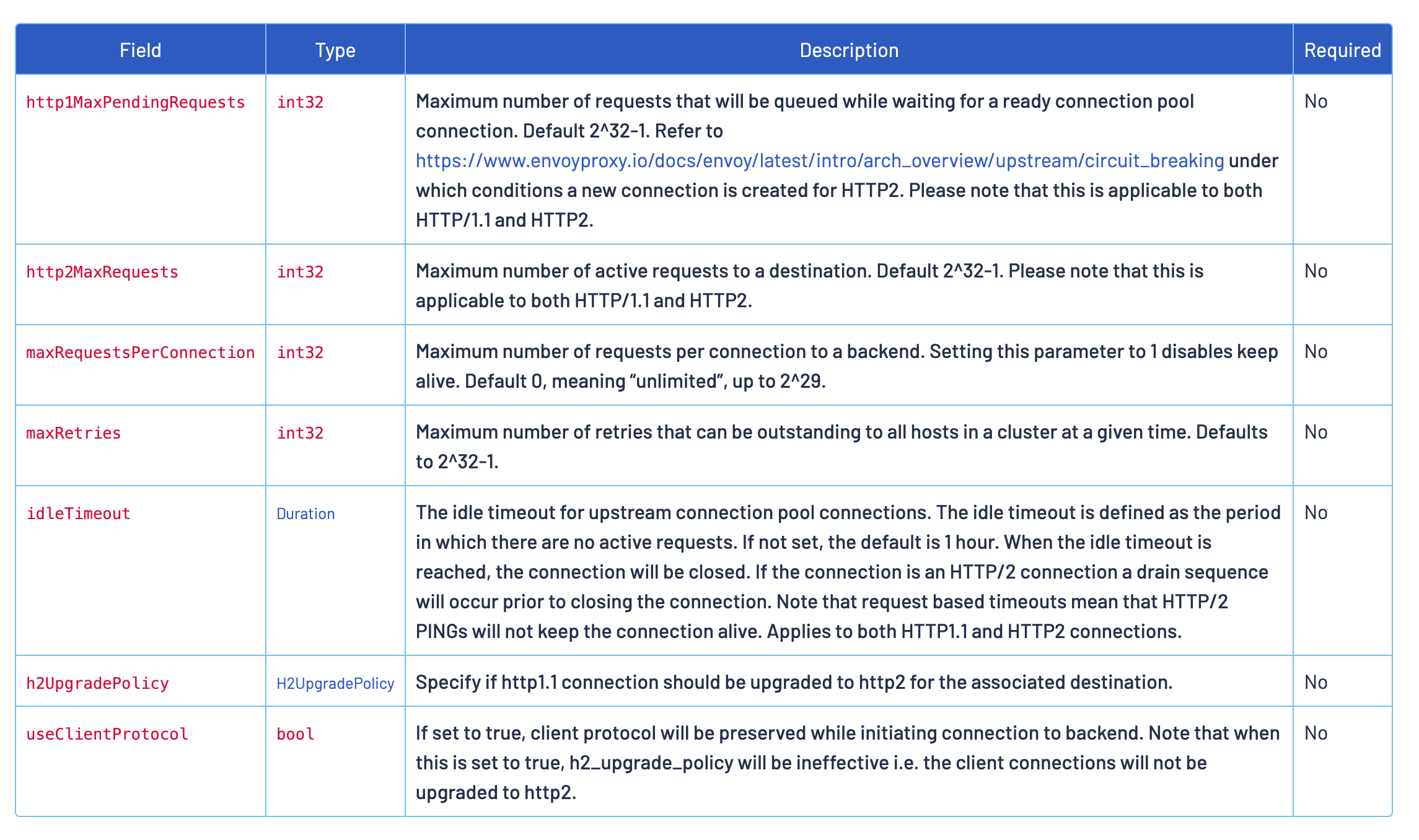
http 连接池设置用于 http1.1/HTTP2/GRPC 连接。
http1MaxPendingRequests:http 请求 pending 状态的最大请求数,从应用容器发来的 HTTP 请求的最大等待转发数,默认是2^32-1。http2MaxRequests:后端请求的最大数量,默认是2^32-1。maxRequestsPerConnection:在一定时间内限制对后端服务发起的最大请求数,如果超过了这个限制,就会开启限流。如果将这一参数设置为 1 则会禁止 keepalive 特性;idleTimeout:上游连接池连接的空闲超时。空闲超时被定义为没有活动请求的时间段。如果未设置,则没有空闲超时。当达到空闲超时时,连接将被关闭。注意,基于请求的超时意味着 HTTP/2ping 将无法保持有效连接。适用于 HTTP1.1 和 HTTP2 连接;maxRetries:在给定时间内,集群中所有主机都可以执行的最大重试次数。默认为 3。
异常检测(outlierDetection)
熔断策略对集群中压力过大的上游服务起到一定的保护作用,有一种情况是集群中的某些节点完全崩溃,这种情况我们并不知晓。istio 引入了异常检测来完成熔断的功能,通过周期性动态的异常检测来确定上游集群中的某些主机是否异常,如果发现异常,就将该主机从连接池中隔离出去,这就是异常检测。也是一种熔断的实现,用于跟踪上游服务的状态。适用于 HTTP 和 TCP 服务。对于 HTTP 服务,API 调用连续返回 5xx 错误,则在一定时间内连接池拒绝此服务。对于 TCP 服务,一个主机连接超时次数或者连接失败次数达到一定次数时就认为是连接错误。
异常检测的原理:
- 检测到了某个主机异常
- 如果到目前为止负载均衡池中还没有主机被隔离出去,将会立即隔离该异常主机;如果已经有主机被隔离出去,就会检查当前隔离的主机数是否低于设定的阈值(通过 envoy 中的
outlier_detection.max_ejection_percent指定),如果当前被隔离的主机数量不超过该阈值,就将该主机隔离出去,否则不隔离 - 隔离不是永久的,会有一个时间限制。当主机被隔离后,该主机就会被标记为不健康,并且不会被加入到负载均衡池中,除非负载均衡处于恐慌模式。隔离时间等于 envoy 中的
outlier_detection.base_ejection_time_ms的值乘以主机被隔离的次数。所以如果某个主机连续出现故障,会导致它被隔离的时间越来越长。 - 经过了规定的隔离时间之后,被隔离的主机将会自动恢复过来,重新接受调用方的远程调用。通常异常检测会与主动健康检查一起用于全面的健康检查解决方案。
异常检测类型:
连续 5xx 响应:如果上游主机连续返回一定数量的 5xx 响应,该主机就会被驱逐。这里的 5xx 响应不仅包括返回的 5xx 状态码,也包括 HTTP 路由返回的事件(如连接超时和连接错误)。隔离主机所需的 5xx 响应数量由consecutive_5xx的值控制。连续网关故障:如果上游主机连续返回一定数量的gatewayerrors( 502、503 或 504 状态码),该主机就会被驱逐。这里同样也包括 HTTP 路由返回的一个事件(如连接超时和连接错误)。隔离主机所需的连续网关故障数量由consecutive_gateway_failure的值控制。调用成功率:基于调用成功率的异常检测类型会聚合集群中每个主机的调用成功率,然后根据统计的数据以给定的周期来隔离主机。如果该主机的请求数量小于success_rate_request_volume指定的值,则不会为该主机计算调用成功率,因此聚合的统计数据中不会包括该主机的调用成功率。如果在给定的周期内具有最小所需请求量的主机数小于success_rate_minimum_hosts指定的值,则不会对该集群执行调用成功率检测。
我们可以在 DestinationRule 中配置异常检测:
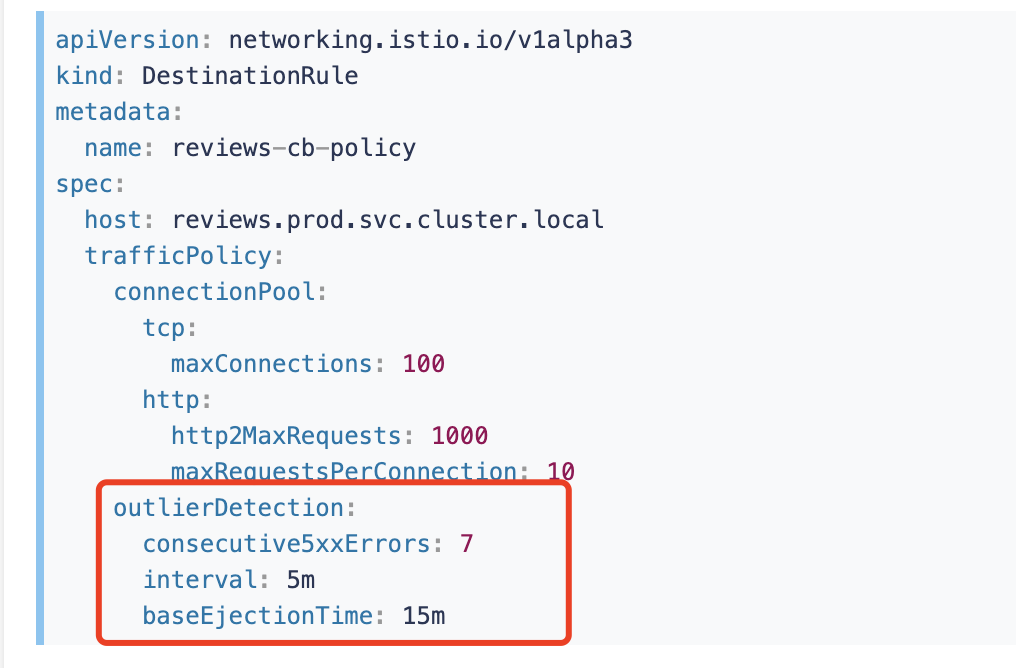
consecutiveErrors:从连接池开始拒绝连接,已经连接失败的次数。当通过 HTTP 访问时,返回代码是 502、503 或 504 则视为错误。当访问不透明的 TCP 连接时,连接超时和连接错误/失败也会都视为错误。即将实例从负载均衡池中剔除,需要连续的错误(HTTP5XX 或者 TCP 断开/超时)次数。默认是 5。interval:拒绝访问扫描的时间间隔,即在 interval 内连续发生 1 个consecutiveErrors错误,则触发服务熔断,格式是 1h/1m/1s/1ms,但必须大于等于 1ms。即分析是否需要剔除的频率,多久分析一次,默认 10 秒。baseEjectionTime:最短拒绝访问时长,这个时间主机将保持拒绝访问,且如果拒绝访问达到一定的次数。这允许自动增加不健康服务的拒绝访问时间,时间为baseEjectionTime*驱逐次数。格式:1h/1m/1s/1ms,但必须大于等于 1ms。实例被剔除后,至少多久不得返回负载均衡池,默认是 30 秒。maxEjectionPercent:服务在负载均衡池中被拒绝访问(被移除)的最大百分比,负载均衡池中最多有多大比例被剔除,默认是 10%。
上面例子是设置 TCP 的连接池大小为 100 个连接,可以有 1000 个并发 HTTP2 请求,reviews 服务的请求连接比不大于 10。此外,配置拒绝访问的时间间隔是 5 分钟,同时,任何连续 7 次返回 5XX 码的主机,将会拒绝访问 15 分钟。
2.熔断示例
下面我们将来演示如何为连接、请求以及异常检测配置熔断。
==🚩 实战:熔断示例-2023.11.13(测试成功)==
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1pMnJxgL63oTlGFlhrfnXsA?pwd=7yqb
提取码:7yqb
2023.11.5-实战:BookInfo 示例应用-2023.11.5(测试成功) --本节测试yaml在此目录里
实验步骤:
graph LR
A[实战步骤] -->B(1️⃣ 部署应用)
A[实战步骤] -->C(2️⃣ 配置熔断)
A[实战步骤] -->D(3️⃣ 验证)
🍀
首先启动一个 Httpbin 示例服务,如果您启用了 Sidecar 自动注入,通过以下命令部署 httpbin 服务:
$ kubectl apply -f samples/httpbin/httpbin.yaml
否则,必须在部署 httpbin 应用程序前进行手动注入:
$ kubectl apply -f <(istioctl kube-inject -f samples/httpbin/httpbin.yaml)
🍀
应用部署完成后首先我们需要创建一个 DestinationRule 对象,用来在调用 httpbin 服务时应用熔断设置:
$ kubectl apply -f - <<EOF
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: httpbin
spec:
host: httpbin
trafficPolicy:
connectionPool:
tcp:
maxConnections: 1 # 最大连接数
http:
http1MaxPendingRequests: 1 # 最大挂起请求数
maxRequestsPerConnection: 1 # 每个连接到后端的最大请求数
outlierDetection:
consecutive5xxErrors: 1 # host从连接池中被拒绝之前的连续 5xx 错误数
interval: 1s # 检测间隔
baseEjectionTime: 3m # 基础驱逐时间
maxEjectionPercent: 100 # 最大驱逐百分比
EOF
这里我们在 httpbin 服务的 DestinationRule 对象中配置了 trafficPolicy 字段,用来配置熔断限流的相关参数。
这些参数的具体含义可以参考官方文档。
🍀
我们说了 DestinationRule 对象其实就是配置 Envoy 里面的 Cluster 集群,那么我们可以通过 istioctl proxy-config cluster 命令来查看下 httpbin 服务的 Cluster 集群配置信息:
$ istioctl proxy-config cluster httpbin-86869bccff-pkks7 --fqdn httpbin.default.svc.cluster.local -o yaml
- circuitBreakers:
thresholds:
- maxConnections: 1
maxPendingRequests: 1
maxRequests: 4294967295
maxRetries: 4294967295
trackRemaining: true
connectTimeout: 10s
edsClusterConfig:
edsConfig:
ads: {}
initialFetchTimeout: 0s
resourceApiVersion: V3
serviceName: outbound|8000||httpbin.default.svc.cluster.local
lbPolicy: LEAST_REQUEST
name: outbound|8000||httpbin.default.svc.cluster.local
outlierDetection:
baseEjectionTime: 180s
consecutive5xx: 1
enforcingConsecutive5xx: 100
enforcingSuccessRate: 0
interval: 1s
maxEjectionPercent: 100
type: EDS
可以看到上面的配置中包含了我们前面配置的熔断参数,这些参数都是 Envoy 的 Cluster 集群的配置参数,比如 circuitBreakers、outlierDetection 等参数,也和我们前面在 DestinationRule 对象中配置的参数是一致的。
🍀
接下来我们创建一个 Fortio 的客户端程序来发送流量到 httpbin 服务,**Fortio 是一个开源的 HTTP 负载测试工具,它可以控制连接数、并发数及发送 HTTP 请求的延迟。**通过 Fortio 能够有效的触发前面在 DestinationRule 中设置的熔断策略。
$ kubectl apply -f <(istioctl kube-inject -f samples/httpbin/sample-client/fortio-deploy.yaml)
$ kubectl get pods -l app=fortio
NAME READY STATUS RESTARTS AGE
fortio-deploy-5cd456bbdb-5xjrz 2/2 Running 0 39s
🍀
创建成功后我们可以登入 Fortio 客户端 Pod,然后使用 Fortio 工具调用 httpbin 服务:
$ export FORTIO_POD=$(kubectl get pods -l app=fortio -o 'jsonpath={.items[0].metadata.name}')
# c=1 表示并发数为 1,n=20 表示总请求数为 20
$ kubectl exec "$FORTIO_POD" -c fortio -- /usr/bin/fortio load -c 1 -qps 0 -n 20 -loglevel Warning http://httpbin:8000/get
# ......
Code 200 : 20 (100.0 %)
Response Header Sizes : count 20 avg 230 +/- 0 min 230 max 230 sum 4600
Response Body/Total Sizes : count 20 avg 824 +/- 0 min 824 max 824 sum 16480
All done 20 calls (plus 0 warmup) 3.399 ms avg, 294.1 qps
可以看出总共发送了 20 个 HTTP 连接,也就是 20 个请求,响应码均为 200。接下来我们就可以测试熔断功能了。
[root@master1 istio-1.19.3]#kubectl exec "$FORTIO_POD" -c fortio -- /usr/bin/fortio load -c 1 -qps 0 -n 20 -loglevel Warning http://httpbin:8000/get
22:23:10 I logger.go:127> Log level is now 3 Warning (was 2 Info)
Fortio 1.17.1 running at 0 queries per second, 2->2 procs, for 20 calls: http://httpbin:8000/get
Starting at max qps with 1 thread(s) [gomax 2] for exactly 20 calls (20 per thread + 0)
Ended after 109.05115ms : 20 calls. qps=183.4
Aggregated Function Time : count 20 avg 0.0054483557 +/- 0.006368 min 0.002985644 max 0.03283692 sum 0.108967113
# range, mid point, percentile, count
>= 0.00298564 <= 0.003 , 0.00299282 , 5.00, 1
> 0.003 <= 0.004 , 0.0035 , 65.00, 12
> 0.004 <= 0.005 , 0.0045 , 85.00, 4
> 0.006 <= 0.007 , 0.0065 , 90.00, 1
> 0.007 <= 0.008 , 0.0075 , 95.00, 1
> 0.03 <= 0.0328369 , 0.0314185 , 100.00, 1
# target 50% 0.00375
# target 75% 0.0045
# target 90% 0.007
# target 99% 0.0322695
# target 99.9% 0.0327802
Sockets used: 1 (for perfect keepalive, would be 1)
Jitter: false
Code 200 : 20 (100.0 %)
Response Header Sizes : count 20 avg 230.05 +/- 0.2179 min 230 max 231 sum 4601
Response Body/Total Sizes : count 20 avg 824.05 +/- 0.2179 min 824 max 825 sum 16481
All done 20 calls (plus 0 warmup) 5.448 ms avg, 183.4 qps
[root@master1 istio-1.19.3]#
在 DestinationRule 配置中,我们定义了 maxConnections: 1 和 http1MaxPendingRequests: 1,表示如果并发的连接和请求数超过一个,在 istio-proxy 进行进一步的请求和连接时,后续请求或连接将被阻止。
🍀
这里我们来发送并发数为 2 的连接(-c 2),请求 20 次(-n 20):
$ kubectl exec "$FORTIO_POD" -c fortio -- /usr/bin/fortio load -c 2 -qps 0 -n 20 -loglevel Warning http://httpbin:8000/get
# ......
Code 200 : 16 (80.0 %)
Code 503 : 4 (20.0 %)
Response Header Sizes : count 20 avg 184.15 +/- 92.08 min 0 max 231 sum 3683
Response Body/Total Sizes : count 20 avg 707.55 +/- 233.3 min 241 max 825 sum 14151
All done 20 calls (plus 0 warmup) 11.073 ms avg, 178.6 qps
可以看到总共发送了 20 个 HTTP 连接,其中 16 个请求成功,4 个请求被熔断了,响应码为 503。
🍀
可以通过查看 istio-proxy 状态来验证:
$ kubectl exec "$FORTIO_POD" -c istio-proxy -- pilot-agent request GET stats | grep httpbin | grep pending
cluster.outbound|8000||httpbin.default.svc.cluster.local.circuit_breakers.default.remaining_pending: 1
cluster.outbound|8000||httpbin.default.svc.cluster.local.circuit_breakers.default.rq_pending_open: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.circuit_breakers.high.rq_pending_open: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_active: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_failure_eject: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_overflow: 4
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_total: 36
其中 upstream_rq_pending_overflow 的值为 4,表明 maxConnections 断路器起作用了。istio-proxy 允许一定的冗余,我们可以将线程数提高到 3,限流的效果会更明显。通过限制待处理请求队列的长度,可以对恶意请求、DoS 和系统中的级联错误起到一定的缓解作用。
🍀
我们将并发连接数提高到 3 个:
$ kubectl exec "$FORTIO_POD" -c fortio -- /usr/bin/fortio load -c 3 -qps 0 -n 30 -loglevel Warning http://httpbin:8000/get
# ......
Code 200 : 8 (26.7 %)
Code 503 : 22 (73.3 %)
Response Header Sizes : count 30 avg 61.5 +/- 102 min 0 max 231 sum 1845
Response Body/Total Sizes : count 30 avg 396.63333 +/- 258.1 min 241 max 825 sum 11899
All done 30 calls (plus 0 warmup) 12.773 ms avg, 208.3 qps
现在可以看到只有 26.7 % 的请求成功,其余的均被熔断器拦截了:
$ kubectl exec "$FORTIO_POD" -c istio-proxy -- pilot-agent request GET stats | grep httpbin | grep pending
cluster.outbound|8000||httpbin.default.svc.cluster.local.circuit_breakers.default.remaining_pending: 1
cluster.outbound|8000||httpbin.default.svc.cluster.local.circuit_breakers.default.rq_pending_open: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.circuit_breakers.high.rq_pending_open: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_active: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_failure_eject: 0
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_overflow: 26
cluster.outbound|8000||httpbin.default.svc.cluster.local.upstream_rq_pending_total: 44
可以看到 upstream_rq_pending_overflow 值 为 26,这意味着,目前为止已有 26 个调用被标记为熔断了。
测试结束。😘
TCP 流量拆分
==🚩 实战:TCP 流量拆分-2023.11.15(测试成功)==
实验环境:
k8s v1.27.6(containerd://1.6.20)(cni:flannel:v0.22.2)
[root@master1 ~]#istioctl version
client version: 1.19.3
control plane version: 1.19.3
data plane version: 1.19.3 (8 proxies)
实验软件:
链接:https://pan.baidu.com/s/1pMnJxgL63oTlGFlhrfnXsA?pwd=7yqb
提取码:7yqb
2023.11.5-实战:BookInfo 示例应用-2023.11.5(测试成功) --本节测试yaml在此目录里

实验步骤:
graph LR
A[实战步骤] -->B(1、 部署应用)
A[实战步骤] -->C(2、 创建Gatewy,vs,rs)
A[实战步骤] -->D(3、 配置TCP 流量拆分)
A[实战步骤] -->E(4、 验证)
前面我们试验了 HTTP 的流量拆分,那么 TCP 流量拆分如何实现呢?TCP 流量拆分是指将来自客户端的 TCP 流量分发到多个后端服务的过程。在 Istio 中,TCP 流量拆分是通过 VirtualService 和 DestinationRule 对象来实现的。
这里我们来演示如何将 TCP 流量从微服务的一个版本迁移到另一个版本。我们将会把 100% 的 TCP 流量分配到 tcp-echo:v1,接着,再通过配置 Istio 路由权重把 20% 的 TCP 流量分配到 tcp-echo:v2。
- 首先部署
tcp-echo服务的v1和v2两个版本:
kubectl apply -f samples/tcp-echo/tcp-echo-services.yaml
查看:
[root@master1 istio-1.19.3]#kubectl get po -l app=tcp-echo
NAME READY STATUS RESTARTS AGE
tcp-echo-v1-64c9b4bc95-hc5z7 2/2 Running 0 69s
tcp-echo-v2-5b5657b486-dlsqf 2/2 Running 0 69s
[root@master1 istio-1.19.3]#kubectl get svc tcp-echo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tcp-echo ClusterIP 10.99.200.47 <none> 9000/TCP,9001/TCP 71s
该资源对象中包含 tcp-echo 的两个 Deployment 对象,包含 9000、9001、9002 三个端口,但是通过 Service 只暴露了 9000 和 9001 两个端口,省略了 9002 端口是为了测试透传能力,内容如下所示:
apiVersion: v1
kind: Service
metadata:
name: tcp-echo
labels:
app: tcp-echo
service: tcp-echo
spec:
ports:
- name: tcp
port: 9000
- name: tcp-other
port: 9001
# Port 9002 is omitted intentionally for testing the pass through filter chain.
selector:
app: tcp-echo
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tcp-echo-v1
labels:
app: tcp-echo
version: v1
spec:
selector:
matchLabels:
app: tcp-echo
version: v1
template:
metadata:
labels:
app: tcp-echo
version: v1
spec:
containers:
- name: tcp-echo
image: docker.io/istio/tcp-echo-server:1.2
imagePullPolicy: IfNotPresent
args: ["9000,9001,9002", "one"]
ports:
- containerPort: 9000
- containerPort: 9001
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tcp-echo-v2
labels:
app: tcp-echo
version: v2
spec:
selector:
matchLabels:
app: tcp-echo
version: v2
template:
metadata:
labels:
app: tcp-echo
version: v2
spec:
containers:
- name: tcp-echo
image: docker.io/istio/tcp-echo-server:1.2
imagePullPolicy: IfNotPresent
args: ["9000,9001,9002", "two"]
ports:
- containerPort: 9000
- containerPort: 9001
- 然后同样再部署一个 sleep 示例应用,作为发送请求的测试源:
kubectl apply -f samples/sleep/sleep.yaml
对应的 Pod 如下所示:
[root@master1 istio-1.19.3]#kubectl get pods
NAME READY STATUS RESTARTS AGE
……
sleep-9454cc476-nx668 2/2 Running 0 11s
tcp-echo-v1-64c9b4bc95-hc5z7 2/2 Running 0 27m
tcp-echo-v2-5b5657b486-dlsqf 2/2 Running 0 27m
- 接下来我们将所有 TCP 流量路由到微服务
tcp-echo的v1版本,应用下面的资源清单即可:
$ kubectl apply -f samples/tcp-echo/tcp-echo-all-v1.yaml
查看:
[root@master1 istio-1.19.3]#kubectl get gateway
NAME AGE
bookinfo-gateway 2d16h
tcp-echo-gateway 41s
[root@master1 istio-1.19.3]#kubectl get vs
NAME GATEWAYS HOSTS AGE
bookinfo ["bookinfo-gateway"] ["*"] 2d16h
……
tcp-echo ["tcp-echo-gateway"] ["*"] 46s
[root@master1 istio-1.19.3]#kubectl get dr
NAME HOST AGE
tcp-echo-destination tcp-echo 57s
该资源对象中包含了 tcp-echo 服务的 Gateway、DestinationRule 和 VirtualService 对象,内容如下所示:
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: tcp-echo-gateway
spec:
selector:
istio: ingressgateway
servers:
- port:
number: 31400 # istio-ingressgateway 包含该端口
name: tcp
protocol: TCP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: tcp-echo-destination
spec:
host: tcp-echo
subsets:
- name: v1
labels:
version: v1 # 匹配 tcp-echo-v1 的标签
- name: v2
labels:
version: v2 # 匹配 tcp-echo-v2 的标签
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: tcp-echo
spec:
hosts:
- "*"
gateways:
- tcp-echo-gateway # 关联上面的 Gateway
tcp:
- match:
- port: 31400 # 匹配上面 Gateway 的端口
route:
- destination: # 路由导 tcp-echo 服务
host: tcp-echo
port:
number: 9000
subset: v1 # 全部路由到 v1 子集
上面的资源清单中单独定义了一个 Gateway 对象,用来暴露 TCP 流量的端口,然后通过 VirtualService 对象将 TCP 流量路由到 tcp-echo 服务的 v1 版本,这样所有的流量都会被路由到 tcp-echo:v1,需要注意的是 VirtualService 对象中配置的是 tcp 协议,而不是 http 协议了,因为我们这里要处理的是一个 TCP 服务,其他方式方法都是一样的。
查看下istio-ingressgateway内容:
[root@master1 istio-1.19.3]#kubectl get svc istio-ingressgateway -nistio-system -oyaml
……
ports:
- name: status-port
nodePort: 31410
port: 15021
protocol: TCP
targetPort: 15021
- name: http2
nodePort: 31666
port: 80
protocol: TCP
targetPort: 8080
- name: https
nodePort: 32213
port: 443
protocol: TCP
targetPort: 8443
- name: tcp
nodePort: 30291 ##
port: 31400 ##
protocol: TCP
targetPort: 31400 ##证明容器里也有一个应用监听31400端口
- name: tls
nodePort: 31787
port: 15443
protocol: TCP
targetPort: 15443
……
[root@master1 istio-1.19.3]#kubectl get po istio-ingressgateway-9c8b9b586-vj44l -nistio-system -oyaml
……
image: docker.io/istio/proxyv2:1.19.3
imagePullPolicy: IfNotPresent
name: istio-proxy
ports:
- containerPort: 15021
protocol: TCP
- containerPort: 8080 #http
protocol: TCP
- containerPort: 8443 #https
protocol: TCP
- containerPort: 31400 #TCP流量
protocol: TCP
- containerPort: 15443
protocol: TCP
- containerPort: 15090
name: http-envoy-prom
protocol: TCP
……
- 我们可以用下面的方式来测试,首先获得 Ingress Gateway 的访问入口地址和端口:
export TCP_INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="tcp")].nodePort}')
export INGRESS_HOST=$(kubectl get po -l istio=ingressgateway -n istio-system -o jsonpath='{.items[0].status.hostIP}')
查看:
echo $TCP_INGRESS_PORT #istio-ingressgateway svc的nodePort(监听器端口),因为这里的SVC是LoadBalancer类型的,因为我们通过NodePort来访问就行。
echo $INGRESS_HOST
[root@master1 istio-1.19.3]#echo $TCP_INGRESS_PORT #svc的nodePort
30291
[root@master1 istio-1.19.3]#echo $INGRESS_HOST
172.29.9.63
- 然后通过 sleep 容器中的
nc命令来发送 TCP 流量:
[root@master1 istio-1.19.3]#export SLEEP=$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})
[root@master1 istio-1.19.3]#echo $SLEEP
sleep-9454cc476-nx668
$ for i in {1..20}; do
kubectl exec "$SLEEP" -c sleep -- sh -c "(date; sleep 1) | nc $INGRESS_HOST $TCP_INGRESS_PORT";
done
one Mon Nov 13 03:23:59 UTC 2023
one Mon Nov 13 03:24:00 UTC 2023
one Mon Nov 13 03:24:01 UTC 2023
# ......
可以看到所有时间戳都有一个前缀 one,说明所有流量都被路由到 tcp-echo 的 v1 版本,当然我们也可以在 v1 版本的 Pod 中查看到相应的日志。
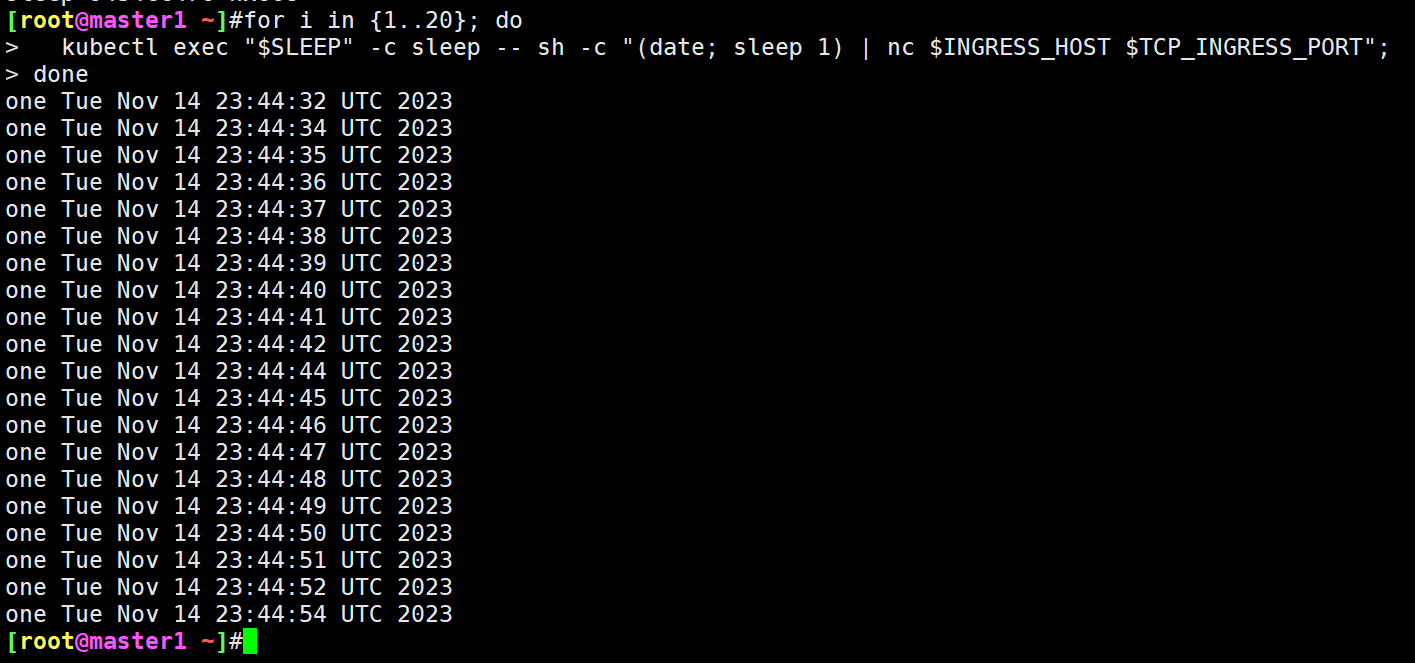
查看v1 版本的 Pod 中查看到相应的日志:
[root@master1 istio-1.19.3]#kubectl logs -f tcp-echo-v1-64c9b4bc95-hc5z7
listening on [::]:9002, prefix: one
listening on [::]:9000, prefix: one
listening on [::]:9001, prefix: one
request: Tue Nov 14 23:44:32 UTC 2023
response: one Tue Nov 14 23:44:32 UTC 2023
request: Tue Nov 14 23:44:34 UTC 2023
response: one Tue Nov 14 23:44:34 UTC 2023
request: Tue Nov 14 23:44:35 UTC 2023
response: one Tue Nov 14 23:44:35 UTC 2023
request: Tue Nov 14 23:44:36 UTC 2023
response: one Tue Nov 14 23:44:36 UTC 2023
request: Tue Nov 14 23:44:37 UTC 2023
……
- 接下来我们将 20% 的 TCP 流量路由到
tcp-echo:v2版本,应用下面的资源清单即可:
kubectl apply -f samples/tcp-echo/tcp-echo-20-v2.yaml
该清单文件内容如下所示:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: tcp-echo
spec:
hosts:
- "*"
gateways:
- tcp-echo-gateway
tcp:
- match:
- port: 31400
route:
- destination:
host: tcp-echo
port:
number: 9000
subset: v1
weight: 80 # 80% 的流量路由到 v1
- destination:
host: tcp-echo
port:
number: 9000
subset: v2
weight: 20 # 20% 的流量路由到 v2
这里我们更新了 VirtualService 对象,将 tcp-echo 服务的 v1 版本和 v2 版本的权重分别设置为 80% 和 20%,这样 20% 的流量就会被路由到 tcp-echo:v2 版本了,这和前面的 HTTP 基于权重的流量拆分是一样的方式。
- 应用成功后,我们再次发送 TCP 流量来验证:
$ export SLEEP=$(kubectl get pod -l app=sleep -o jsonpath={.items..metadata.name})
$ for i in {1..20}; do
kubectl exec "$SLEEP" -c sleep -- sh -c "(date; sleep 1) | nc $INGRESS_HOST $TCP_INGRESS_PORT";
done
one Mon Nov 13 03:29:32 UTC 2023
one Mon Nov 13 03:29:33 UTC 2023
one Mon Nov 13 03:29:34 UTC 2023
one Mon Nov 13 03:29:36 UTC 2023
one Mon Nov 13 03:29:37 UTC 2023
one Mon Nov 13 03:29:38 UTC 2023
one Mon Nov 13 03:29:39 UTC 2023
two Mon Nov 13 03:29:40 UTC 2023
one Mon Nov 13 03:29:41 UTC 2023
one Mon Nov 13 03:29:42 UTC 2023
two Mon Nov 13 03:29:43 UTC 2023
# ......
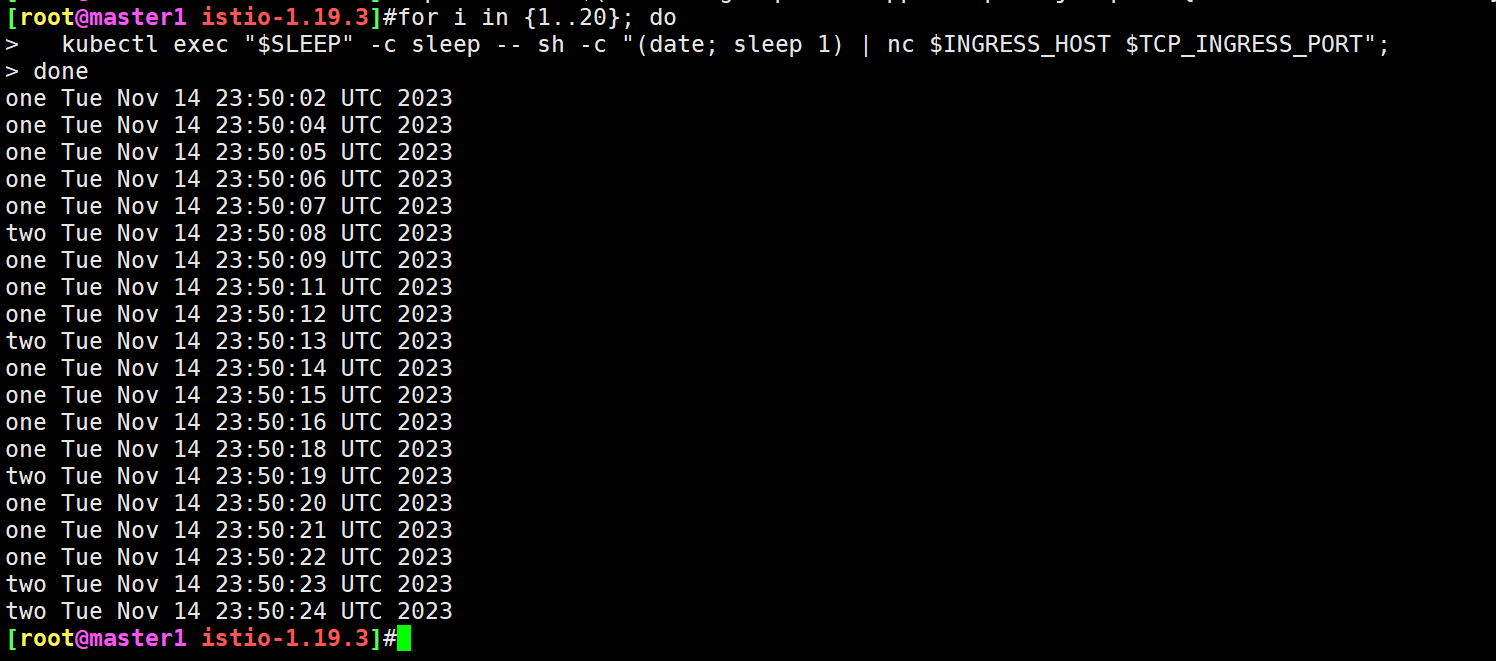
输出结果中大约有 20% 的时间戳带有前缀 two,说明 80% 的 TCP 流量被路由到 tcp-echo 的 v1 版本,而 20% 的流量被路由到 v2 版本,证明我们的 TCP 服务基于权重的流量拆分配置成功了。
- 当然最后我们同样可以去查看下 Envoy Sidecar 的具体配置,注意我们这里是通过 Istio Ingress Gateway 来暴露 TCP 流量的端口的,所以我们这里直接查看
31400端口的监听器配置即可:
$ istioctl proxy-config listeners istio-ingressgateway-9c8b9b586-s6s48 -n istio-system --port 31400 -o yaml
- address:
socketAddress:
address: 0.0.0.0
portValue: 31400
# ......
filterChains:
- filters:
# ......
- name: envoy.filters.network.tcp_proxy
typedConfig:
'@type': type.googleapis.com/envoy.extensions.filters.network.tcp_proxy.v3.TcpProxy
# ......
statPrefix: tcp-echo.default
weightedClusters:
clusters:
- name: outbound|9000|v1|tcp-echo.default.svc.cluster.local
weight: 80
- name: outbound|9000|v2|tcp-echo.default.svc.cluster.local
weight: 20
name: 0.0.0.0_31400
trafficDirection: OUTBOUND
我们可以发现上面的监听器配置下面的过滤器链中直接使用的是一个 envoy.filters.network.tcp_proxy 过滤器,用来处理 TCP 流量,而不是 HTTP 流量了,而且直接在该过滤器下面配置了 weightedClusters 权重集群,用来实现基于权重的流量拆分,可以看到 v1 和 v2 版本的权重分别为 80 和 20,符合我们的预期。
- 最后测试完后可以清理下资源:
kubectl delete -f samples/tcp-echo/tcp-echo-all-v1.yaml
kubectl delete -f samples/sleep/sleep.yaml
kubectl delete -f samples/tcp-echo/tcp-echo-services.yaml
测试结束。😘