PrometheusOperator安装
Prometheus Operator

前面的章节中我们学习了用自定义的方式来对 Kubernetes 集群进行监控,基本上也能够完成监控报警的需求了。但实际上对上 Kubernetes 来说,还有更简单方式来监控报警,那就是 Prometheus Operator。Prometheus Operator 为监控 Kubernetes 资源和 Prometheus 实例的管理提供了简单的定义,简化在 Kubernetes 上部署、管理和运行 Prometheus 和 Alertmanager 集群。
目录
[TOC]
1、介绍
Prometheus Operator 为 Kubernetes 提供了对 Prometheus 机器相关监控组件的本地部署和管理方案,该项目的目的是为了简化和自动化基于 Prometheus 的监控栈配置,主要包括以下几个功能:
- Kubernetes 自定义资源:使用 Kubernetes CRD 来部署和管理 Prometheus、Alertmanager 和相关组件。
- 简化的部署配置:直接通过 Kubernetes 资源清单配置 Prometheus,比如版本、持久化、副本、保留策略等等配置。
- Prometheus 监控目标配置:基于熟知的 Kubernetes 标签查询自动生成监控目标配置,无需学习 Prometheus 特地的配置。
首先我们先来了解下 Prometheus Operator 的架构图:

上图是 Prometheus-Operator 官方提供的架构图,各组件以不同的方式运行在 Kubernetes 集群中,其中 Operator 是最核心的部分,作为一个控制器,他会去创建 Prometheus、ServiceMonitor、AlertManager 以及 PrometheusRule 等 CRD 资源对象,然后会一直 Watch 并维持这些资源对象的状态。
在最新版本的 Operator 中提供了一下几个 CRD 资源对象:
PrometheusAlertmanagerServiceMonitorPodMonitor(例如一些job或者Cronjob是没有service的。)ProbeThanosRulerPrometheusRuleAlertmanagerConfig
Prometheus
该 CRD 声明定义了 Prometheus 期望在 Kubernetes 集群中运行的配置,提供了配置选项来配置副本、持久化、报警实例等。
对于每个 Prometheus CRD 资源,Operator 都会以 StatefulSet 形式在相同的命名空间下部署对应配置的资源,Prometheus Pod 的配置是通过一个包含 Prometheus 配置的名为 <prometheus-name> 的 Secret 对象声明挂载的。
该 CRD 根据标签选择来指定部署的 Prometheus 实例应该覆盖哪些 ServiceMonitors��,然后 Operator 会根据包含的 ServiceMonitors 生成配置,并在包含配置的 Secret 中进行更新。
如果未提供对 ServiceMonitor 的选择,则 Operator 会将 Secret 的管理留给用户,这样就可以提供自定义配置,同时还能享受 Operator 管理 Operator 的设置能力。
Alertmanager
该 CRD 定义了在 Kubernetes 集群中运行的 Alertmanager 的配置,同样提供了多种配置,包括持久化存储。
对于每个 Alertmanager 资源,Operator 都会在相同的命名空间中部署一个对应配置的 StatefulSet,Alertmanager Pods 被配置为包含一个名为 <alertmanager-name> 的 Secret,该 Secret 以 alertmanager.yaml 为 key 的方式保存使用的配置文件。
当有两个或更多配置的副本时,Operator 会在高可用模式下运行 Alertmanager 实例。
ThanosRuler
该 CRD 定义了一个 Thanos Ruler 组件的配置,以方便在 Kubernetes 集群中运行。通过 Thanos Ruler,可以跨多个 Prometheus 实例处理记录和警报规则。
一个 ThanosRuler 实例至少需要一个 queryEndpoint,它指向 Thanos Queriers 或 Prometheus 实例的位置。queryEndpoints 用于配置 Thanos 运行时的 --query 参数,更多信息也可以在 Thanos 文档中找到。
ServiceMonitor
该 CRD 定义了如何监控一组动态的服务,使用标签选择来定义哪些 Service 被选择进行监控。这可以让团队制定一个如何暴露监控指标的规范,然后按照这些规范自动发现新的服务,而无需重新配置。
为了让 Prometheus 监控 Kubernetes 内的任何应用,需要存在一个 Endpoints 对象,Endpoints 对象本质上是 IP 地址的列表,通常 Endpoints 对象是由 Service 对象来自动填充的,Service 对象通过标签选择器匹配 Pod,并将其添加到 Endpoints 对象中。一个 Service 可以暴露一个或多个端口,这些端口由多个 Endpoints 列表支持,这些端点一般情况下都是指向一个 Pod。
Prometheus Operator 引入的这个 ServiceMonitor 对象就会发现这些 Endpoints 对象,并配置 Prometheus 监控这些 Pod。ServiceMonitorSpec 的 endpoints 部分就是用于配置这些 Endpoints 的哪些端口将被 scrape 指标的。
注意:endpoints(小写)是 ServiceMonitor CRD 中的字段,而 Endpoints(大写)是 Kubernetes 的一种对象。
ServiceMonitors 以及被发现的目标都可以来自任何命名空间,这对于允许跨命名空间监控的场景非常重要。使用 PrometheusSpec 的 ServiceMonitorNamespaceSelector,可以限制各自的 Prometheus 服务器选择的 ServiceMonitors 的命名空间。使用 ServiceMonitorSpec 的 namespaceSelector,可以限制 Endpoints 对象被允许从哪些命��名空间中发现,要在所有命名空间中发现目标,namespaceSelector 必须为空:
spec:
namespaceSelector:
any: true
PodMonitor
该 CRD 用于定义如何监控一组动态 pods,使用标签选择来定义哪些 pods 被选择进行监控。同样团队中可以制定一些规范来暴露监控的指标。
Pod 是一个或多个容器的集合,可以在一些端口上暴露 Prometheus 指标。
由 Prometheus Operator 引入的 PodMonitor 对象会发现这些 Pod,并为 Prometheus 服务器生成相关配置,以便监控它们。
PodMonitorSpec 中的 PodMetricsEndpoints 部分,用于配置 Pod 的哪些端口将被 scrape 指标,以及使用哪些参数。
PodMonitors 和发现的目标可以来自任何命名空间,这同样对于允许跨命名空间的监控用例是很重要的。使用 PodMonitorSpec 的 namespaceSelector,可以限制 Pod 被允许发现的命名空间,要在所有命名空间中发现目标,namespaceSelector 必须为空:
spec:
namespaceSelector:
any: true
PodMonitor和ServieMonitor最大的区别就是不需要有对应的 Service。
Probe
黑盒监控相关的。
该 CRD 用于定义如何监控一组 Ingress 和静态目标。除了 target 之外,Probe 对象还需要一个 prober,它是监控的目标并为 Prometheus 提供指标的服务。例如可以通过使用 blackbox-exporter 来提供这个服务。
PrometheusRule
用于配置 Prometheus 的 Rule 规则文件,包括 recording rules 和 alerting,可以自动被 Prometheus 加载。
AlertmanagerConfig
在以前的版本中要配置 Alertmanager 都是通过 Configmap 来完成的,在 v0.43 版本后新增该 CRD,可以将 Alertmanager 的配置分割成不同的子对象进行配置,允许将报警路由到自定义 Receiver 上,并配置抑制规则。
AlertmanagerConfig 可以在命名空间级别上定义,为 Alertmanager 提供一个聚合的配置。这里提供了一个如何使用它的例子。不过需要注意这个 CRD 还不稳定。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是这样比之前手动的方式就方便很多了。
2、安装
💘 实战:Prometheus Operator安装及配置(测试成��功)-2022.8.22
实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.22.2
containerd://1.5.5
实验软件
链接:https://pan.baidu.com/s/1XRN-gfVB0QpLZyr9kz8gkg?pwd=cb3j
提取码:cb3j

2022.8.22-Prometheus Operator-code
前言
kube-prometheus项目
官方网站:
https://prometheus-operator.dev/


kube-prometheus项目
Prometheus Operator项目和kube-prometheus项目的关系类似于Linux发行版和Linux内核之间的关系。


为了使用 Prometheus-Operator,这里我们直接使用 kube-prometheus 这个项目来进行安装,该项目和 Prometheus-Operator 的区别就类似于 Linux 内核和 CentOS/Ubuntu 这些发行版的关系,真正起作用的是 Operator 去实现的,而 kube-prometheus 只是利用 Operator 编写了一系列常用的监控资源清单。不过需要注意 Kubernetes 版本和 kube-prometheus 的兼容:
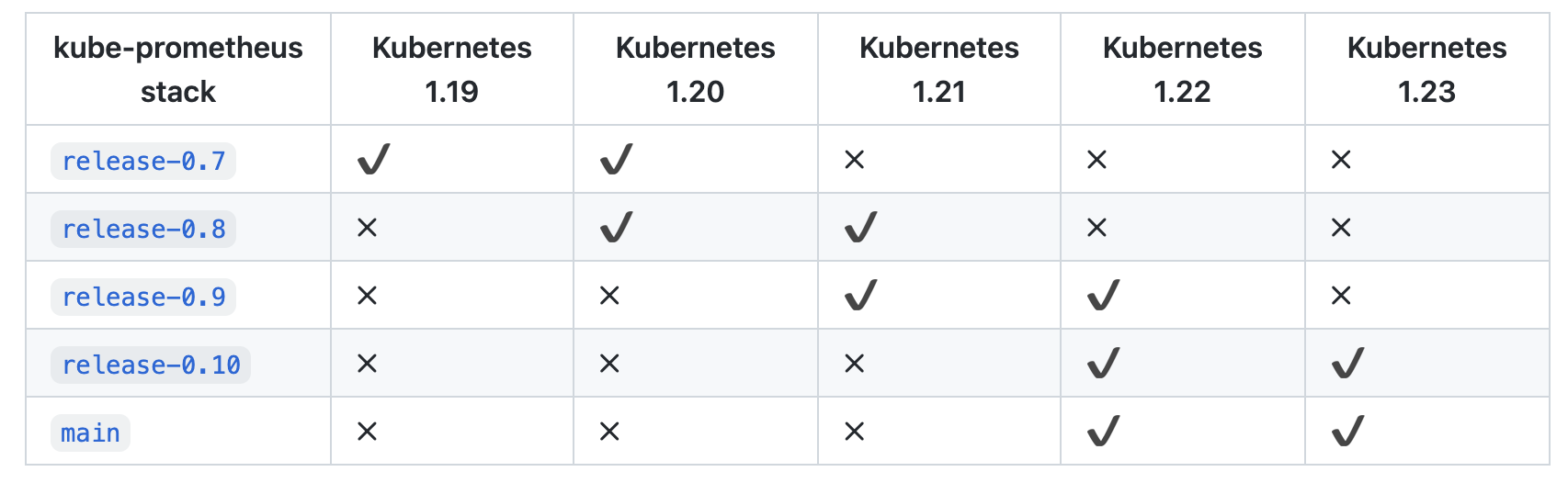
我们可以直接使用 kube-prometheus 的 Helm Charts 来进行快速安装,也可以直接手动安装(本次使用手动安装)。
1.clone 项目代码
- 首先 clone 项目代码,我们这里直接使用默认的
main分支即可:
$ git clone https://github.com/prometheus-operator/kube-prometheus.git
$ cd kube-prometheus

2.创建需要的命名��空间和 CRDs
- 首先创建需要的命名空间和 CRDs,等待它们可用后再创建其余资源:
[root@master1 kube-prometheus]#kubectl apply -f manifests/setup
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
The CustomResourceDefinition "prometheuses.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
namespace/monitoring created
- 可以看到安装过程中会提示
Too long: must have at most 262144 bytes,只需��要将kubectl apply改成kubectl create即可:
[root@master1 kube-prometheus]#kubectl create -f manifests/setup
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
Error from server (AlreadyExists): error when creating "manifests/setup/0alertmanagerConfigCustomResourceDefinition.yaml": customresourcedefinitions.apiextensions.k8s.io "alertmanagerconfigs.monitoring.coreos.com" already exists
Error from server (AlreadyExists): error when creating "manifests/setup/0alertmanagerCustomResourceDefinition.yaml": customresourcedefinitions.apiextensions.k8s.io "alertmanagers.monitoring.coreos.com"
already exists
Error from server (AlreadyExists): error when creating "manifests/setup/0podmonitorCustomResourceDefinition.yaml": customresourcedefinitions.apiextensions.k8s.io "podmonitors.monitoring.coreos.com" already exists
Error from server (AlreadyExists): error when creating "manifests/setup/0probeCustomResourceDefinition.yaml": customresourcedefinitions.apiextensions.k8s.io "probes.monitoring.coreos.com" already existsError from server (AlreadyExists): error when creating "manifests/setup/0prometheusruleCustomResourceDefinition.yaml": customresourcedefinitions.apiextensions.k8s.io "prometheusrules.monitoring.coreos.com" already exists
Error from server (AlreadyExists): error when creating "manifests/setup/0servicemonitorCustomResourceDefinition.yaml": customresourcedefinitions.apiextensions.k8s.io "servicemonitors.monitoring.coreos.com" already exists
Error from server (AlreadyExists): error when creating "manifests/setup/0thanosrulerCustomResourceDefinition.yaml": customresourcedefinitions.apiextensions.k8s.io "thanosrulers.monitoring.coreos.com" already exists
Error from server (AlreadyExists): error when creating "manifests/setup/namespace.yaml": namespaces "monitoring" already exists
[root@master1 kube-prometheus]#kubectl get crd |grep coreos
alertmanagerconfigs.monitoring.coreos.com 2022-08-20T13:25:15Z
alertmanagers.monitoring.coreos.com 2022-08-20T13:25:15Z
podmonitors.monitoring.coreos.com 2022-08-20T13:25:15Z
probes.monitoring.coreos.com 2022-08-20T13:25:15Z
prometheuses.monitoring.coreos.com 2022-08-20T13:27:31Z
prometheusrules.monitoring.coreos.com 2022-08-20T13:25:16Z
servicemonitors.monitoring.coreos.com 2022-08-20T13:25:16Z
thanosrulers.monitoring.coreos.com 2022-08-20T13:25:16Z
[root@master1 kube-prometheus]#
这会创建一个名为 monitoring 的命名空间,以及相关的 CRD 资源对象声明。
3.部署Operator 的资源清单
前面章节中我们讲解过 CRD 和 Operator 的使用,当我们声明完 CRD 过后,就可以来自定义资源清单了,但是要让我们声明的自定义资源对象生效就需要安装对应的 Operator 控制器,在 manifests 目录下面就包含了 Operator 的资源清单以及各种监控对象声明,比如 Prometheus、Alertmanager 等,直接应用即可:
不过需要注意有一些资源的镜像来自于 k8s.gcr.io,如果不能正常拉取,则可以将镜像替换成可拉取的:
prometheusAdapter-deployment.yaml:将image: k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1替换为cnych/prometheus-adapter:v0.9.1kubeStateMetrics-deployment.yaml:将image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.4.2替换为cnych/kube-state-metrics:v2.4.2
这里需要注意下:
老师当时下载的代码,这里的镜像版本是image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.4.2
但是,自己当前做实验时的镜像版本已经发生改变了:k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0

那么,现在要么做镜像转存,要么修改为老师的镜像地址。
如下有涉及到版本号:
还是直接修改为老师的镜像版本吧(转存镜像优点麻烦。。。。)

这个镜像版本没变:……

- 这里修改下镜像地址:
[root@master1 manifests]#vim kubeStateMetrics-deployment.yaml
[root@master1 manifests]#vim prometheusAdapter-deployment.yaml

- 替换完成后直接部署:
[root@master1 kube-prometheus]#kubectl apply -f manifests/
- 这会自动安装 prometheus-operator、node-exporter、kube-state-metrics、grafana、prometheus-adapter 以及 prometheus 和 alertmanager 等大量组件,如果没成功可以多次执行上面的安装命令。
[root@master1 ~]#kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 17h
alertmanager-main-1 2/2 Running 0 17h
alertmanager-main-2 2/2 Running 0 17h
blackbox-exporter-6d4899c9f9-f79r6 3/3 Running 0 17h
grafana-79f9667c9d-xvpxc 1/1 Running 1 (17h ago) 17h
kube-state-metrics-74758dc466-d7qkc 3/3 Running 0 17h
node-exporter-5wngr 2/2 Running 2 (17h ago) 17h
node-exporter-nb8cb 2/2 Running 2 (17h ago) 17h
node-exporter-r5ts6 2/2 Running 2 (17h ago) 17h
prometheus-adapter-6fd94587c9-66sk7 1/1 Running 1 (17h ago) 17h
prometheus-adapter-6fd94587c9-r584d 1/1 Running 1 (17h ago) 17h
prometheus-k8s-0 2/2 Running 0 17h
prometheus-k8s-1 2/2 Running 0 17h
prometheus-operator-64c9fd99b-gsxc6 2/2 Running 2 (17h ago) 17h
[root@master1 ~]#kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.107.243.156 <none> 9093/TCP,8080/TCP 17h
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 17h
blackbox-exporter ClusterIP 10.100.8.148 <none> 9115/TCP,19115/TCP 17h
grafana ClusterIP 10.106.234.176 <none> 3000/TCP 17h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 17h
node-exporter ClusterIP None <none> 9100/TCP 17h
prometheus-adapter ClusterIP 10.97.176.201 <none> 443/TCP 17h
prometheus-k8s ClusterIP 10.97.33.126 <none> 9090/TCP,8080/TCP 17h
prometheus-operated ClusterIP None <none> 9090/TCP 17h
prometheus-operator ClusterIP None <none> 8443/TCP 17h
可以看到上面针对 grafana、alertmanager 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,当然如果我们想要在外网访问这两个服务的话可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service。
- 我们这里为了简单,直接使用 NodePort 类型的服务即可,编辑
grafana、alertmanager-main和prometheus-k8s这 3 个 Service,将服务类型更改为 NodePort:
# 将 type: ClusterIP 更改为 type: NodePort
$ kubectl edit svc grafana -n monitoring
$ kubectl edit svc alertmanager-main -n monitoring
$ kubectl edit svc prometheus-k8s -n monitoring
[root@master1 ~]#kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.107.243.156 <none> 9093:30369/TCP,8080:31793/TCP 18h
grafana NodePort 10.106.234.176 <none> 3000:31242/TCP 18h
prometheus-k8s NodePort 10.97.33.126 <none> 9090:32011/TCP,8080:30589/TCP 18h
……
- 更改完成后,我们就可以通过上面的 NodePort 去访问对应的服务了,比如查看 prometheus 的服务发现页面:

可以看到已经监控上了很多指标数据了。
- 需要注意的地方
上面我们可以看到 Prometheus 是两个副本,我们这里通过 Service 去访问,按正常来说请求是会去轮询访问后端的两个 Prometheus 实例的,但实际上我们这里访问的时候始终是路由到后端的一个实例上去,因为这里的 Service 在创建的时候添加了 sessionAffinity: ClientIP 这样的属性,会根据 ClientIP 来做 session 亲和性,所以我们不用担心请求会到不同的副本上去:
[root@master1 ~]#kubectl get po -nmonitoring
NAME READY STATUS RESTARTS AGE
……
prometheus-k8s-0 2/2 Running 0 18h
prometheus-k8s-1 2/2 Running 0 18h
[root@master1 ~]#kubectl get svc prometheus-k8s -nmonitoring -oyaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.35.0
name: prometheus-k8s
namespace: monitoring
spec:
ports:
- name: web
port: 9090
targetPort: web
- name: reloader-web
port: 8080
targetPort: reloader-web
type: NodePort
selector:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: ClientIP
为什么会担心请求会到不同的副本上去呢?正常多副本应该是看成高可用的常用方案,理论上来说不同副本本地的数据是一致的,但是需要注意的是 Prometheus 的主动 Pull 拉取监控指标的方式,由于抓取时间不能完全一致,即使一致也不一定就能保证网络没什么问题,所以最终不同副本下存储的数据很大可能是不一样的,所以这里我们配置了 session 亲和性,可以保证我们在访问数据的时候始终是一致的。
4.配置
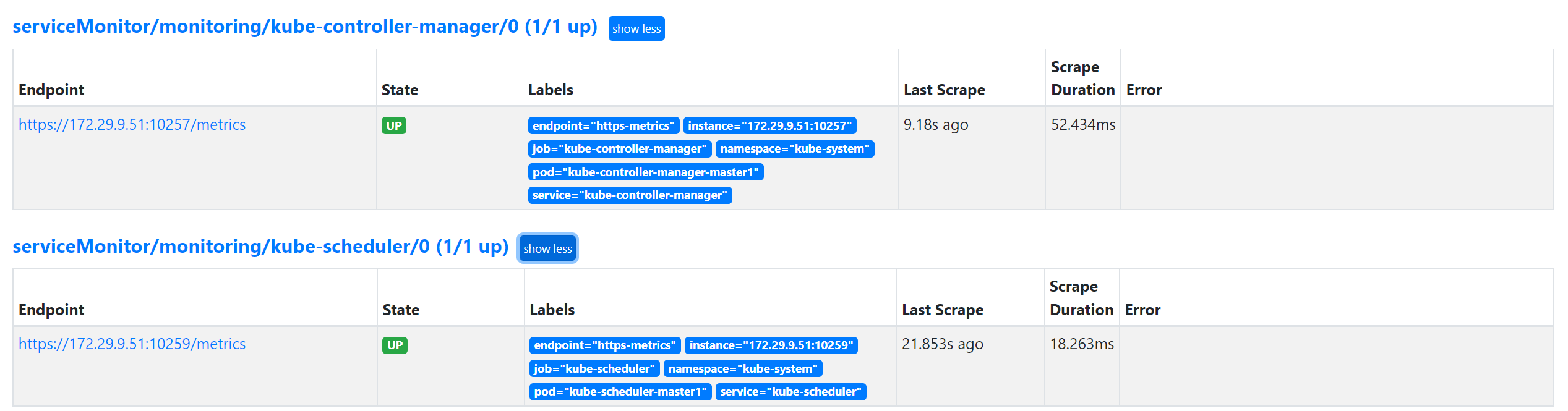
我们可以看到上面的监控指标大部分的配置都是正常的,只有两三个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件。

这其实就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义,manifests/kubernetesControlPlane-serviceMonitorKubeScheduler.yaml:

# kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
app.kubernetes.io/part-of: kube-prometheus
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s # 每30s获取一次信息
port: https-metrics # 对应 service 的端口名
scheme: https # 注意是使用 https 协议
tlsConfig:
insecureSkipVerify: true # 跳过安全校验
jobLabel: app.kubernetes.io/name # 用于从中检索任务名称的标签
namespaceSelector: # 表示去匹配某一命名空间中的 Service,如果想从所有的namespace中匹配用any:true
matchNames:
- kube-system
selector: # 匹配的 Service 的 labels,如果使用 mathLabels,则下面的所有标签都匹配时才会匹配该 service,如果使用 matchExpressions,则至少匹配一个标签的 service 都会被选择
matchLabels:
app.kubernetes.io/name: kube-scheduler
上面是一个典型的 ServiceMonitor 资源对象的声明方式,通过 selector.matchLabels 在 kube-system 这个命名空间下面匹配具有 app.kubernetes.io/name=kube-scheduler 这样的 Service,但是我们系统中根本就没有对应的 Service:
[root@master1 ~]#kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-scheduler
No resources found in kube-system namespace.
- 所以我们需要去创建一个对应的 Service 对象,才能与
ServiceMonitor进行关联:
#[root@master1 kube-prometheus]#vim manifests/kubernetesControlPlane-serviceMonitorKubeScheduler.yaml #添加如下内容
……
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels: # 必须和上面的 ServiceMonitor 下面的 matchLabels 保持一致
app.kubernetes.io/name: kube-scheduler
spec:
selector:
component: kube-scheduler
ports:
- name: https-metrics
port: 10259
targetPort: 10259 # 需要注意现在版本默认的安全端口是10259
其中最重要的是上面 labels 和 selector 部分,labels 区域的配置必须和我们上面的 ServiceMonitor 对象中的 selector 保持一致,selector 下面配置的是 component=kube-scheduler,为什么会是这个 label 标签呢,我们可以去 describe 下 kube-scheduler 这个 Pod:
$ kubectl describe pod kube-scheduler-master1 -n kube-system
Name: kube-scheduler-master1
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: master1/192.168.0.106
Start Time: Tue, 17 May 2022 15:15:43 +0800
Labels: component=kube-scheduler
tier=control-plane
......
我们可以看到这个 Pod 具有 component=kube-scheduler 和 tier=control-plane 这两个标签,而前面这个标签具有更唯一的特性,所以使用前面这个标签较好,这样上面创建的 Service 就可以和我们的 Pod 进行关联了。
- 直接应用即可:
$ kubectl apply -f manifests/kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
$ kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-scheduler
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-scheduler ClusterIP 10.103.236.75 <none> 10259/TCP 5m9s
- 创建完成后,隔一小会儿后去 Prometheus 页面上查看 targets 下面 kube-scheduler 已经有采集的目标了,但是报了
connect: connection refused这样的错误:

这是因为 kube-scheduler 启动的时候默认绑定的是 127.0.0.1 地址,所以要通过 IP 地址去访问就被拒绝了,我们可以查看 master 节点上的静态 Pod 资源清单来确认这一点:
# /etc/kubernetes/manifests/kube-scheduler.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-scheduler
tier: control-plane
name: kube-scheduler
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1 # 绑定了127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
- --port=0 # 如果为0,则不提供 HTTP 服务,--secure-port 默认值:10259,通过身份验证和授权为 HTTPS 服务的端口,如果为 0,则不提供 HTTPS。
......
- 我们可以直接将上面的
--bind-address=127.0.0.1更改为--bind-address=0.0.0.0即可,更改后 kube-scheduler 会自动重启,重启完成后再去查看 Prometheus 上面的采集目标就正常了。
#vim /etc/kubernetes/manifests/kube-scheduler.yaml
……
- --bind-address=0.0.0.0
#查看
[root@master1 kube-prometheus]#kubectl get po -nkube-system
NAME READY STATUS RESTARTS AGE
……
kube-scheduler-master1 1/1 Running 0 27s
验证:

- 可以用同样的方式来修复下 kube-controller-manager 组件的监控,创建一个如下所示的 Service 对象,只是端口改成 10257:
# vim manifests/kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: https-metrics
port: 10257
targetPort: 10257 # controller-manager 的安全端口为10257
#更新
$ kubectl apply -f manifests/kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
然后将 kube-controller-manager 静态 Pod 的资源清单文件中的参数 --bind-address=127.0.0.1 更改为 --bind-address=0.0.0.0。
- 上面的监控数据配置完成后,我们就可以去查看下 Grafana 下面的监控图表了,同样使用上面的 NodePort 访问即可,第一次登录使用
admin:admin登录即可,进入首页后,我们可以发现其实 Grafana 已经有很多配置好的监控图表了。
- 😢 额:我的环境这里又出现了grafna里无法直接访问svc,需要使用nodeIP:NodePort才行。
默认的配置:

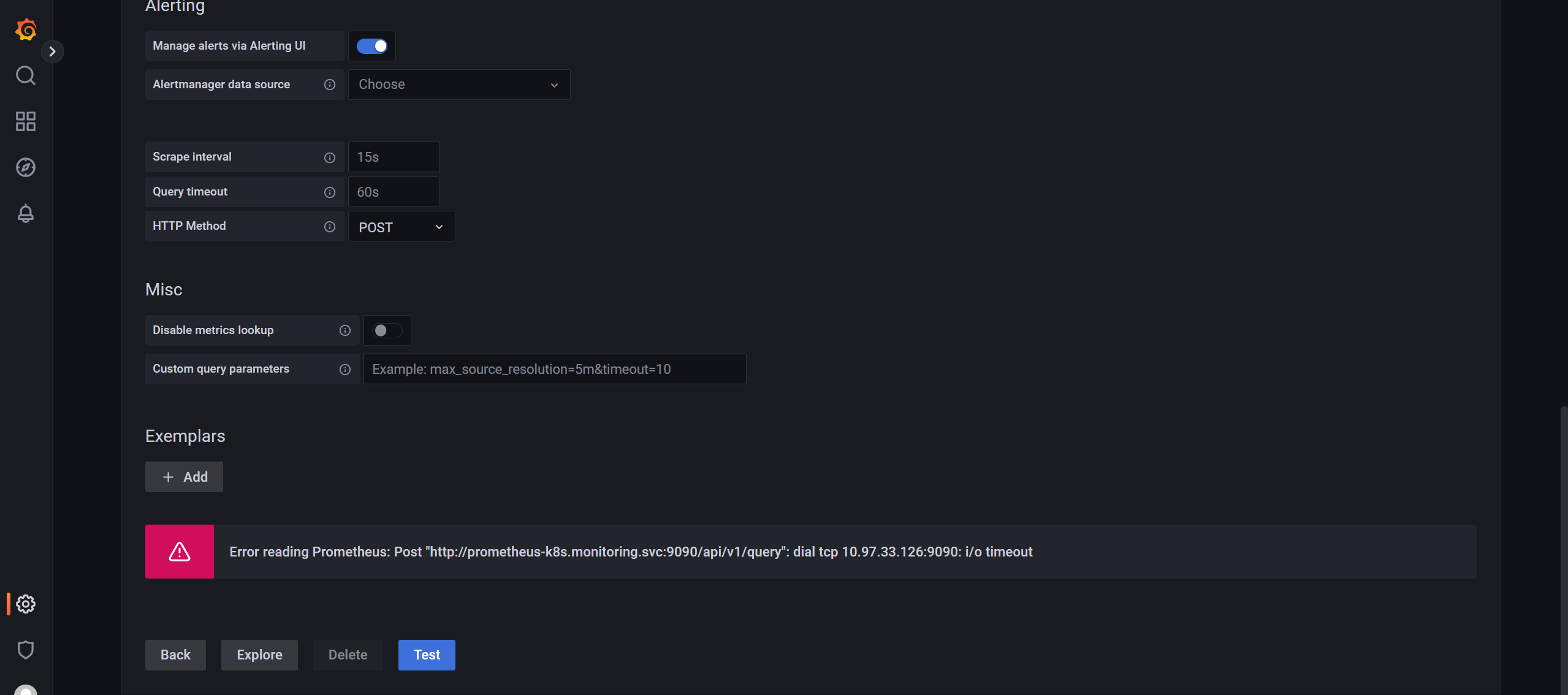
修改后配置:
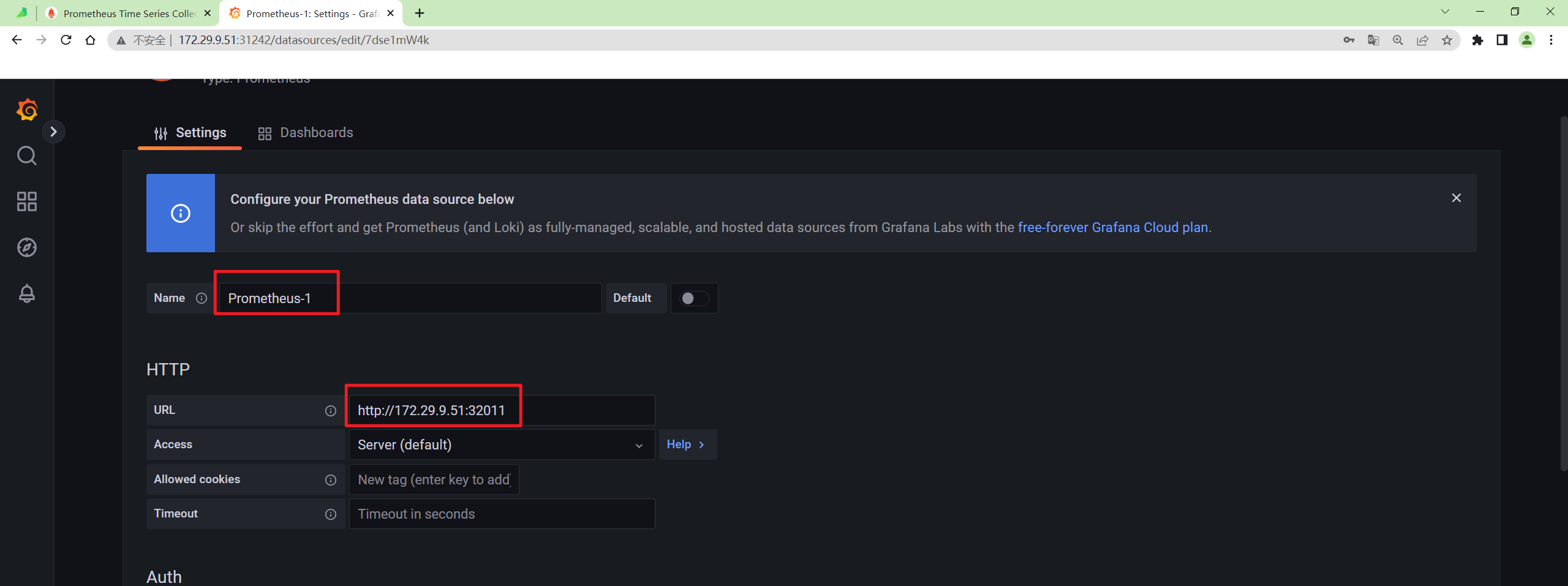

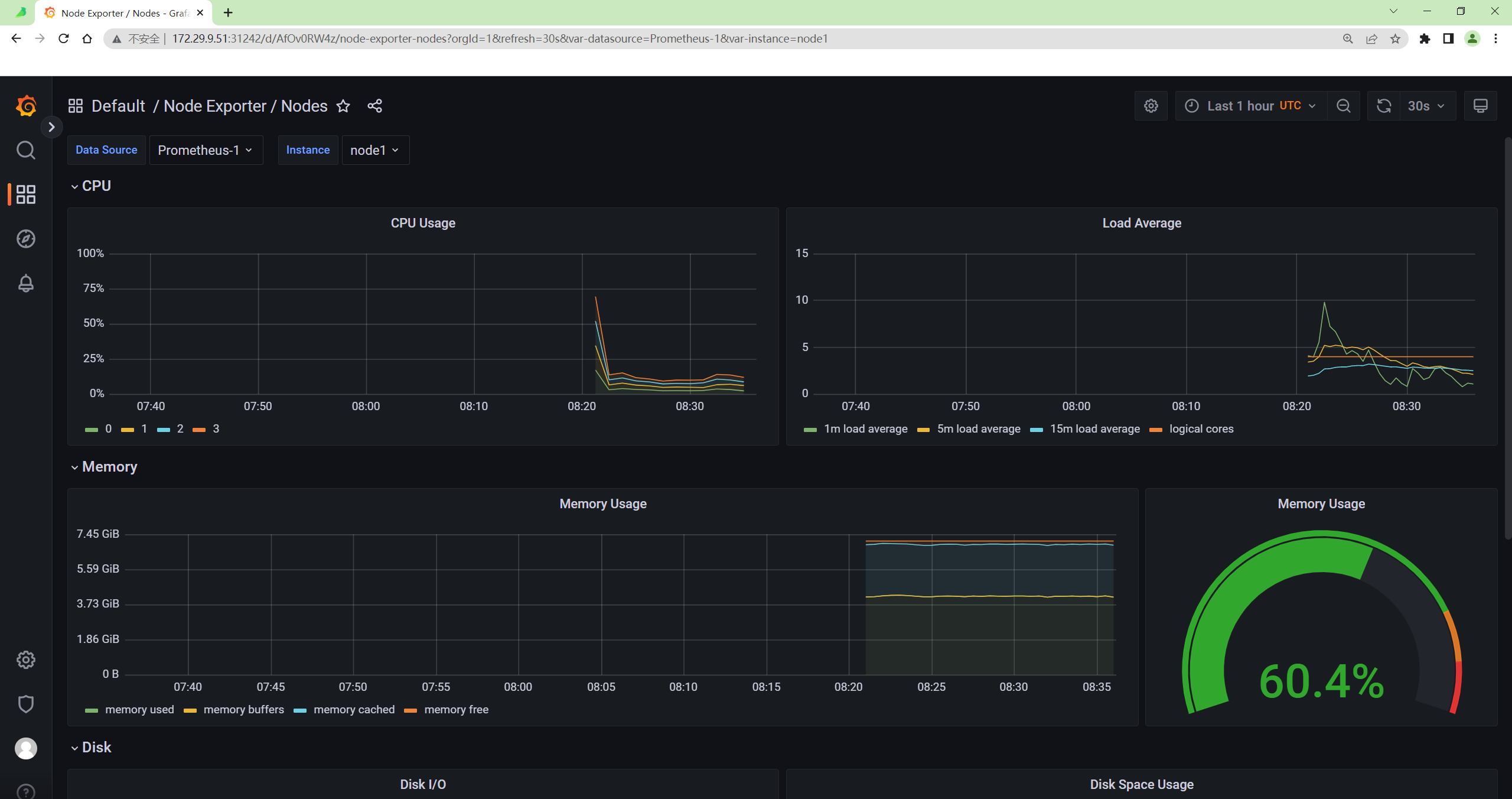
奇怪呀:后面默认的数据源又可以访问了呢……(真的是好奇怪呢)
2022年9月4日

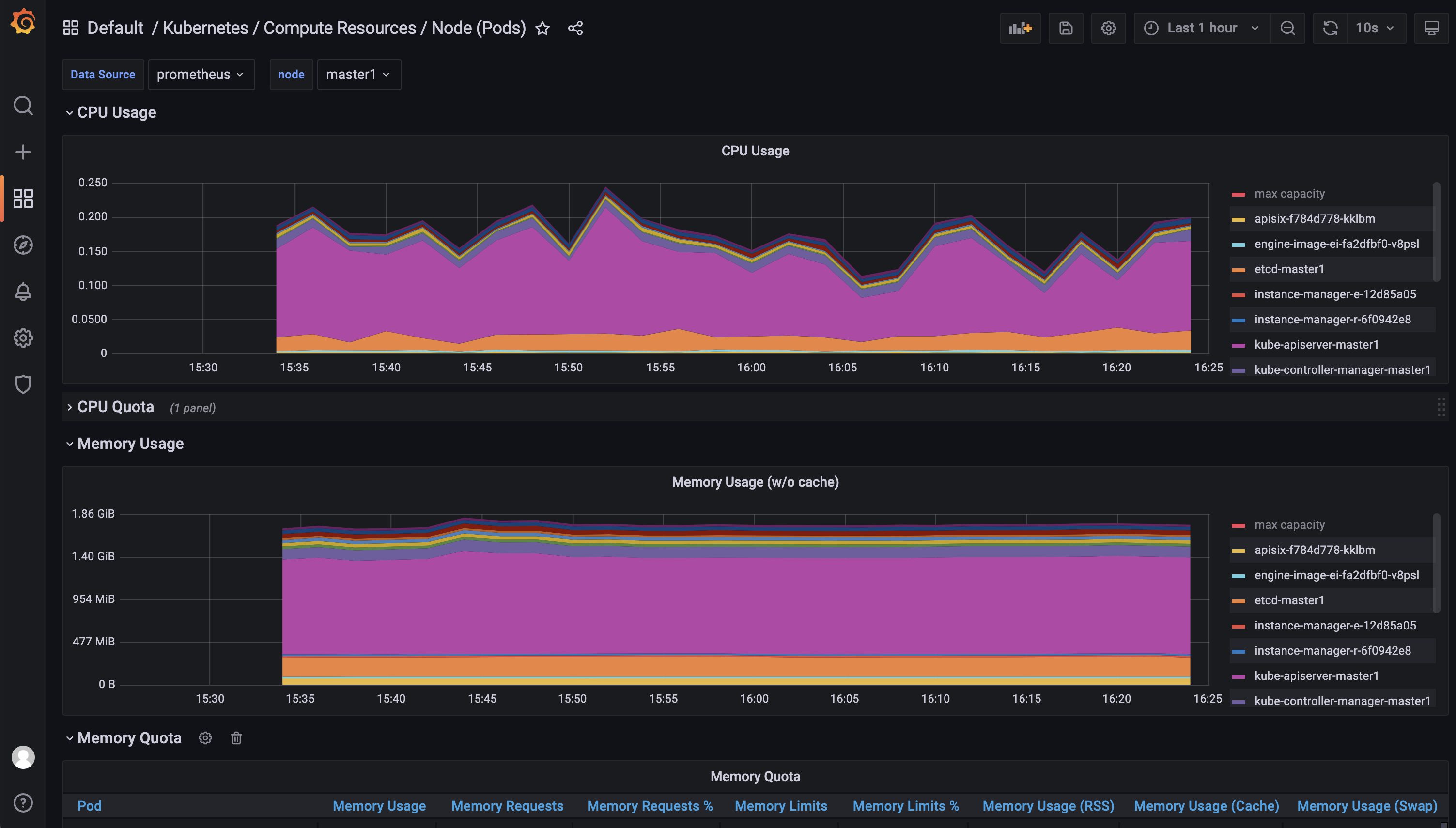
- 我们可以随便选择一个 Dashboard 查看监控图表信息。
接下来我们再来学习如何完全自定义一个 ServiceMonitor 以及其他的相关配置。
5.清理 Prometheus-Operator
如果要清理 Prometheus-Operator,可以直接删除对应的资源清单即可:
$ kubectl delete -f manifests/
$ kubectl delete -f manifests/setup/
安装结束。😘
注意事项
🍀 部署Operator 的资源清单,pod没起来问题分析
- 虚机还吃cpu吗??
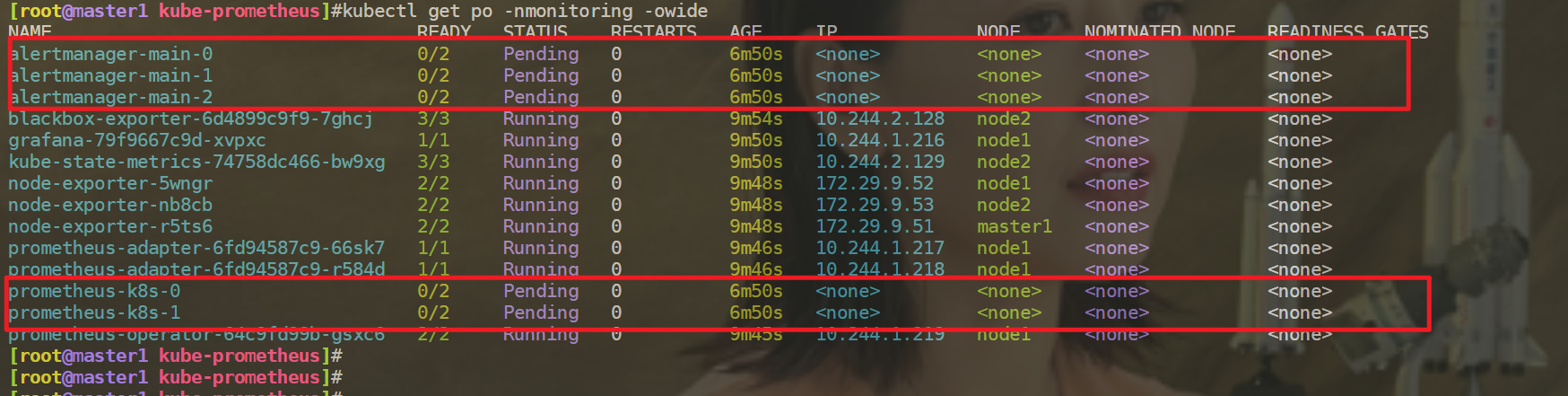


-
当时给这3个节点虚机热扩容到4c了。
-
看下node节点cpu�监控:
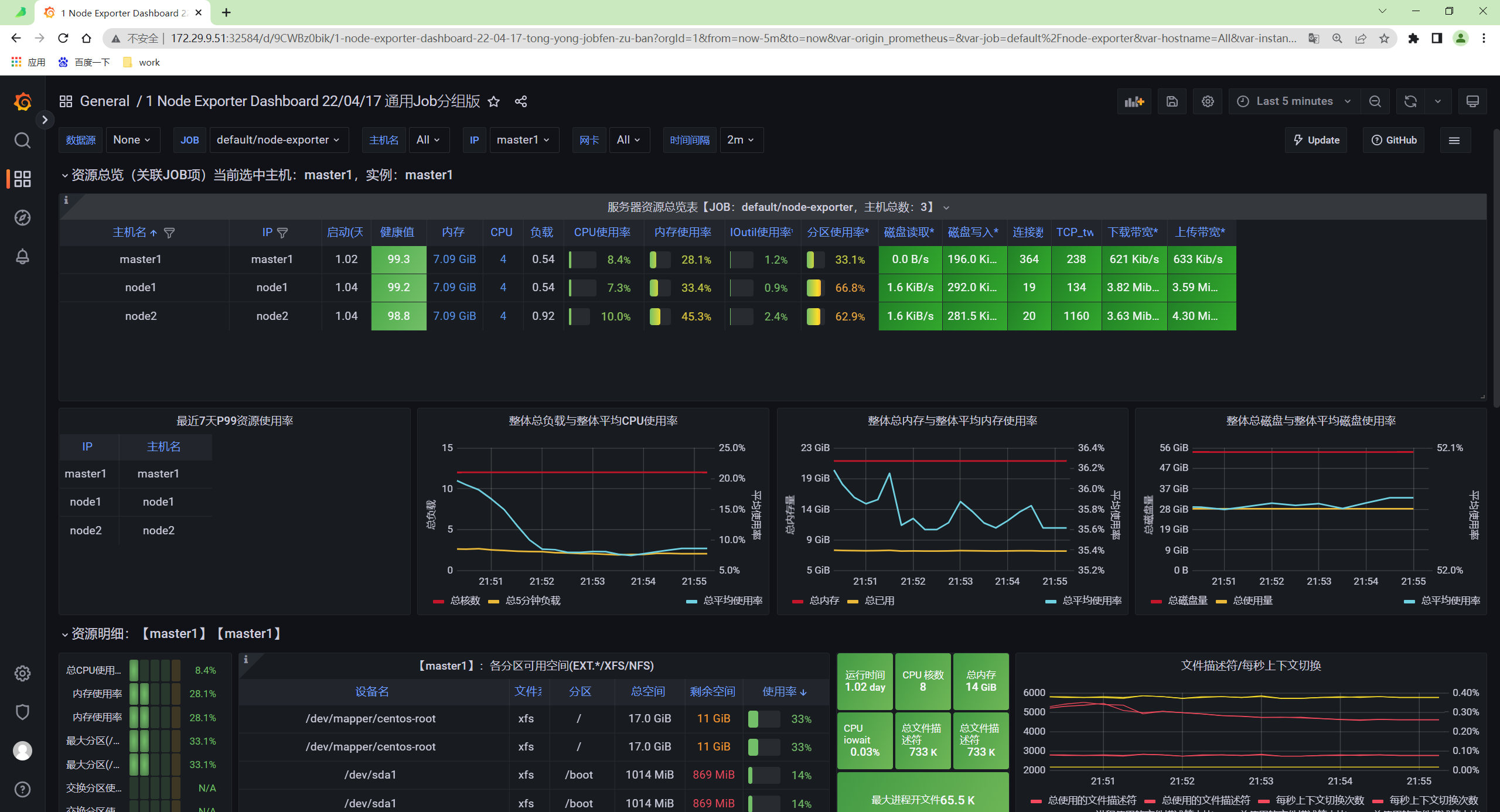
- 查看当前宿主机cpu核数:
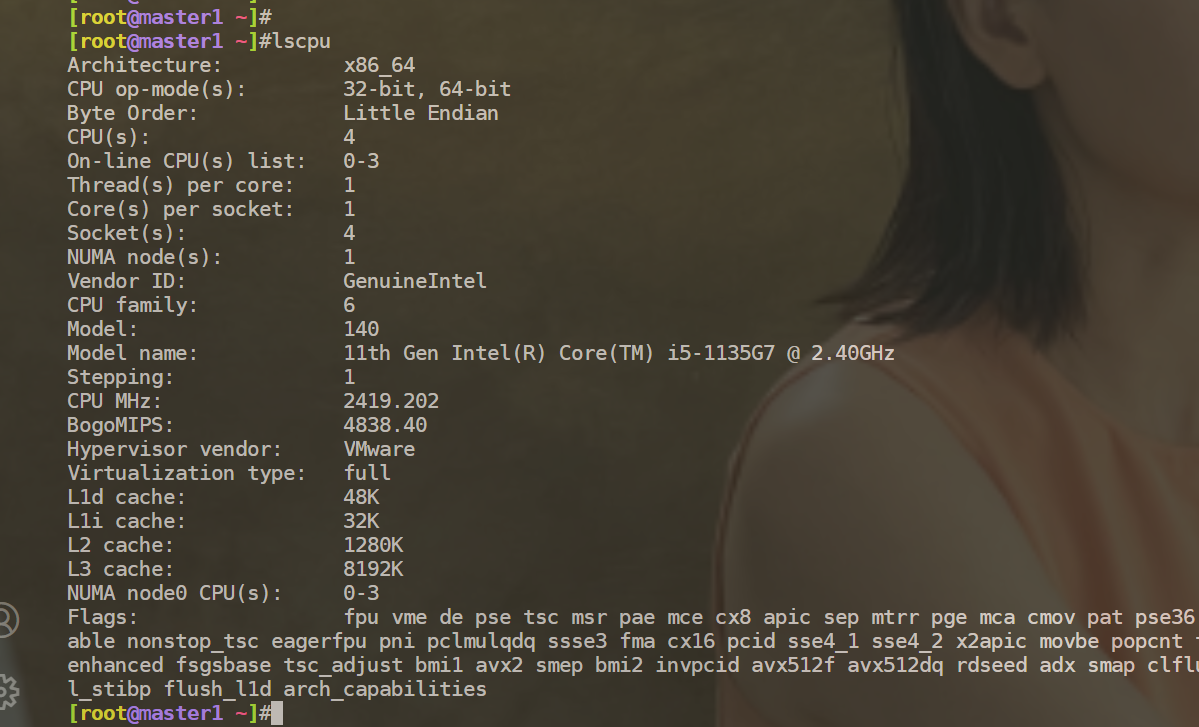

- 当前笔记本cpu总核数:
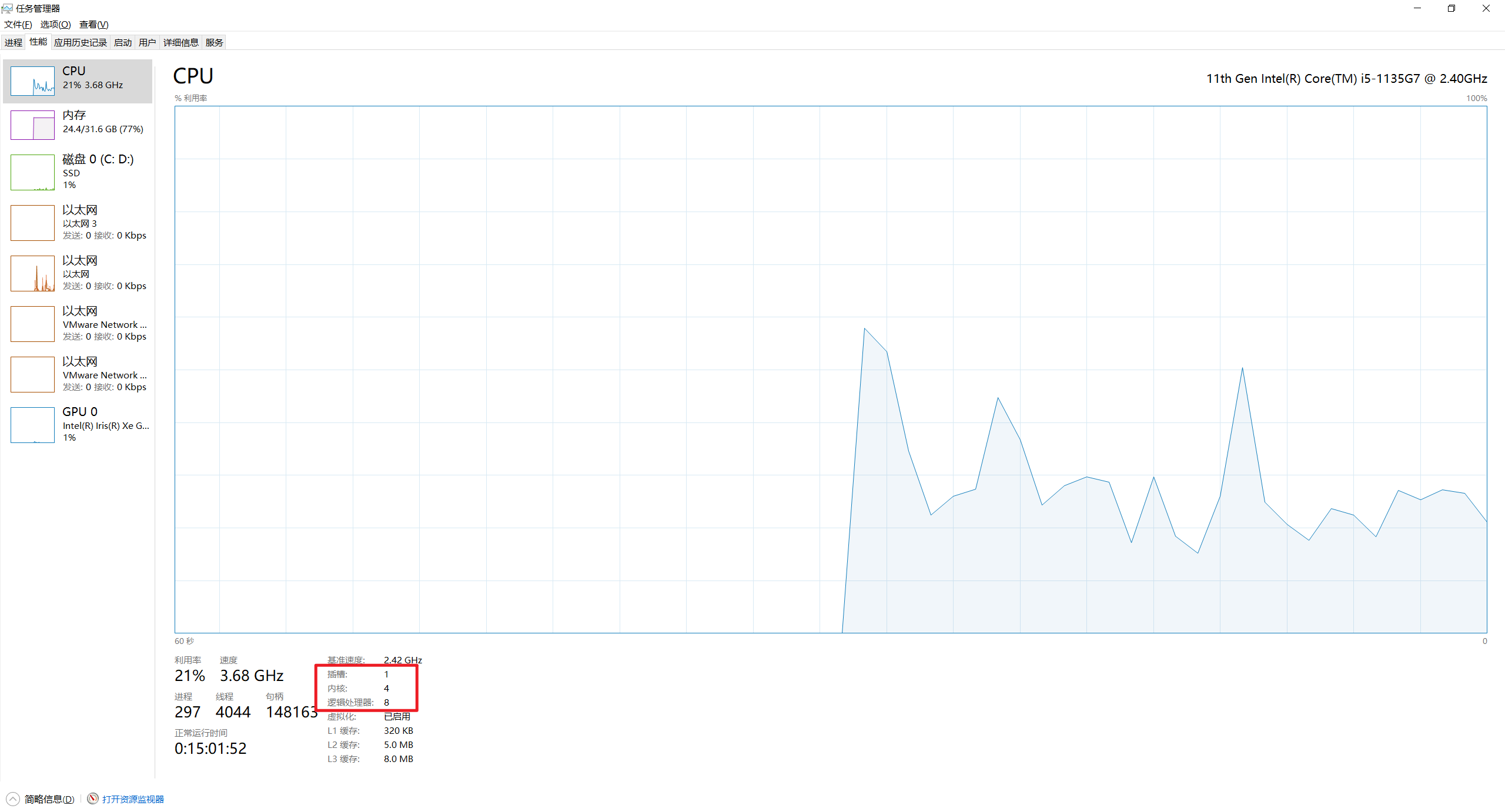
- 查看资源清单资源需求:



-
查看节点资源使用情况
-
最后,重启了下节点就好了。。。。。
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421

🍀 博客
🍀 知乎
https://www.zhihu.com/people/foryouone
🍀 语雀
https://www.yuque.com/books/share/34a34d43-b80d-47f7-972e-24a888a8fc5e?# 《云笔记最佳实践》

最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!

1